大家好,我是宁一。
已经连续四个周没有休息了,最近主业、副业都是忙碌的巅峰期,晚上11点下班回家,再写课写到凌晨两点。
连续一个多月连轴转,每天最大的愿望,就是睡足觉。
这一阶段终于忙完了~继续来更新SQL面试题啦~
题目五:
175. 组合两个表(简单)
现在有两个表:
Person表:包含 PersonId、
姓LastName、名FirstName的信息。
+----------+----------+-----------+| personId | lastName | firstName |+----------+----------+-----------+| 1 | Wang | Allen || 2 | Alice | Bob |+----------+----------+-----------+
Address表:包含AddressId、PersonId、城市City、州State的信息。
+-----------+----------+---------------+------------+| addressId | personId | city | state |+-----------+----------+---------------+------------+| 1 | 2 | New York City | New York || 2 | 3 | Leetcode | California |+-----------+----------+---------------+------------+
编写一个SQL查询来报告 Person 表中每个人的姓、名、城市和州。如果 personId 的地址不在 Address 表中,则报告为空null。
结果示例:
+-----------+----------+---------------+----------+| firstName | lastName | city | state |+-----------+----------+---------------+----------+| Allen | Wang | Null | Null || Bob | Alice | New York City | New York |+-----------+----------+---------------+----------+
解题思路:
这道题很简单,主要考察是就是JOIN连接的知识点,到底用左连接还是右连接。
注意题目中的这句话“如果 personId 的地址不在 Address 表中,则报告为空 null ”。
空值出现在 Address 表中,所以我们把Person表放在左边、Address 表放在右边,使用左连接left join。
SELECT firstName,lastName,city,stateFROM Person pLEFT JOIN Address aON p.personId = a.personId;
想要自己电脑本地测试,可以用这个快速创建数据表语句:
-- 创建表PersonCREATE TABLE Person(personId INT,LastName VARCHAR(10),FirstName VARCHAR(10));-- 插入语句INSERT INTO Person VALUES(1,'Wang','Allen'),(2,'Alice','Bob');CREATE TABLE Address(addressId INT,personId INT,City VARCHAR(20),state VARCHAR(20));-- 插入语句INSERT INTO Address VALUES(1,2,'New York City','New York'),(2,3,'Leetcode','California');
知识点:Join连接
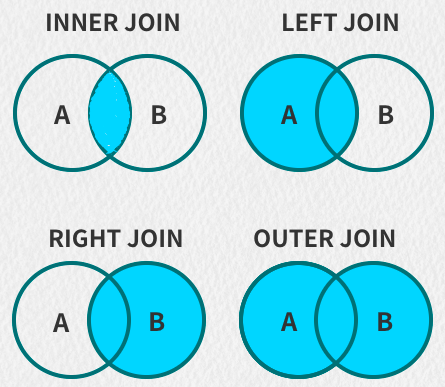
多张数据表联合查询,需要用到JOIN连接,JOIN连接分为好几种:
* INNER JOIN:内连接,也可以只写JOIN。只有进行连接的两个表中,都存在与连接标准相匹配的数据才会被保留下来,相当于两个表的交集。如果前后连接同一张表,也叫自连接。
* LEFT JOIN: 左连接,也称左外连接。操作符左边表中符合 WHERE 子句的所有记录将会被返回,操作符右边表中如果没有符合 ON 后面连接条件的记录时,那么从右边表指定选择的列的值将会是 NULL。
* RIGHT JOIN: 右连接,也称右外连接。会返回右边表所有符合 WHERE 语句的记录。左表中匹配不上的宇段值用 NULL 代替。
* FULL JOIN:全连接,返回所有表中符合 WHERE 语句条件的所有记录。如果任一表的指定宇段没有符合条件的值的话,那么就使用 NULL 替代。
题目六:
178. 分数排名(中等)
现有一个成绩表: Scores
+----+-------+| id | score |+----+-------+| 1 | 3.50 || 2 | 3.65 || 3 | 4.00 || 4 | 3.85 || 5 | 4.00 || 6 | 3.65 |+----+-------+
编写 SQL 查询,对分数进行从高到低排序,如果两个分数相等,那么两个分数的排名应该相同。要求排名应该是连续的,中间不要有空缺的数字。
查询结果格式如下所示。
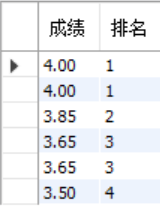
+-------+------+| score | rank |+-------+------+| 4.00 | 1 || 4.00 | 1 || 3.85 | 2 || 3.65 | 3 || 3.65 | 3 || 3.50 | 4 |+-------+------+
解题思路:
这道题主要考察的是“相关子查询”,在相关子查询中,子查询是在主查询每一条记录层面上依次进行的,子查询依赖主查询。
这道题我们先来给分数做个倒序排序,将rank列写成子查询,计算出大于等于当前外查询分数的去重个数,这个数量就是排名。
第一步:先来降序排列分数。
SELECT a.Score AS '成绩'FROM Scores aORDER BY a.score DESC
第二步:将select后面,“排名”列写成子查询。计算出大于等于当前外查询分数的去重个数,这个数量就是排名。
SELECT a.Score AS '成绩',(SELECT COUNT(DISTINCT score)FROM ScoresWHERE score >= a.score) AS '排名'FROM Scores aORDER BY a.score DESC
想要自己电脑本地测试,可以用这个快速创建数据表语句:
-- 创建表CREATE TABLE Scores(Id INT,score DECIMAL(10,2));-- 插入语句INSERT INTO Scores VALUES(1,3.50),(2,3.65),(3,4.00),(4,3.85),(5,4.00),(6,3.65);
题目七:
183. 从不订购的客户(简单)
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers 表:
+----+-------+| Id | Name |+----+-------+| 1 | Joe || 2 | Henry || 3 | Sam || 4 | Max |+----+-------+
Orders 表:
+----+------------+| Id | CustomerId |+----+------------+| 1 | 3 || 2 | 1 |+----+------------+
例如给定上述表格,你的查询应返回:
+-----------+| Customers |+-----------+| Henry || Max |+-----------+
解题思路:
这道题考察的是子查询,我们想要查出没有订购过的客户,就先在订单表Orders中,查出已经订购过的客户,再在客户表Customers中排除掉这些客户,就很容易知道谁从未订购过。
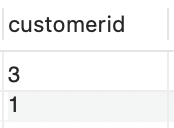
第一步:先在订单表Orders中,查出已经订购过的客户
SELECT customeridFROM orders
第二步:使用 NOT IN 查询不在此列表中的客户。
SELECT name AS '未订购客户'FROM customersWHERE id NOT IN(SELECT customeridFROM orders);
想要自己电脑本地测试,可以用这个快速创建数据表语句:
-- 创建表CREATE TABLE Customers(Id INT,Name VARCHAR(10));-- 插入语句INSERT INTO Customers VALUES(1,'Joe'),(2,'Henry'),(3,'Sam'),(4,'Max');CREATE TABLE Orders(Id INT,CustomerId INT);-- 插入语句INSERT INTO Orders VALUES(1,3),(2,1);
题目八:
184. 部门工资最高的员工(中等)
现在有两个表,员工信息表Employee 和部门表Department。
编写SQL查询,查找每个部门中薪资前三的员工。按任意顺序返回结果表。
Employee 表:
+----+--------+--------+--------------+| id | name | salary | departmentId |+----+--------+--------+--------------+| 1 | Joe | 85000 | 1 || 2 | Henry | 80000 | 2 || 3 | Sam | 60000 | 2 || 4 | Max | 90000 | 1 || 5 | Janet | 69000 | 1 || 6 | Randy | 85000 | 1 || 7 | Will | 70000 | 1 |+----+---------+---------+------------+
Department 表:
+------+---------+| id | name |+------+---------+| 1 | IT || 2 | Sales |+------+---------+
输出实例:
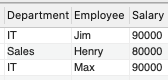
+------------+----------+--------+| Department | Employee | Salary |+------------+----------+--------+| IT | Jim | 90000 || Sales | Henry | 80000 || IT | Max | 90000 |+------------+----------+--------+
解题思路:
这道题考察的是表连接和子查询。
我们先把部门分组,查出每个部门对应的最高工资。再将这个查询结果,放在Where语句的后面,结合IN语句,查询部门名字和工资的关系。
要注意的是,一个部门可能有多个员工同时拥有最高工资,所以在子查询中不要包含雇员名字的信息。
第一步:先在员工表Employee中,对 DepartmentId 字段分组,得到每个部门工资的最大值。
SELECT DepartmentId, MAX( Salary )FROM EmployeeGROUP BY DepartmentId
第二步:
再通过DepartmentId 字段连接员工表Employee 和部门表Department,连接完成后,根据上一步查出的部门ID(DepartmentId)以及对应的最高工资,查找所有对应的所有员工的名字。
SELECTd.name AS 'Department',e.name AS 'Employee',SalaryFROM Employee eJOIN Department dON e.DepartmentId = d.IdWHERE (e.DepartmentId , Salary) IN(SELECT DepartmentId, MAX(Salary)FROM EmployeeGROUP BY DepartmentId);
想要自己电脑本地测试,可以用这个快速创建数据表语句:
-- 创建表CREATE TABLE Employee(id INT,name VARCHAR(10),salary INT,departmentId INT);-- 插入语句INSERT INTO Employee VALUES(1,'Joe',70000,1),(2,'Jim',90000,1),(3,'Henry',80000,2),(4,'Sam',60000,2),(5,'Max',90000,1);CREATE TABLE Department(id INT,name VARCHAR(20));-- 插入语句INSERT INTO Department VALUES(1,'IT'),(2,'Sales’);
知识点:
(1)聚合函数:
聚合函数,顾名思义,就是会将数据记录聚合到一起的函数。
比如原先数据库中有100条记录,用聚合函数查询这100条记录中的最大值,最后输出的只有最大值的这一条记录。
常用的聚合函数有:
MAX( ) 最大值
MIN( ) 最小值
SUM( ) 总值
AVG( ) 平均值
COUNT( ) 记录条数
(2)子查询:
SQL语句可以嵌套,最常见的就是查询语句的嵌套。我们一般称外面嵌套的语句为主查询,里面被嵌套的语句为子查询。
(3)group by分组:
GROUP BY子句是用来给结果集分组的,通常与聚合函数结合使用。