本篇围绕MySQL数据库的底层存储模型、列类型来聊聊数据库表设计及建模中要注意的事项,剖析最根源的底层物理存储文件,用最真实的数据剖析来证明和解答开发过程中的疑惑。
在一些技术谈资、面试沟通过程中,MySQL特别是我们常用的Innodb存储引擎,是非常高频的话题点,而现实中不难发现,很多朋友都浅尝辄止,只能“照本宣科”被动背诵一些概念,遗憾的是这并不足以让我们“精通”。究其主要原因还是因为物理存储文件的结构过于复杂,它的“可观测性”并不友好,并且,对于一般的软件开发者而言,与数据库的交互窗口更多聚焦在数据库工具界面,鲜有机会接触到物理存储内部,浮于概念化。
本篇的目的就是解开MySQL中Innodb的神秘面纱直击第一现场来感受真实的数据存储,分析建模设计过程中列类型的影响,帮助更好地做好“精挑细选”。
探查真实的物理存储
关于Innodb部分的学习推荐如下资料入手和探究:
MySQL官方文档
MySQL技术内幕-Innodb存储引擎
Innodb Ruby(Innodb存储文件解析工具)
innodb文件分析工具innodb_ruby使用操作
Innodb物理存储层层剥开
数据库文件存储位置
MySQL把我们的数据存储在哪里了?可以在命令行或数据库交互界面输入show variables like 'datadir'得到答案,即数据库文件存储位置。
-- 如:
show variables like 'datadir'
| variable_name | value |
|---|---|
| datadir | /usr/local/mysql/data/ |
我们再来创建一个数据库,取名为test,如下:
create database test;
创建库后,我们在/usr/local/mysql/data/路径下得到一个名为test的文件夹,即新数据库空间存储路径,会用来存储该数据库的所有信息。
我们再来创建一张测试表,也取名为test,如下:
CREATE TABLE `test` (
`col_1` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`col_1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
创建表后,我们在/usr/local/mysql/data/test路径下得到
test.frm、test.ibd两个文件,frm格式文件是MySQL架构层对于表结构定义的文件,与具体的存储引擎无关,而ibd文件则是Innodb存储引擎独有的,表结构选择该引擎后会以该格式文件进行物理存储,下面我们针对ibd文件进行深入分析。
ibd文件层层分解
对于一个ibd文件而言,也是有层次、有组织结构的。整体上它是一个独立的表空间,只为一张表而服务(一般会这样配置)。
从整体到具体、从大到小层层分解的话,可以描述为表空间(tablespace)、段(segment)、区(extent)、页(page),会从抽象到具体,从逻辑到现实,接近我们事实数据的部分。
💁 通俗解释:
一般而言,表空间(tablespace)、段(segment)、区(extent)是层次结构中组织数据的抽象概念,是为层级服务的,像是学校、年级、班级的概念。
页(page)才是真实存储和控制业务数据的原子结构,像是老师、学生的个体,每一个个体的信息都存储为行数据(Row)。
| 概念 | 解释 | 作用 |
|---|---|---|
| 表空间(tablespace) | ibd文件最顶层概念 | 存储分层结构组织 |
| 段(segment) | 表空间(tablespace)的下一层区(extent)的上一层 | 存储分层结构组织 |
| 区(extent) | 段(segment)的下一层页(page)的上一层 | 存储分层结构组织 |
| 页(page) | ibd最底层、最原子概念 | 真实存储数据的组织结构 |
对于数据库的使用者而言更关注行数据(Row),而对于数据库,特别是Innodb存储引擎本身除了存储需求支撑,还要考虑更多特性的能力支持,如事务、索引等,功能支持来源于数据存储的结构铺垫,下面我们借助Innodb Ruby工具来层层拆解和分析ibd存储文件看看真实结构的形态。
以区域(extent) 视角,查看test表空间区域快照
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# space-extents-illustrate 以表空间extent段视角生成快照信息
innodb_space -s ibdata1 -T test/test space-extents-illustrate

可以看到,在extent视角下当前表空间中一共有6个Page,具体解读如下:
| Page Type(页类型) | Pages(页数量) | Ratio(占比) | 备注 |
|---|---|---|---|
| System | 3 | 50.00% | 系统页 |
| Index 50 | 1 | 16.67% | 索引页,也就是我们常说的聚簇索引的一部分,它是我们熟悉的B+Tree的叶子结点,数据都是以此索引进行聚合,由于此时是刚建表的阶段没有数据填入,目前这棵树仅有一个节点 |
| Free space | 2 | 33.33% | 空闲空间,链表数据结构,当一条记录被删除后,该空间会被加入到空闲链表中 |
以页(page) 视角,查看test表空间的页类型信息
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# space-page-type-summary 以表空间页类型Page Type视角生成快照信息
innodb_space -s ibdata1 -T test/test space-page-type-summary

可以看到,在Page视角下,当前表空间中也是6个Page,具体解读如下:
Page Type页类型枚举可参考Innodb页类型,系统表空间、用户表空间对于页类型的使用是不同的,当前都是围绕用户表空间进行演示和分析。
| type(页类型) | count(数量) | percent(占比) | description(描述) | 页索引 | 备注 |
|---|---|---|---|---|---|
| FSP_HDR | 1 | 16.67% | 即File Space Header,文件空间头 | Page-0 | extent视图下属于System一部分 |
| IBUF_BITMAP | 1 | 16.67% | 即Insert Buffer位图 | Page-1 | extent视图下属于System一部分 |
| INODE | 1 | 16.67% | Segment节点 | Page-2 | extent视图下属于System一部分 |
| INDEX | 1 | 16.67% | 索引节点,B+Tree结构 | Page-3 | extent视图下属于index一部分 |
| ALLOCATED | 2 | 33.33% | 最新分配的页 | Page-4、Page-5 | extent视图下属于free space一部分 |
剖析Page页结构核心
经过上述Extent、Page视角拆解,我们已经推进到Page层面,Page页类型根据不同功能提供了具体的内部结构进行支撑,这里我们着重分析和业务数据存储息息相关的Index Page页类型,即构建聚簇索引的Page内部结构。
查看Index Page的内部结构
更多可参考Innodb数据页结构
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# -p 指定页,后面3是页的索引序号,从0开始,这里指定3是因为Page索引3的位置是Index Page,也就是聚簇索引所在页,可结合上述表述分析得到
# page-illustrate 以表空间指定页Page视角生成快照信息
innodb_space -s ibdata1 -T test/test -p 3 page-illustrate
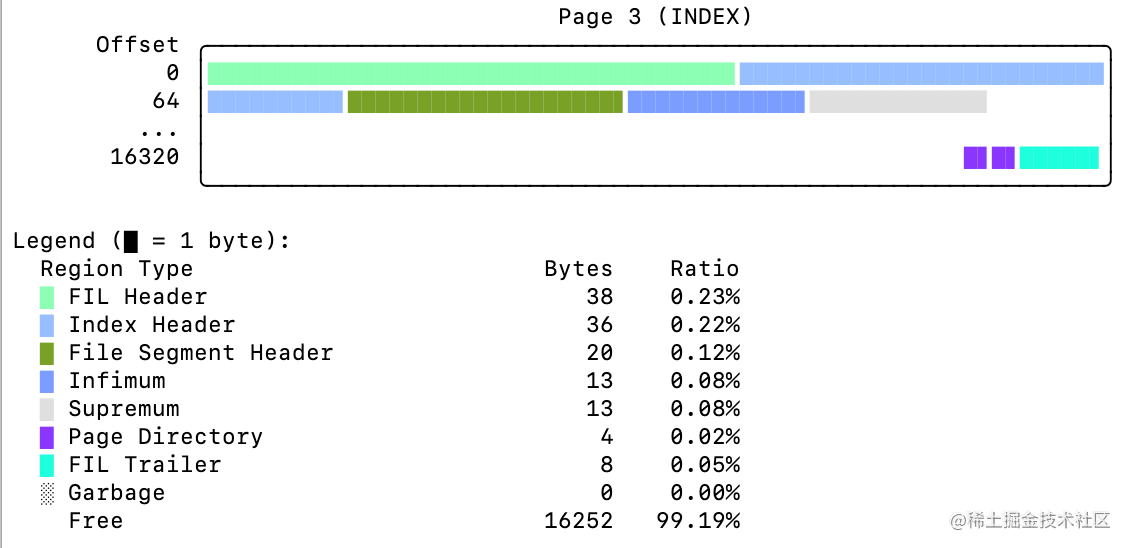
解读如上Index Page内部结构如下:
| Region Type(区域类型) | Bytes(字节空间) | 备注 |
|---|---|---|
| FIL Header | 38 | 文件头 |
| Index Header | 36 | 索引头 |
| File Segment Header | 20 | 即FSEG Header,文件 |
| Infimum | 13 | 虚拟行记录,限定记录最小边界,比最小的任何主键值还小,是System Records的一部分 |
| Supremum | 13 | 虚拟行记录,限定记录最大边界,比最大的任何主键值还大,是System Records的一部分 |
| Page Directory | 动态 | 稀疏目录,记录数据的相对位置,一个槽(Slots)可能拥有多条记录,二叉查找的结果只是一个粗略的结果。B+树索引并不能找到具体的一条记录,能找到的只是该记录所在的页。数据库把页载入到内存,然后通过Page Directory再进行二分查找。 |
| FIL Trailer | 8 | 检测页是否完整写入磁盘。前4字节代表页的checksum值,最后4字节和FIL Header中的FIL_PAGE_LSN相同。checksum的默认算法是CRC32。 |
| Garbage | 0 | 碎片空间 |
| Free | 16252 | 空闲空间 |
至此,我们只得到了一个Index Page,你是否有疑问,行数据(Row) 存在哪个结构体里了呢?目前我们只是做了建表操作,还没有向表中插入任何数据,下面通过不断插入行数据来观察它的存储位置变化,以及不断“膨胀“后的Index Page填充满后是如何从一个单节点的Page演变为庞大的B+Tree的。
从孤独的Page成长为B+Tree
插入一条数据,观察Index Page的变化
# 插入一行数据
insert into test(col_1) value (1);
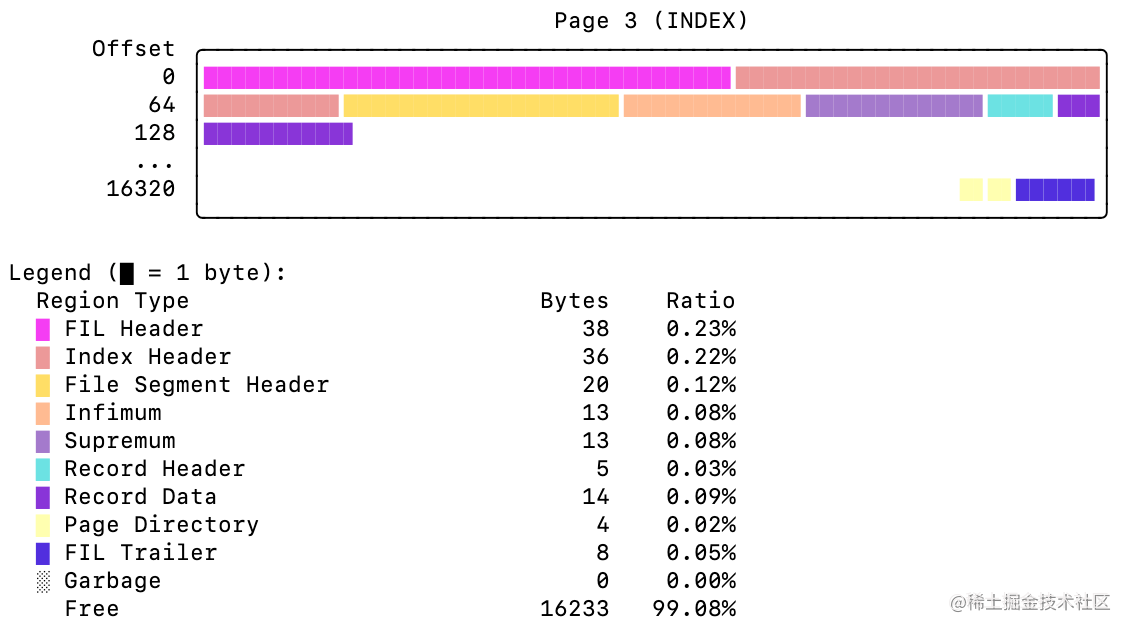
解读Index Page内部变化,如下:
| Region Type(区域类型) | Bytes(字节空间) | 变化 |
|---|---|---|
| FIL Header | 38 | 38 → 38 |
| Index Header | 36 | 36 → 36 |
| File Segment Header | 20 | 20 → 20 |
| Infimum | 13 | 13 → 13 |
| Supremum | 13 | 13 → 13 |
| Page Directory | 4 | 4 → 4 |
| Record Header 🆕 | 5 | 0 ↗ 5(+5) |
| Record Data 🆕 | 21 | 0 ↗ 21(+21) |
| FIL Trailer | 8 | 8 → 8 |
| Garbage | 0 | 0 → 0 |
| Free | 16252 | 16252 ↘ 16226(-26) |
不难发现,Index Page结构中新增加了两列空间数据,随之Free空间由于被占用随之对应减少,空间字节数增减保持一致。
- Record Header 行数据头
- Record Data 行数据,业务数据即存储在此!
Record Header、Record Data一般也会统一叫做User Record,与System Record包含的Infimum、Supremum相对应,还有Garbage部分的碎片记录,叫做Garbage Record。
查看Index Page的存储信息
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# -p 指定页,后面3是页的索引序号,从0开始,这里指定3是因为Page索引3的位置是Index Page,也就是聚簇索引所在页,可结合上述表述分析得到
# page-dump 以表空间指定页Page,生成该页Page的全部存储结构信息
innodb_space -s ibdata1 -T test/test -p 3 page-dump
dump出来的结构及数据内容较多,但是非常清晰和实用,可以耐心参考注释进行分析。
#<Innodb::Page::Index:0x00007fa8c71d86d0>:
fil header:
#<struct Innodb::Page::FilHeader
checksum=3581687651,
offset=3,
prev=nil,
next=nil,
lsn=2641978,
type=:INDEX,
flush_lsn=0,
space_id=33>
fil trailer:
#<struct Innodb::Page::FilTrailer checksum=3581687651, lsn_low32=2641978>
page header:
#<struct Innodb::Page::Index::PageHeader
n_dir_slots=2,
heap_top=146,
n_heap_format=32771,
n_heap=3,
format=:compact,
garbage_offset=0,
garbage_size=0,
last_insert_offset=125,
direction=:no_direction,
n_direction=0,
n_recs=1,
max_trx_id=0,
level=0,
index_id=51>
fseg header:
#<struct Innodb::Page::Index::FsegHeader
leaf=
<Innodb::Inode space=<Innodb::Space file="test/test.ibd", page_size=16384, pages=6>, fseg=2>,
internal=
<Innodb::Inode space=<Innodb::Space file="test/test.ibd", page_size=16384, pages=6>, fseg=1>>
sizes:
header 120
trailer 8
directory 4
free 16226
used 158
record 26
per record 26.00
page directory:
[99, 112]
system records:
#<struct Innodb::Page::Index::SystemRecord
offset=99,
header=
#<struct Innodb::Page::Index::RecordHeader
length=5,
next=125,
type=:infimum,
heap_number=0,
n_owned=1,
info_flags=0,
offset_size=nil,
n_fields=nil,
nulls=nil,
lengths=nil,
externs=nil>,
next=125,
data="infimum\x00",
length=8>
#<struct Innodb::Page::Index::SystemRecord
offset=112,
header=
#<struct Innodb::Page::Index::RecordHeader
length=5,
next=112,
type=:supremum,
heap_number=1,
n_owned=2,
info_flags=0,
offset_size=nil,
n_fields=nil,
nulls=nil,
lengths=nil,
externs=nil>,
next=112,
data="supremum",
length=8>
garbage records:
records:
#<struct Innodb::Page::Index::UserRecord
type=:clustered,
format=:compact,
offset=125,
header=
#<struct Innodb::Page::Index::RecordHeader
length=5,
next=112,
type=:conventional,
heap_number=2,
n_owned=0,
info_flags=0,
offset_size=nil,
n_fields=nil,
nulls=[],
lengths={},
externs=[]>,
next=112,
key=
[#<struct Innodb::Page::Index::FieldDescriptor
name="col_1",
type="BIGINT",
value=1,
extern=nil>],
row=[],
sys=
[#<struct Innodb::Page::Index::FieldDescriptor
name="DB_TRX_ID",
type="TRX_ID",
value=1471,
extern=nil>,
#<struct Innodb::Page::Index::FieldDescriptor
name="DB_ROLL_PTR",
type="ROLL_PTR",
value=
#<struct Innodb::DataType::RollPointerType::Pointer
is_insert=true,
rseg_id=41,
undo_log=#<struct Innodb::Page::Address page=285, offset=272>>,
extern=nil>],
child_page_number=nil,
transaction_id=1471,
roll_pointer=
#<struct Innodb::DataType::RollPointerType::Pointer
is_insert=true,
rseg_id=41,
undo_log=#<struct Innodb::Page::Address page=285, offset=272>>,
length=21>
插入更多数据,查看填满Index Page
上面我们插入一条数据使用了26个字节,目前剩余空间为16226个字节,16226/26≈624,我们插入624行数据后再来观察下该表空间结构和存储变化。
- 继续使用extent视角,查看表空间Page分布情况
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# space-extents-illustrate 以表空间extent段视角生成快照信息
innodb_space -s ibdata1 -T test/test space-extents-illustrate

不难发现,free space page从2两个变成0了,index page从1个变成了3个,下面再来看下index page的具体情况。
- 继续使用page 视角,查看
test表空间的页类型信息
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# space-page-type-summary 以表空间页类型Page Type视角生成快照信息
innodb_space -s ibdata1 -T test/test space-page-type-summary

此时,Index Page已经有3个Page,而Free space下ALLOCATED的2个Page已经不见,此时已经被Index Page使用,所以当前的Page索引位3、4、5全都是Index Page所属,我们来看下Index Page的索引摘要。
- 查看
Index Page索引摘要
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# -I 指定索引,即Index
# -l 指定层级,即level,这里使用0则是层级一,若只有一个Page节点,那么此时B+Tree只有一层,0即root根节点,如果B+Tree有多个level,那么会从0到更多上升,此时0是非叶子结点
innodb_space -s ibdata1 -T test/test -I PRIMARY -l 0 index-level-summary

innodb_space -s ibdata1 -T test/test -I PRIMARY -l 1 index-level-summary

- 查看
Page 3 \ 4 \ 5中的Record数据行记录
🔸 查看Page-3的数据行记录
# 这是Innodb Ruby的使用命令,具体可以参考上面资料
# -s 指定系统表空间文件
# -T 指定用户表空间、业务表
# -I 指定索引,即Index
# -l 指定层级,即level,这里使用0则是层级一,若只有一个Page节点,那么此时B+Tree只有一层,0即root根节点,如果B+Tree有多个level,那么会从0到更多上升,此时0是非叶子结点
innodb_space -s ibdata1 -T test/test -p 3 page-records
Record 125: (col_1=1) → #4
Record 142: (col_1=288) → #5
🔸 查看Page-4的数据行记录
innodb_space -s ibdata1 -T test/test -p 4 page-records
Record 125: (col_1=1) → ()
Record 151: (col_1=2) → ()
Record 177: (col_1=3) → ()
...
Record 7509: (col_1=285) → ()
Record 7535: (col_1=286) → ()
Record 7561: (col_1=287) → ()
🔸 查看Page-5的数据行记录
innodb_space -s ibdata1 -T test/test -p 5 page-records
Record 125: (col_1=288) → ()
Record 151: (col_1=289) → ()
Record 177: (col_1=290) → ()
...
Record 8835: (col_1=623) → ()
Record 8861: (col_1=624) → ()
Record 8887: (col_1=625) → ()
当前Index Page的3个Page以及它们各自的Record数据分布较为清晰,整理这颗B+Tree的结构关系图如下:
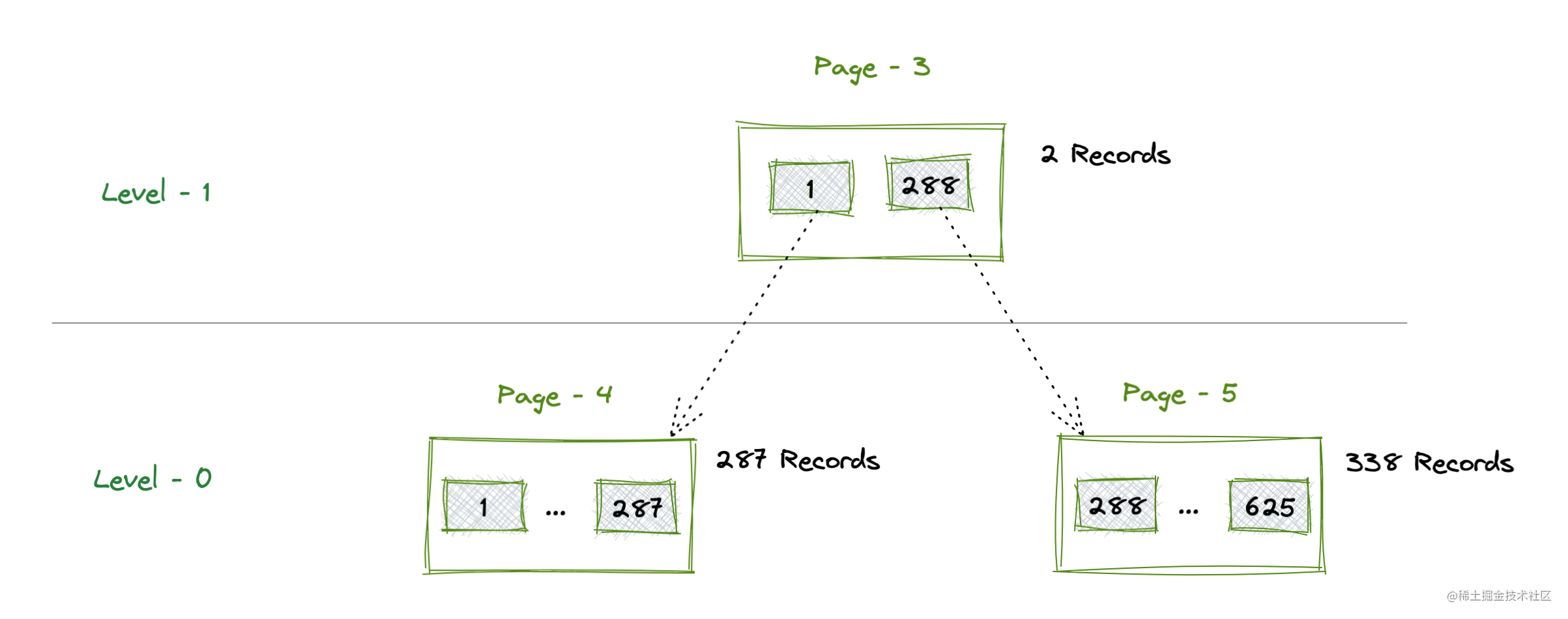
至此,完成了Index Page从孤独的单个Page节点到一颗B+Tree的演变。我们借助Innodb Ruby工具对物理存储底层进行了较为细致的观察和整理,看到过程和变化,能够直接触摸到物理数据本身进行分析和学习,对于深入理解Innodb的存储乃至后续上层能力有非常大的帮助。
种类繁多的列类型
综上,我们可看到Index Page中行数据(Record)决定了每一个Page的存储情况,影响每个Page的关联情况,从而影响到整颗B+Tree的结构,而每一个行数据(Record)的最原子组成就是列(Column),因此每一个列类型的存储需求从小到大影响着全局的存储形态和结构,下面我们来从列(Column)的存储需求入手,看看为什么要“精挑细选”。
参考 MySQL列类型存储需求
在MySQL中列的类型可以分为三类,数值类型、文本类型、时间&日期类型,每一种具体类型对应着具体的存储需求,这些具体的存储大小整合在一起填满了Page页结构的存储分布。
数值类型
| 列类型 | 存储需求 |
|---|---|
| TINYINT | 1 Byte |
| SMALLINT | 2 Byte |
| MEDIUMINT | 3 Byte |
| INT, INTEGER | 4 Byte |
| BIGINT | 8 Byte |
| FLOAT(p) | 如果0 <= p <= 24为4个字节, 如果25 <= p <= 53为8个字节 |
| FLOAT | 4 Byte |
| DOUBLE [PRECISION], item REAL | 8 Byte |
| DECIMAL(M,D), NUMERIC(M,D) | 变长;DECIMAL(和NUMERIC)的存储需求与具体版本有关:使用二进制格式将9个十进制(基于10)数压缩为4个字节来表示DECIMAL列值。每个值的整数和分数部分的存储分别确定。每个9位数的倍数需要4个字节,并且“剩余的”位需要4个字节的一部分。 |
| BIT(M) | 大约(M+7)/8 Byte |
文本类型
| 列类型 | 存储需求 |
|---|---|
| CHAR(M) | M个字节,0 <= M <= 255 |
| VARCHAR(M) | L+1个字节,其中L <= M 且0 <= M <= 65535(参见下面的注释) |
| BINARY(M) | M个字节,0 <= M <= 255 |
| VARBINARY(M) | L+1个字节,其中L <= M 且0 <= M <= 255 |
| TINYBLOB, TINYTEXT | L+1个字节,其中L < 28 |
| BLOB, TEXT | L+2个字节,其中L < 216 |
| MEDIUMBLOB, MEDIUMTEXT | L+3个字节,其中L < 224 |
| LONGBLOB, LONGTEXT | L+4个字节,其中L < 232 |
| ENUM(‘value1’,‘value2’,…) | 1或2个字节,取决于枚举值的个数(最多65,535个值) |
| SET(‘value1’,‘value2’,…) | 1、2、3、4或者8个字节,取决于set成员的数目(最多64个成员) |
VARCHAR、BLOB和TEXT类是变长类型,每个类型的存储需求取决于列值的实际长度(上表中的L表示),而不是该类型的最大可能的大小。具体的L需要根据字符集进行判断。
日期&时间类型
| 列类型 | 大小(bytes) | 范围 | 格式 | 小数点精度支持 | 用途 |
|---|---|---|---|---|---|
| YEAR | 1 | 1901/2155 | YYYY | 0 | 年份值 |
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 0 | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | [0,6] | 时间值或持续时间 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | [0,6] | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | [0,6] | 混合日期和时间值,时间戳 |
用现实数据解答困惑
在设计数据建模时,根据业务需求选择合理的列类型不仅对Index Page单页友好,对于整体B+Tree的排列也会有帮助。
一般而言,一个表的字段不建议超过20列,如果存储2000万左右的数据大概需要一颗2 ~ 3层的B+Tree就能够满足了。当然,现实业务需求总是“奇奇怪怪”,难免会有一些取舍或反范式,甚至存在暂时不合理的设计和实现把B+Tree搞的也非常奇特。
精致与粗糙的成本差距
这里我们举例一个使用char设置定长和使用varchar可变长度的存储差异。
- 首先,创建两张表,如下:
# 固定长度表
CREATE TABLE `test01` (
`col_1` bigint(20) NOT NULL AUTO_INCREMENT,
`col_2` char(50) NOT NULL, -- 这里的50是设置的最大长度,可设置范围是0 <= M <= 255
PRIMARY KEY (`col_1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
# 可变长表
CREATE TABLE `test02` (
`col_1` bigint(20) NOT NULL AUTO_INCREMENT,
`col_2` varchar(50) NOT NULL,
PRIMARY KEY (`col_1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
- 分别插入
2000条字节长度为10的col_2数据,如下:
DELIMITER;
CREATE PROCEDURE loop_insert()
BEGIN
DECLARE idx int DEFAULT 1;
WHILE idx <= 2000
DO
insert into test01(col_1, col_2) VALUES (null, '0123456789');
insert into test02(col_1, col_2) VALUES (null, '0123456789');
SET idx = idx + 1;
END WHILE;
COMMIT;
END;;
CALL loop_insert();
- 查看两个表的数据存储情况,如下:
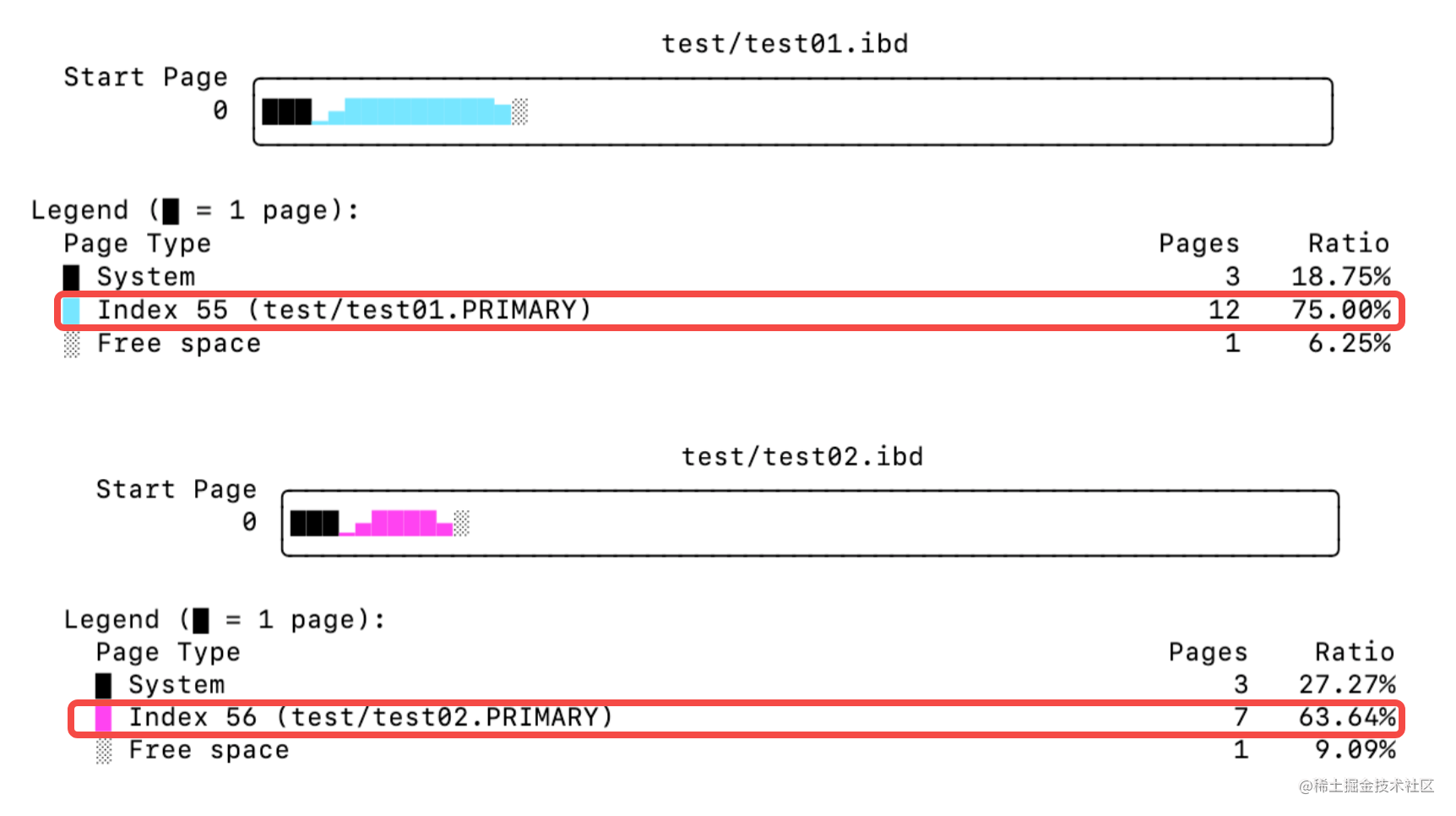
可以看到,存储列字段长度为10个字节时,使用定长char(50)比使用可变长varchar(50)占用了更多的空间,多出了5个Page的空间使用。
- 再来查看两个表的
B+Tree层级情况,绘图整理如下:

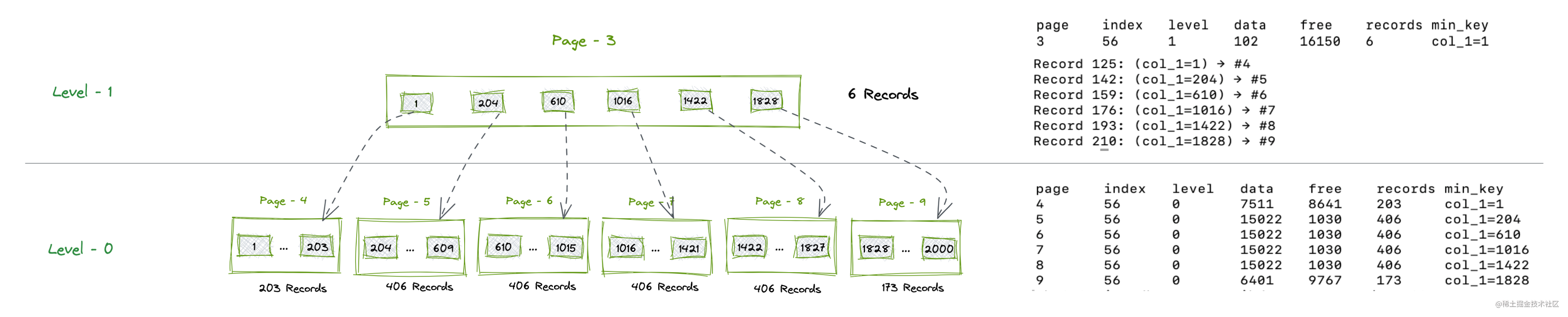
可以看到,定长char的Page平均只存储了大概不到200条Record,而可变长varchar的Page平均存储可达到400条,可变长varchar在Page的利用空间上有非常大的优势。
- 查看
Record在两个表中的偏移量情况,如下:
# test01表,第一个非叶子节点
innodb_space -s ibdata1 -T test/test01 -p 4 page-records
# 偏移量间隔为 <77> 字节
Record 126: (col_1=1) → (col_2="0123456789")
Record 203: (col_1=2) → (col_2="0123456789")
Record 280: (col_1=3) → (col_2="0123456789")
Record 357: (col_1=4) → (col_2="0123456789")
Record 434: (col_1=5) → (col_2="0123456789")
......
# test02表,第一个非叶子节点
innodb_space -s ibdata1 -T test/test02 -p 4 page-records
# 偏移量间隔为 <37> 字节
Record 126: (col_1=1) → (col_2="0123456789")
Record 163: (col_1=2) → (col_2="0123456789")
Record 200: (col_1=3) → (col_2="0123456789")
Record 237: (col_1=4) → (col_2="0123456789")
Record 274: (col_1=5) → (col_2="0123456789")
......
可以看到,在当前用例中,存储同样数据大小时,定长char的每条记录行的偏移量是77字节,而可变长varchar的每条记录行的偏移量是37字节,量变引起质变,存储成本一目了然。
除了存储成本的影响,还有查询效率的影响,尽管在Innodb的聚簇索引中是一颗多路树,会尽量保持足够“克制”的深度以便有更高性能支持,但叶子节点的增加会成为积攒层级增加的“诱因”,频繁的节点裂变也会造成节点平衡性变化和空间浪费。
推荐的列设计实践
总结一些日常设计中列类型的选择和考量,如下:
| 列类型 | 使用场景 |
|---|---|
| char | 可控的固定值,性别、学段、难度等 |
| varchar | 大部分不固定的文本,均可承载,关注长度即可 |
| tinyint | 一般场景下的数量较少的枚举,较为经济实惠 |
| int | 大部分常见的数值需求,范围一般可满足 |
| bigint | 主键ID,理论上可以支持业务范围可用 |
| decimal | 支持高精度的存储需求,不推荐使用float、double不同版本会有精度或转换问题 |
| datetime | 推荐使用datetime记录时间,没有存储穷尽隐患 |
列设计的Q&A环节
时间列怎么选择?
time、datetime、timestamp都支持小数点0~6的精度,year、date记录的是年份、年月日,因此不支持小数点时间精度。
datetime、timestamp都可以用来记录年月日时分秒,也支持最大6位的小数点精度,但是timestamp占用4字节存储范围较小,从系统长久使用、健壮性以及后续维护成本来说不建议使用该类型来记录时间,datetime占用8字节存储范围较大,一般我们采用datetime来进行时间数据存储,能满足大部分业务场景对时间范围、精度的最大要求。
uuid或单号怎么选择?
使用varchar,扩展性更好,支持字符和数字的混合,而且在可生成范围内没有未来长度瓶颈。
不要被uuid输出的全数字形态而迷惑,可以了解下雪花算法的相关“套路”,它的本质是披着数字外壳的字符串,只要是字符串理论上就会超过最大数值类型的限制,因此从根儿上也不推荐使用迷惑的数值类型去存储字符串数据。
超大文本怎么存储怎么搞?
一般可以使用text类型的进行存储超大文本数据,还有blob也可以支持二进制数据存储,比如图片、视频等信息,对于这两种列类型的存储需求和形式,Innodb有独特的支持,感兴趣可以参考以上过程自行拓展。
需要注意的是,如果你在做云存储相关业务,相信你会有更好的数据库选择,而不是完全吊死在MySQL上进行穷尽式开发。
主键为什么要bigint unsigned auto_increment一套组合拳?
- 『为什么是bigint』:
bigint可以支持大部分业务范围内的主键范围需求,这个max是2^31-1,使用数值类型的存储空间更小,只需要8字节,其他字符类型空间随着位数增加占用更大,因此可以让叶子节点更紧凑,庞大数据量下Page节点更少,且数值天然支持自增。 - 『unsigned的作用』:
支持位更多,范围更大,容量更好。
| 设置 | 范围 |
|---|---|
| bigint(20) | -2^63 (-9223372036854775808) ~ 2^63-1 (9223372036854775807) |
| bigint(20) unsigned | 0 ~ 18446744073709551615 |
- 『保持自增的理由』:
聚簇索引是一个B+Tree结构,叶子节点存储的全是主键值,具体的数据行存储在非叶子节点上。B+Tree核心特性是维护数据的有序性,自增插入有利于有序性的维护以及树自身平衡性,如果是随机数插入那么需要频繁的找到叶子节点上的插入位,可能频繁触犯叶子节点分裂或合并,效率非常低下。
为什么要限制表中的列数量?
一般而言,我们会按照一个用户表一个表空间的形式维护,即一个table对应一个ibd文件,列越多意味着行数据越大,那么填充满一个Index Page的速度就越快,而Index Page的大小是固定的,想要存储更多的行数据就需要更多的Index Page空间来支持,随着Index Page数量的增加B+Tree的叶子节点也会进行分裂和维护对应边界保持性能。
因此保持一定数量的列设置是友好的设计开始,我们常说的垂直切分表,除了从业务逻辑边界视角更为合理、清晰、解耦外,站在数据存储角度也会有很大提升,将繁多的列分散到多个表,对应多个表空间进行存储和维护,提升单个表空间的容积率和相对装载率,是维护性、操作性很高的设计实践。
🏄🏄🏄 以上便是本章的全部内容,如果觉得有所收获,欢迎 『点赞』、『收藏』、『关注』 一键三连支持喔~




![Rasa 3.x 学习系列-Rasa [3.4.0] - 2022-12-14新版本发布](https://img-blog.csdnimg.cn/8b7342fc1aef4f0f9c8b1805a1d3f90e.png)