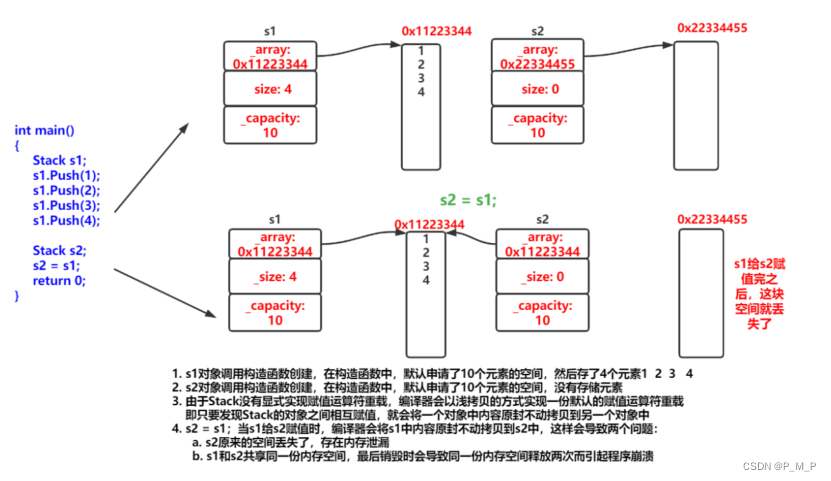
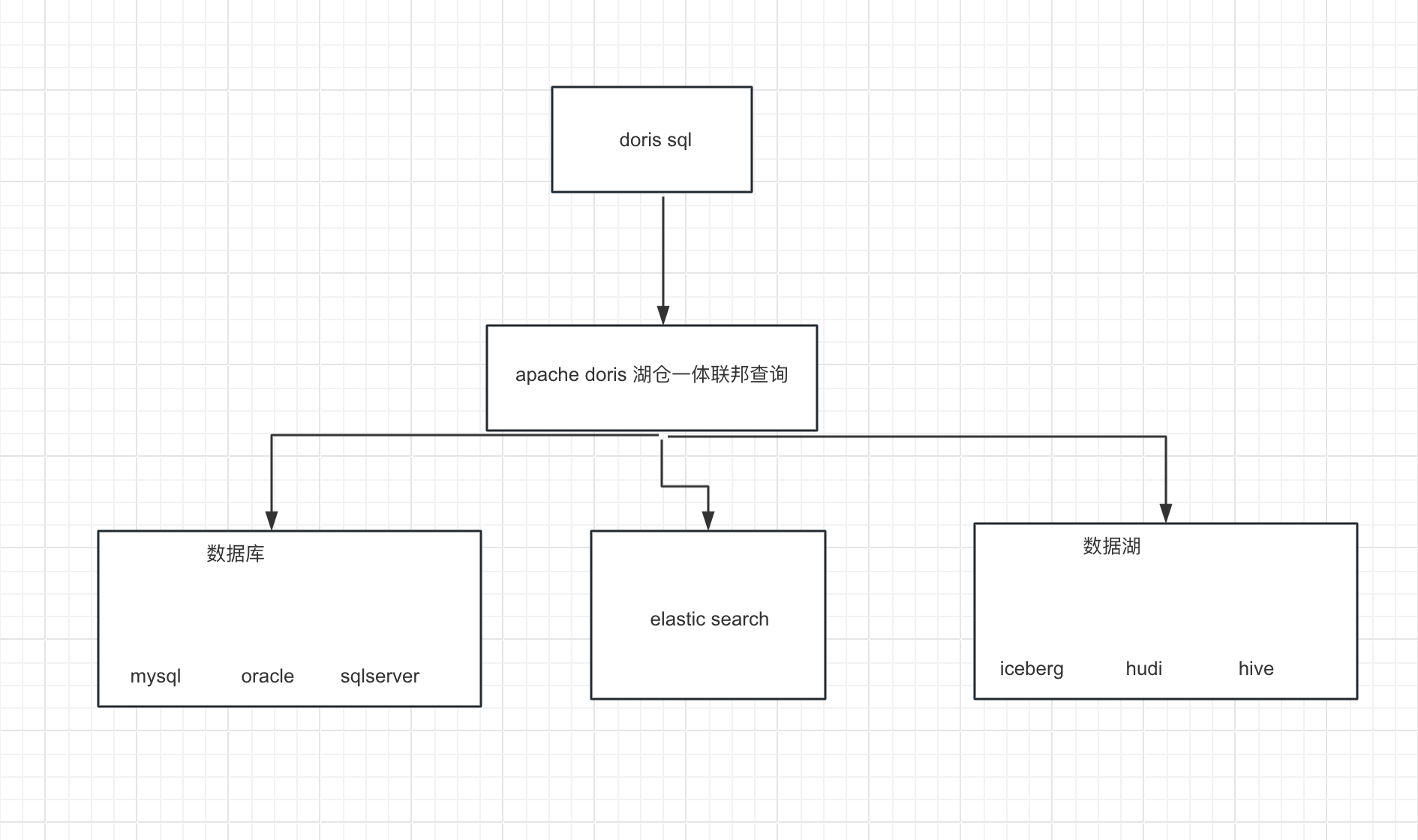
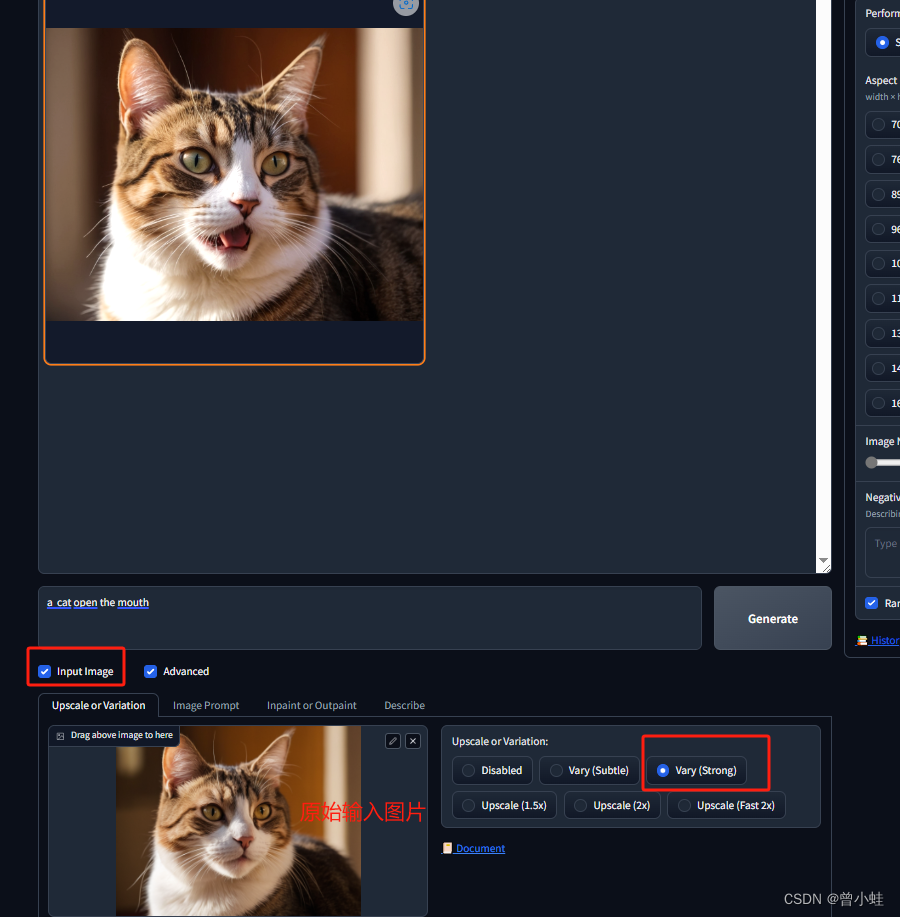
/*
引入:
学生:姓名,学号,年龄,成绩
请为学生们专门定制一个类型(创造一个类型)
结构体格式:
struct 标识符 // 标识符即自定义类型的名称
{
成员; // 自己设置
}; // 这里要注意不要漏了分号
struct Students // 定义一个学生类型
{
char name[12];
int id;
int age;
int score;
};
我们知道:
类型 变量名;
int x;
x = 10; // 赋值操作
---初始化操作 int y = 10;
那么同理:
结构化类型 结构体变量名;
struct Students stu_1;
stu_1 = {"张三", 52, 18, 616}; // 为4个成员初始化
其他内容补充:
1.访问结构体变量的成员
stu_1.name;
stu_1.id;
stu_1.age;
stu_1.score;
2.成员赋值
stu_1.name = "张三"; // 操作错误!!
正确操作为:
1.引入头文件<string.h>
2.strcpy(stu_1.name, "张三") // 作用:将后面字符串"复制到"前面
stu_1.id = 52; // 操作正确
stu_1.age = 18; // 操作正确
stu_1.score = 616; // 操作正确
*/
# include <stdio.h>
# include <string.h>
// 定义一个学生类型,类似于创造int、long...这些类型,只不过学生类型是自定义罢了
struct Students
{
char name[12];
int id;
int age;
int score;
};
int main()
{
struct Students stu_1;
stu_1.age = 18;
strcpy(stu_1.name, "张三");
printf("%s, %d\n", stu_1.name, stu_1.age);
struct Students stu_2 = { "李四", 39, 17, 553 };
printf("%s, %d\n", stu_2.name, stu_2.age);
}
# include <stdio.h>
struct Human // 定义一个 (struct)Human 类型
{
char name[12];
int age;
};
int main()
{
typedef int Myint; // 将int类型“取别名”为 Myint
int x = 1;
Myint y = 1;
printf("%d\n", x + y);
typedef struct Human hm; // 将 struct Human 类型取别名hm
hm obj_1 = { "tomato", 18 };
printf("%s %d \n", obj_1.name, obj_1.age);
return 0;
}
/*
补充:
在定义一个自定义类型的时候
往往直接当场取别名,而不是以后才取
e.g.
struct Human // 定义一个 (struct)Human 类型
{
char name[12];
int age;
}typedef hm; // 直接当场取别名为hm
*/
# include <stdio.h>
// 定义一个类型
struct Hero
{
char name[12];
int level;
}typedef hr; // 取别名
int main()
{
// 初始化
hr hero_1 = { "钢铁侠", 8 };
hr hero_2 = { "蜘蛛侠", 7 };
// 初始化
hr hero_arr[9] = {
{ "惊奇队长", 10 },
{ "美国队长", 7 },
{ "雷神", 8 },
{ "绿巨人", 9 },
// 剩下的使用默认
};
// 修改
hero_arr[0] = hero_1;
return 0;
}
/*
union语法形式如下所示:
union 名字 // union 关键字是用来定义"联合类型"
{
成员; // 见详情
}
详情:
修改一个成员的值,所有成员的值都会相应的产生变化
原因:所有成员,内存是相同的(---如何理解?)
---如何理解?
如下面代码中,num、d、ch 并不是各自独立占据一块内存,
而是先看谁最大,因为 double 占8个字节,比 int 占的4个字节
和 char 占的1个字节都要大,即 double > int > char
所以,所有的成员,即整体一共被分配了8个字节
因此,不同成员之间会出现联合占据某块内存空间的情况
而在本例中,double 占了8/8,int 占了4/8,char 占了1/8
*/
# include <stdio.h>
union HUMAN
{
int num;
double d;
char ch;
}typedef hm; // 取别名
int main()
{
hm u_1;
u_1.num = 66;
u_1.d = 10.0;
u_1.ch = 'A';
return 0;
}
# include <stdio.h> enum WEEK
{
Monday,
Tuesday,
Wednesday,
Thurday,
Friday,
Saturday,
Sunday
} ;
int main ( )
{
enum WEEK week;
week = Friday;
printf ( "星期五是>>>%d \n" , week) ;
switch ( week)
{
case Monday:
printf ( "%d \n" , week) ;
break ;
case Tuesday:
printf ( "%d \n" , week) ;
break ;
case Wednesday:
printf ( "%d \n" , week) ;
break ;
case Thurday:
printf ( "%d \n" , week) ;
break ;
case Friday:
printf ( "%d \n" , week) ;
break ;
case Saturday:
printf ( "%d \n" , week) ;
break ;
case Sunday:
printf ( "%d \n" , week) ;
break ;
default :
printf ( "不存在这样的星期" ) ;
break ;
}
return 0 ;
}
/*
---用 # 号开头的命令是预处理命令
---“预处理”即:预先处理,在编译前对代码进行一个预先处理
include <文件.h> // 这个是文件包含命令
总上所述, # include <stdio.h> 即是:执行“预处理文件包含stdio.h”
*/
/*
当 main.c 这个主文件越写越大的时候
我们可以将它其中的某些部分,通过写到其他文件的方式
来达到将代码有条理地进行布局分离的目的
从而实现高效维护和管理的目标
如下所示:
*/
/*
1. # define 宏定义命令:使用一个表示符“表示”(或者说“完全替代”)一个字符串
2. 语法:
# define 宏名 字符串
*/
# include <stdio.h>
# define unint unsigned int // 宏名的规范写法为“全大写”,即 UNINT。
# define PI 3.14f
# define NAME "tomato"
# define A num * 2 + 1
# define B (num * 2 + 1)
int main()
{
unint num = 1;
printf("圆周率%f \n", PI);
printf("我的名字%s \n", NAME);
printf("结果%d \n", 3 * A); // 结果:7
printf("结果%d \n", 3 * B); // 结果:9
//printf("", );
return 0;
}
# include <stdio.h>
# define M(x) x*x+3*x
# define P(a,b) a + b
int main()
{
int res = M(2);
printf("结果为 %d \n", res);
res = M(6);
printf("结果为 %d \n", res);
res = M(3 + 3);
printf("结果为 %d \n", res);
res = M(2 * 3);
printf("结果为 %d \n", res);
res = P(1, 2);
printf("%d \n", res);
return 0;
}
/*
运行结果——————
结果为 10
结果为 54
结果为 27
结果为 54
3
请按任意键继续. . .
*/
# include <stdio.h>
# define N(a,b) a = a ^ b; b = a ^ b; a = a ^ b; // ^ 异或,详情见底部
// 当一行内容过多的时候,可以用"\"符号实现“视觉上发生换行但代码本质还是一行”
int main()
{
int n = 9, m = 8;
printf("%d %d \n", n, m);
N(n, m);
printf("%d %d \n", n, m);
return 0;
}
/*
运行结果——————
9 8
8 9
请按任意键继续. . .
*/
/*
上面的异或原理:
打个比方a=11011,b=10101a和b做异或得到 01110
将他赋值给a,则a=01110(a=a^b,a承载着a和b的不同),接着将a(01110)和b(10101)做异或得 11011
发现就是原来a的值
于是将它赋值给b,b=11011,则b现在就是a原来的值了(b=a^b),再将a(01110)和b(11011)异或得10101
发现就是原来b的值,将它赋值给a,a=10101,则a现在就是b原来的值(a=a^b)
这样就实现了互换a和b的值
*/
# include <stdio.h>
# define STR(s) #s
# define NUM1(a,b) a##e##b // 连接成aeb
# define NUM2(a,b) a##b##99 // 连接成ab99
int main()
{
printf("%s \n", "abc123");
printf("%s \n", STR("abc123"));
printf("%s \n", STR(abc123));
printf("%f \n", NUM1(1.23, 3)); // 连接成aeb,即 1.23e3 => 1.23 * 1000
printf("%d \n", NUM2(12, 5)); // 连接成ab99,即 12599
return 0;
}
/*
运行结果——————
abc123
"abc123"
abc123
1230.000000
12599
请按任意键继续. . .
*/
/*
上面的异或原理:
打个比方a=11011,b=10101a和b做异或得到 01110
将他赋值给a,则a=01110(a=a^b,a承载着a和b的不同),接着将a(01110)和b(10101)做异或得 11011
发现就是原来a的值
于是将它赋值给b,b=11011,则b现在就是a原来的值了(b=a^b),再将a(01110)和b(11011)异或得10101
发现就是原来b的值,将它赋值给a,a=10101,则a现在就是b原来的值(a=a^b)
这样就实现了互换a和b的值
*/
# include <stdio.h>
/*
条件编译(多种类型)
1. #if ... #endif (可以穿插 #elif、#else)
2. #ifdef ... #endif (可以穿插 #else)
3. #ifndef ... #endif (可以穿插 #else)
*/
# define NAME // 对 NAME 进行宏定义,定义完成后,NAME就是宏名
int main()
{
# if 1 - 1
printf("My name is %s.\n", "tomato");
# elif 0
printf("My name is %s.\n", "banana");
# else
printf("My name is %s.\n", "apple");
# endif
# ifdef NAME // 判断 NAME 是否为宏名,即是否进行了宏定义
printf("111 \n");
# endif
# ifndef NAME // if-not-def
printf("222 \n");
# endif
return 0;
}
/*
使用场景:
我们在 main.c 文件中编写代码时,
有可能因为精神疲劳,而不小心造成错误
例如:
不小心引入了多次头文件<xxx.h>而导致出现“重定义”的情况
我们如何解决这个问题?(下面有两个解决方案)
方案1-----删除多余“引入头文件”的代码
方案2-----我们能否在头文件上面做些手脚?使得它不论引入多少次,都只会执行一次。
*/
// 下面是头文件里面的代码
// 我们通过“条件编译”的知识来实现“方案2”
#ifndef MYFILE_H // 判断:MYFILE_H 没有被定义?(ifndef => if-not-def)
#define MYFILE_H
struct Mystruct
{
int num;
};
#endif // 如果 #ifndef 的判断结果为‘错’,将跳到这行,直接结束
# include <stdio.h> int func_1 ( ) ;
int main ( )
{
FILE file;
func_1 ( ) ;
return 0 ;
}
int func_1 ( )
{
FILE* file = NULL ;
file = fopen ( "/test.txt" , "r" ) ;
char ch = 0 ;
ch = fgetc ( file) ;
printf ( "%c \n" , ch) ;
putchar ( ch) ;
fclose ( file) ;
file = NULL ;
file = fopen ( "test.txt" , 'w' ) ;
fputc ( 'M' , file) ;
fclose ( file) ;
file = NULL ;
}


![[文本挖掘和知识发现] 03.基于大连理工情感词典的情感分析和情绪计算](https://img-blog.csdnimg.cn/20200809125022536.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Vhc3Rtb3VudA==,size_16,color_FFFFFF,t_70#pic_center)