文章目录
- 一、知识蒸馏Knowledge Distillation
- 二、参数量化
- 结构设计:深度方向可分卷积Depthwise Separable Convolution
- 1、Depthwise Convolution
- 三、动态计算Dynamic Computation
- 四、From on-policy to off-policy(PPO)
一、知识蒸馏Knowledge Distillation
学生网络学习老师网络。

学生可以学到训练资料可能没有提供的东西。
老师也可以是很多个模型的投票结果:

温度常数用于softmax:可以让分布变平滑。这是一个超参数,不能非常大(会变成所有参数都一样)
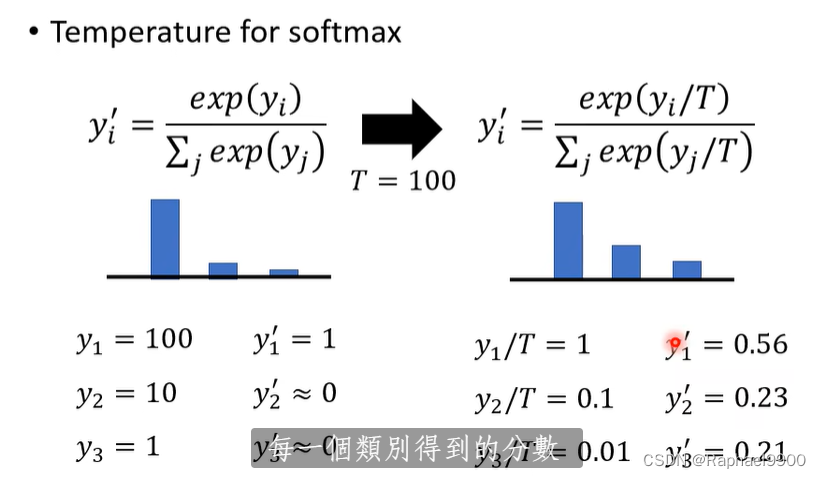
这里有平滑的分布,就不是one-hot一样的东西(要么是0,要么是1),这样就不是给一个标准答案了!可以给额外更多的信息。
二、参数量化
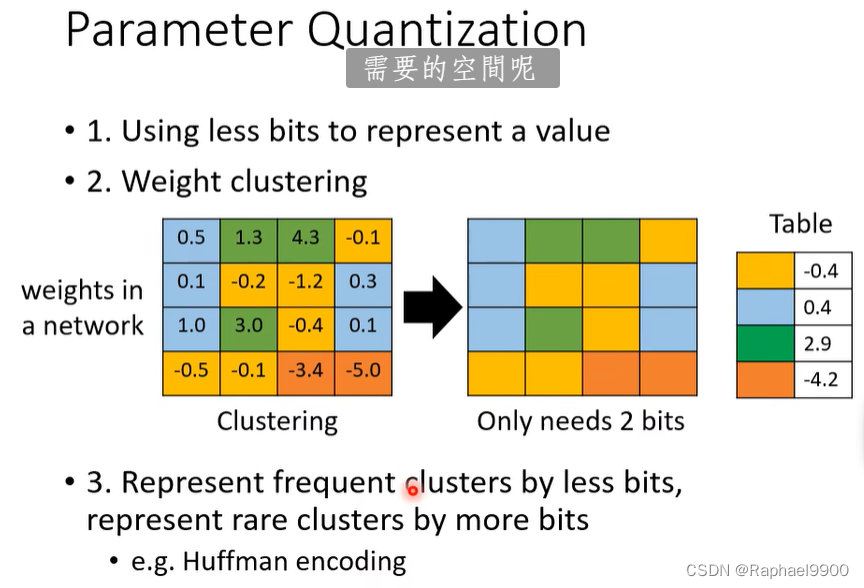
• 1.使用较少的位来表示一个值
•2.权重聚类(确定了分布之后取平均)
3.用较少的比特表示频繁的聚类,用较多的比特表示罕见的聚类,例如霍夫曼编码。
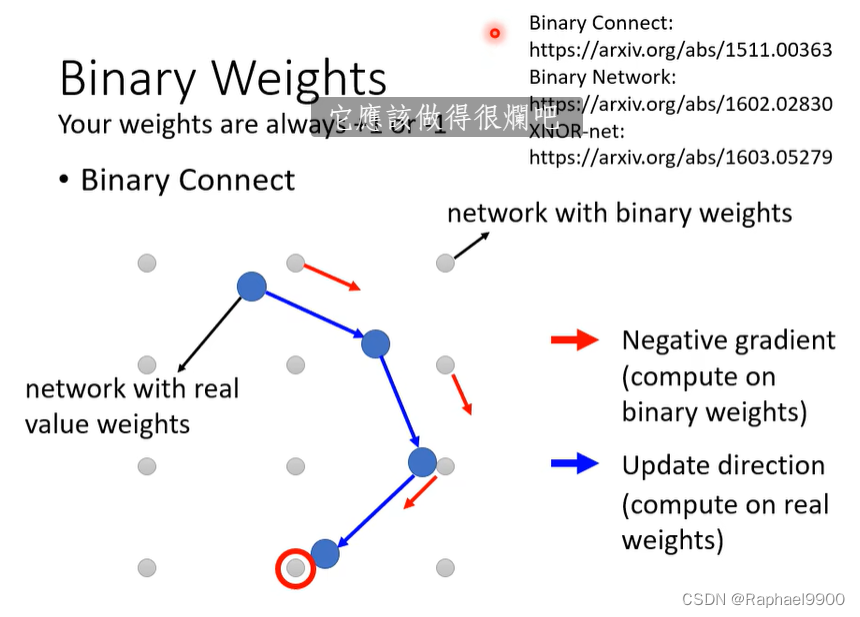
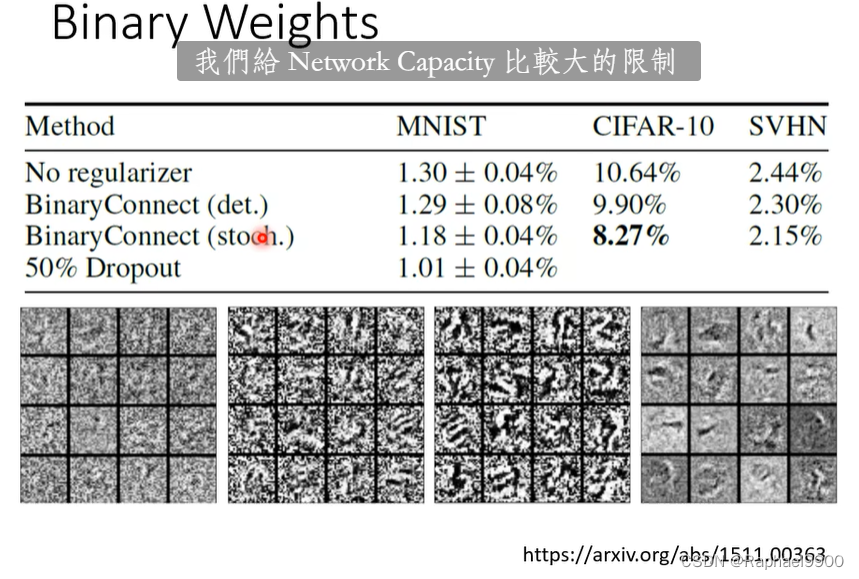
压缩到参数只有+1或者-1,binary weights
结构设计:深度方向可分卷积Depthwise Separable Convolution

有几个channel就有几个filter,每个filter管理每个channel。问题:chanel之间没有联系
1、Depthwise Convolution
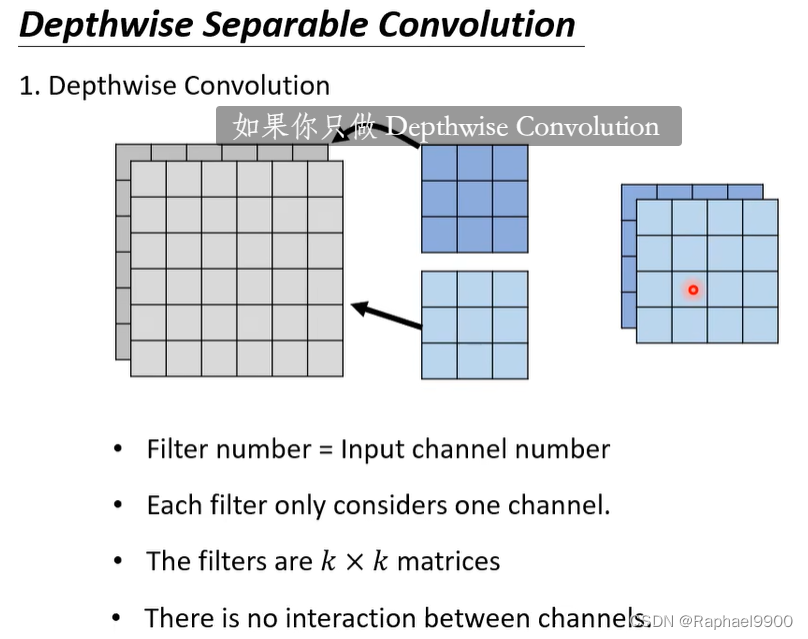
filter是1*1的
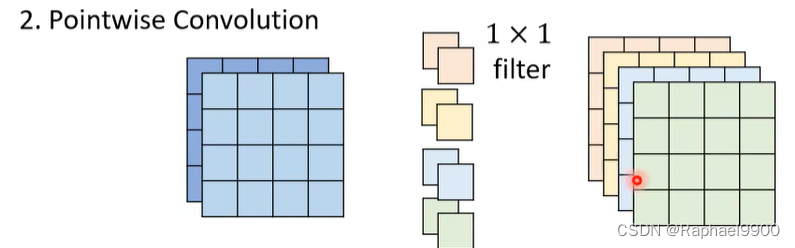
专注于channel之间的关系。

参数量少了很多
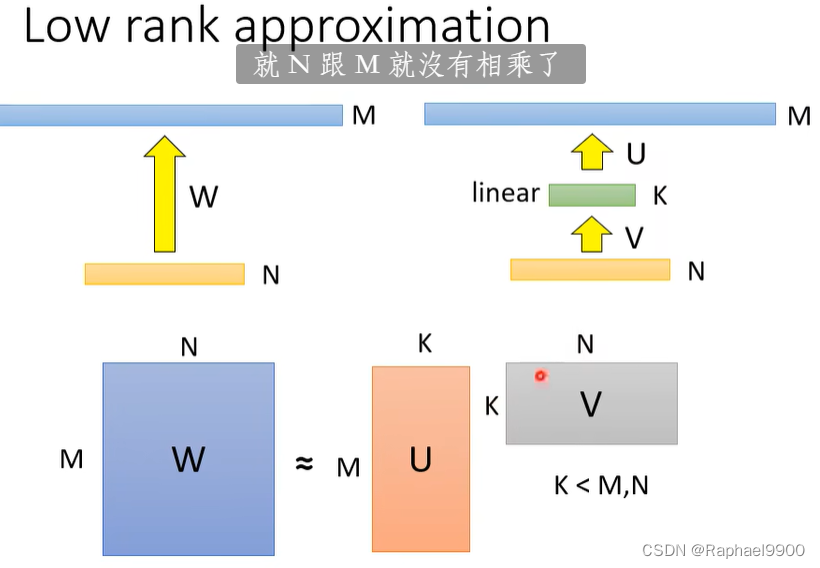
low rank approximation也是减少了参数的方法,但是还是有限制:减少了W的可能性,不是所有的w都能做为参数。
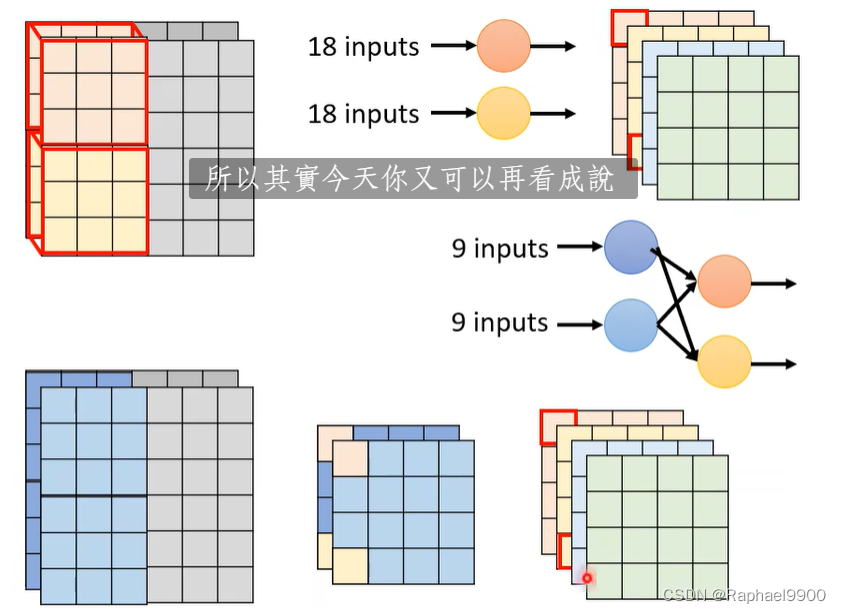
Depthwise Separable Convolution跟这个也很像:
三、动态计算Dynamic Computation
网络根据需要调整计算。

为什么我们不准备一套模型?根据需要选择不同的模型?麻烦!
怎么做呢?让网络自由调整深度,增加额外的层。
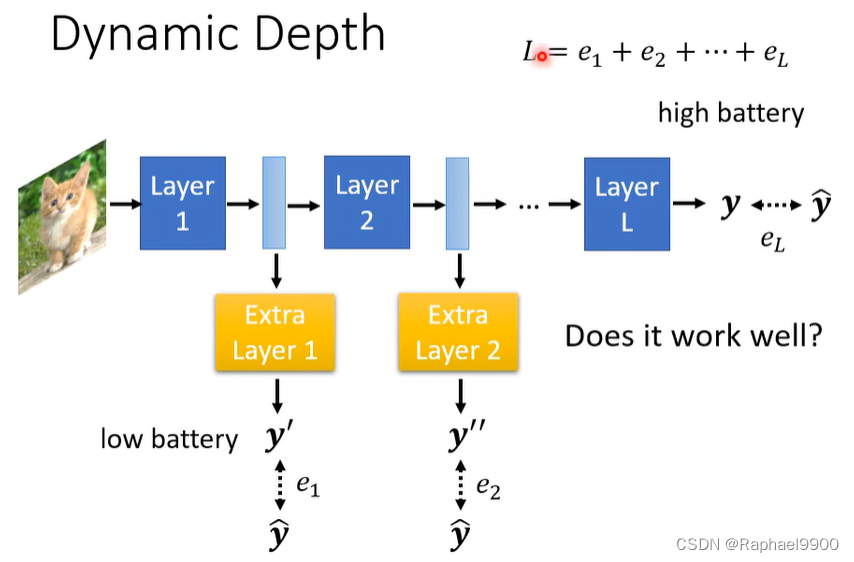
也可以改变宽度:
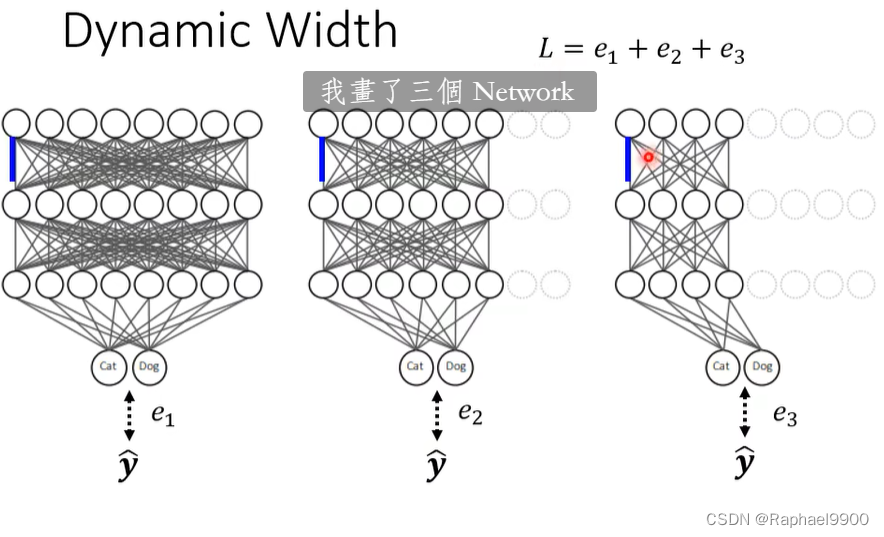
这两种方法都是让L越小越好。
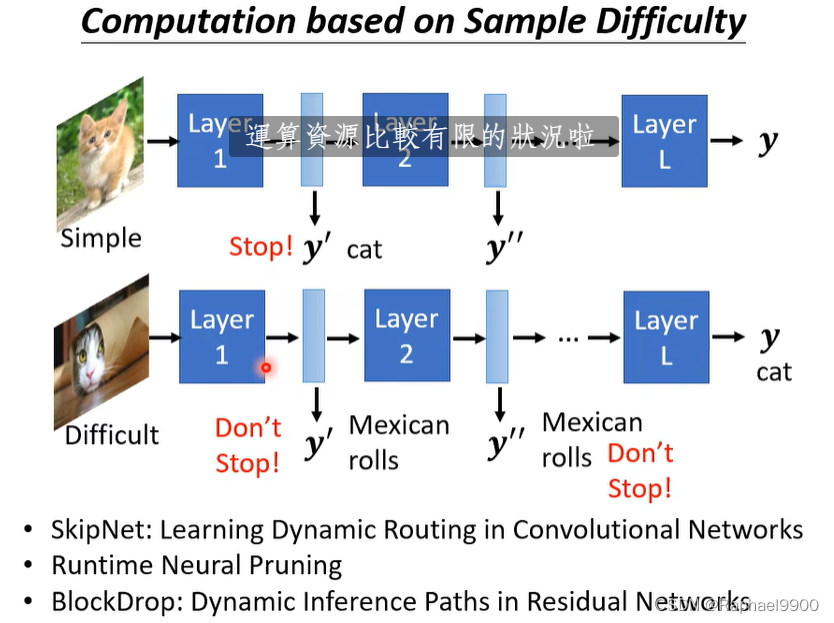
不同的压缩对应于不同的应用:简单的图片可以在小的层就能结束,难的图片在多的层结束。
四、From on-policy to off-policy(PPO)
不止一次地利用经验
on-policy :学习的代理和与环境交互的代理是相同的。
off-policy:代理学习和与环境交互的代理是不同的。


期望一样但是不代表variance一样。

这里希望取样足够多,那么variance就相近。
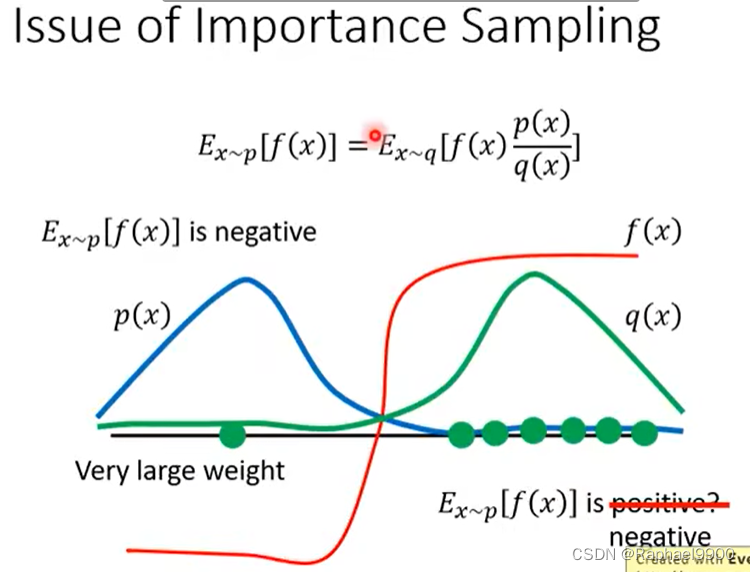
这里做了修正之后,从θ’(跟环境互动)里面取样,而我们也可以通过更新多次θ的参数之后采取做一次参数取样。


这两个θ的分布不能相差太多,PPO做的解决这个问题

TRPO是比较难做的
我们引入KL散度,希望两个actor上的分布越近越好,不是参数上的差距。

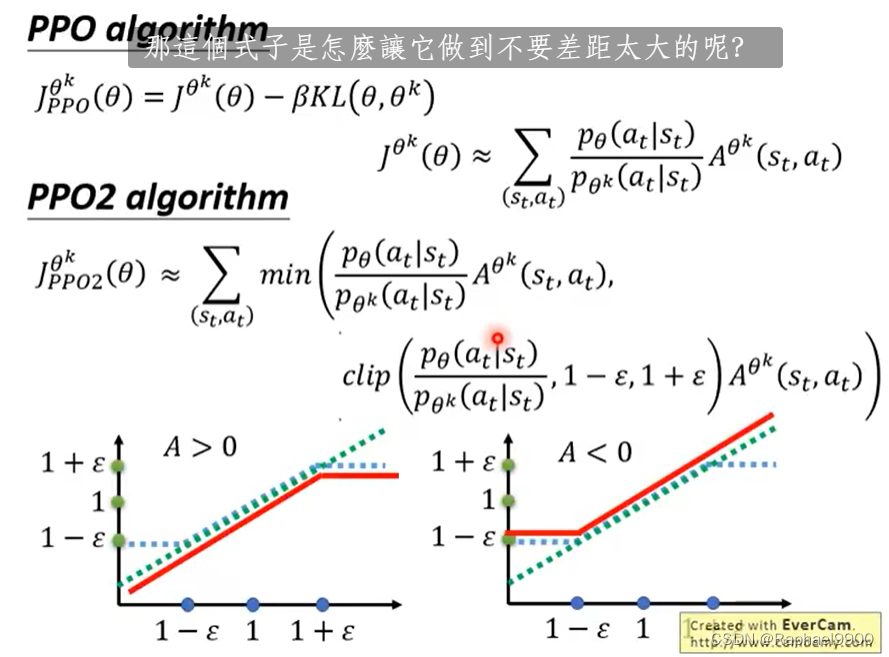
横轴是θ的p相除,在A>0的时候(得分好),我们希望Pθ越大越好,但是和Pθk之间的差距不要太大,限制最大为1+E,如果比1+E大那就只要1+E,不让他继续增大了。
如果A<0的时候(得分低),希望Pθ越小越好,但是希望最低是1-E。







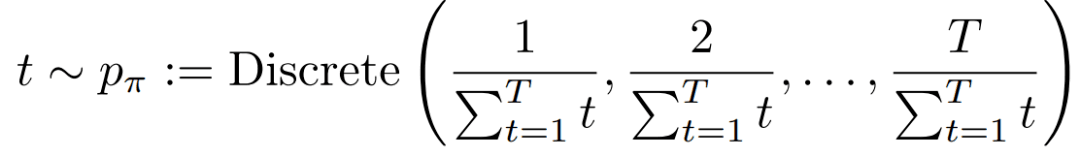







![基础算法[四]之图的那些事儿](https://img-blog.csdnimg.cn/485dba8af63d4f1da3bc430c88497283.png)
