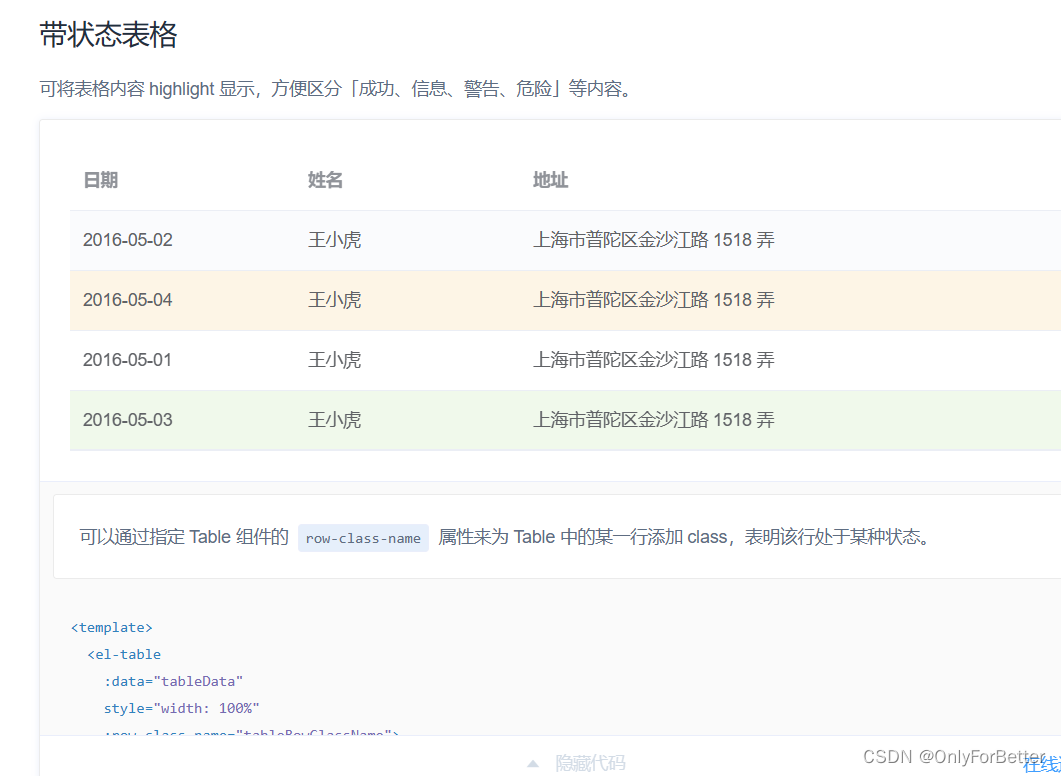
类别不平衡是一个常见问题,其中数据集中示例的分布是倾斜的或有偏差的。
1. 简介
类别不平衡是机器学习中的一个常见问题,尤其是在二元分类领域。当训练数据集的类分布不均时会发生这种情况,从而导致训练模型存在潜在偏差。不平衡分类问题的示例包括欺诈检测、索赔预测、违约预测、客户流失预测、垃圾邮件检测、异常检测和异常值检测。为了提高我们模型的性能并确保其准确性,解决类不平衡问题很重要。
在这篇文章[1]中,我们将研究解决此问题的三种方法,以提高我们模型的性能和准确性。我们还将讨论为这些类型的任务选择正确指标的重要性。

2. 从多分类到二分类
我们将介绍二元分类的概念以及如何利用它来解决类别不平衡的挑战。二元分类涉及将数据集分为两组:正组和负组。通过将问题分解为多个二类问题,这些原则也可以扩展到多类问题。这种技术使我们能够解决类不平衡问题,并利用一系列方法来增强我们模型的性能。
3. 常用方法
有几种方法可用于解决机器学习中的类不平衡问题。一种方法是欠采样或过采样,也称为“类增强”,它涉及调整少数类或多数类中的样本数量以改善数据集的平衡。另一种选择是改变损失函数的权重,这可以帮助模型在训练过程中更多地关注少数类。最后,可以初始化最后一层的偏差来预测不等概率,让模型更好地预测少数类。这些方法可以单独使用或组合使用,具体取决于具体问题的需要。
3.1. 欠/重采样
重采样是一种用于解决机器学习中类别不平衡的常用技术。它涉及通过从原始数据集中选择示例来创建具有不同类别分布的新版本训练数据集。一种流行的重采样方法是随机重采样,其中为转换后的数据集随机选择示例。重采样通常被认为是解决不平衡分类问题的一种简单有效的策略,因为它允许模型在训练期间更均匀地考虑来自不同类别的示例。但是,重要的是要仔细考虑重采样的权衡和局限性,因为它还会在数据集中引入额外的噪声和偏差。下图提供了过采样(上)和欠采样(下)的图示。

3.2. 权重修改
解决类不平衡的第二种方法是修改损失函数的权重。在平衡数据集中,损失函数的梯度(即朝向局部最小值的方向)被计算为所有样本的平均梯度。

但是,在不平衡的数据集中,该梯度可能无法准确反映少数类的最佳方向。为了解决这个问题,我们可以通过作为优化过程的一部分的过采样或使用加权损失来分解梯度。

过采样涉及人为地增加数据集中少数类示例的数量,这可以帮助模型在训练过程中更准确地考虑这些示例。
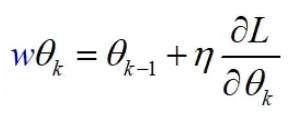
或者,使用加权损失涉及为少数类示例分配更高的权重,以便模型更加强调正确分类这些示例。
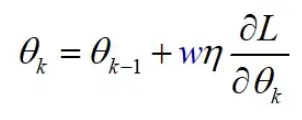
这两种方法都可以帮助提高模型在不平衡数据集上的性能。
3.3. 初始化偏置
我们在这篇文章中介绍的解决机器学习中类不平衡问题的最后一种技术是偏差初始化,它涉及调整模型参数的初始值以更好地反映训练数据的分布。更具体地说,我们将设置最终层偏差。例如,在具有 softmax 激活函数的不平衡二元分类问题中,我们可以将最后一层的初始偏差设置为 b=log(P/N),其中 P 是正例的数量,N 是正例的数量反面例子。这可以帮助模型在训练过程的初始化时更准确地衡量正类和负类的概率,提高其在不平衡数据集上的性能。
仔细考虑偏置初始化的权衡和局限性很重要,因为如果初始化错误,它可能会在模型中引入额外的偏置。然而,如果使用得当,这种技术可以成为解决类不平衡和提高模型性能的有效方法。
4. 分类指标
在机器学习中处理不平衡数据集时,选择正确的评估指标以准确评估模型的性能至关重要。例如,在包含 99,000 张猫图像和仅 1,000 张狗图像的数据集中,模型的初始准确度可能为 99%。但是,此指标可能无法真实地表示模型准确分类少数类(狗)的能力。
评估分类器在不平衡数据集上的性能的一个有用工具是基于混淆矩阵的指标。该矩阵提供了模型做出的真阳性、真阴性、假阳性和假阴性预测的细分,从而可以更细致地了解其性能。在不平衡数据集上评估模型时,考虑各种指标非常重要,以便全面了解其功能。
混淆矩阵的快速回顾:在评估分类器的性能时,考虑各种指标很有帮助。混淆矩阵是理解真阳性 (TP) 预测和假阴性 (FN) 预测的有用工具,在真阳性 (TP) 预测中,模型正确识别了阳性类,在假阴性 (FN) 预测中,模型错误地将样本分类为负类实际上是积极的。混淆矩阵还提供有关假阳性 (FP) 预测的信息,其中模型错误地将样本识别为实际上是阴性的阳性类,以及真阴性 (TN) 预测,其中模型正确识别了阴性类。通过考虑这些不同类型的预测,我们可以更全面地了解模型的性能。

为了了解分类器的性能,重要的是要考虑一系列评估指标。准确率、精确率和召回率是三个常用的指标,可以从混淆矩阵中计算出来。
准确度反映了模型预测的整体准确度,计算方式为正确预测的数量除以预测总数。精度测量实际正确的正预测的比例,计算为真正的正预测数除以模型做出的正预测总数。而召回率,也称为灵敏度或真阳性率,捕获模型正确预测的实际阳性样本的比例,计算为真阳性预测的数量除以实际阳性样本的总数。

-
对苹果和香蕉进行分类的示例 (90:10):
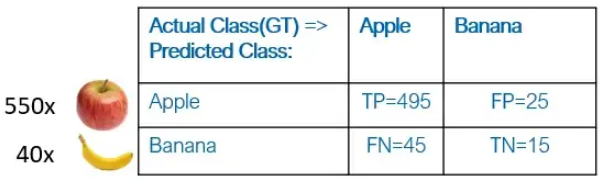

在此示例中,指标可能表明苹果类别的表现出色。然而,考虑香蕉类的性能也很重要,因为模型的整体性能可能并不一致。仍然有必要评估模型在香蕉类上的表现,以充分了解其能力。通过考虑这两个类别的性能,我们可以识别任何潜在的不平衡以改进模型。我们将使用两个额外的指标,误报率和负率。
假阳性率表示被模型错误预测为阳性的实际负样本的比例,计算为假阳性预测的数量除以实际负样本的总数。假阴性率反映了被模型错误预测为阴性的实际阳性样本的比例,计算为假阴性预测的数量除以实际阳性样本的总数。
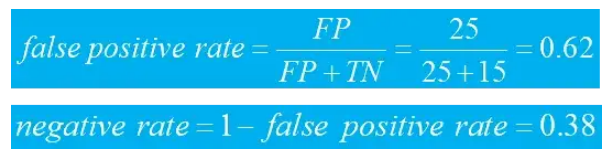
在这种情况下,很明显存在不平衡的类别问题。检测和诊断类不平衡可能具有挑战性,使用适当的指标来识别它很重要。
总结
类不平衡是机器学习中的一个常见问题,当数据集中的示例分布倾斜或有偏差时,就会发生这种情况。这可能会导致训练模型出现偏差,从而对其性能产生负面影响。在这篇文章中,我们探讨了解决类不平衡的各种方法,包括重采样、修改损失函数的权重以及初始化最后一层的偏差。这些技术可以单独或组合使用。我们还强调了选择正确的评估指标(例如准确性、精确度和召回率)以准确评估这些模型的性能的重要性。通过理解和解决类不平衡问题,我们可以大大提高模型的可靠性和有效性。
欢迎Star -> 学习目录
参考资料
Source: https://towardsdatascience.com/solving-the-class-imbalance-problem-58cb926b5a0f
本文由 mdnice 多平台发布