DBMS存储空间管理
- 概述
- 块(或页面)
- PageHeaderData 结构体
- HeapTupleHeaderData 结构
- 表空间
- 表空间的作用:
- 表空间和数据库关系
- 表空间执行案例
- 补充 —— 模式(Schema)
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-10.1 的开源代码和《OpenGauss数据库源码解析》和《PostgresSQL数据库内核分析》一书以及一些相关资料。
概述
在数据库管理系统(DBMS)中,空间管理是指如何在物理存储介质上组织、管理和优化数据的存储。这是 DBMS 性能和效率的关键因素之一。空间管理通常涉及以下概念:块(或页面)、区间(区域或范围)、段、表空间和数据库。下面详细解释这些概念:
- 块(或页面)
块(在 Oracle 中称为块,在 SQL Server 和 PostgreSQL 中称为页面)是数据库管理系统存储数据的基本单位。一个块通常是从磁盘上以固定大小读取和写入的数据块,这个大小可以是 2KB、4KB、8KB 等,根据数据库的配置而定。每个块包含了一系列的记录,这些记录是数据库中存储的实际数据。 - 区间(Extents)
区间是一系列连续的块。当表或索引等数据库对象需要更多空间时,DBMS 会分配一个或多个区间。每个区间包含固定数量的块。区间使得数据库对象能在物理上连续存储,从而提高访问速度。 - 段
段是一个或多个区间的集合,通常用于存储特定类型的数据库对象,如表、索引或回滚数据。段内的空间管理旨在优化数据存储和访问性能。当一个段的现有区间被填满时,数据库会分配新的区间以供进一步的数据存储。 - 表空间
表空间是数据库中存储数据的逻辑容器,它将数据文件与数据库的物理结构分离。一个数据库可以包含多个表空间,每个表空间由一个或多个数据文件组成。表空间允许数据库管理员管理数据库的存储结构,例如,通过指定特定的表或索引应该存储在哪个表空间中,或者通过为特定的表空间分配更多的磁盘空间。 - 数据库
数据库是最高级别的存储结构,包含了所有的表空间、段、区间和块。它是所有数据库对象和数据的逻辑集合,由多个物理文件(如数据文件、日志文件等)支持。数据库的设计和结构反映了如何在整个系统中组织和管理数据。
在 DBMS 中,这些概念共同工作,形成了一个复杂的存储管理框架,旨在优化数据存取性能、提高数据管理的灵活性以及确保数据的完整性和安全性。通过有效地管理空间,DBMS 能够支持大规模的数据存储,同时保持良好的性能和高效的数据访问速度。
块(或页面)
在 PostgreSQL 中,表数据存储在称为页(pages)或块(blocks)的结构中,每个页的大小通常是 8KB。下图是 page 的整体结构图:(图片来源:这一次终于把PostgreSQL Page结构搞懂了)
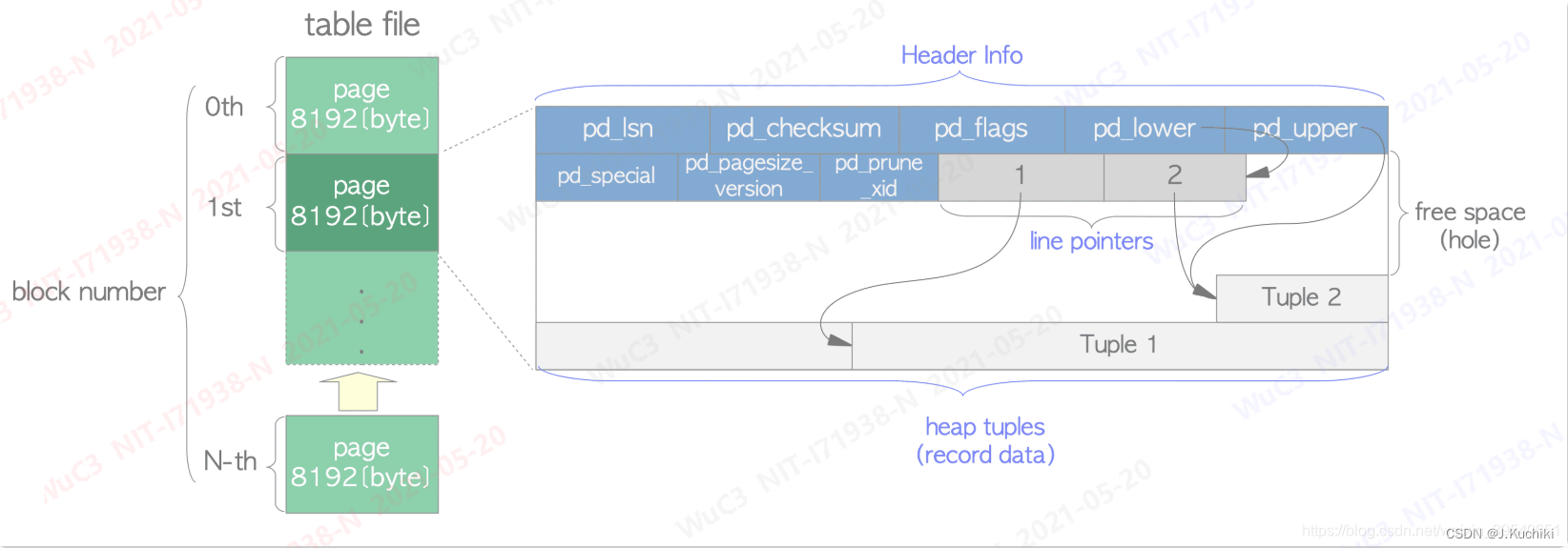
下面是对图中的各个组成部分的解释:(更多详细信息可以参考 Postgresql手册)
- 表文件: 表数据存储在多个连续的页或块中,这些页按块编号顺序存储在文件系统中。图中显示了第 0 个(0th)、第 1 个(1st)和第 N 个(N-th)页,意味着这是一个表文件的序列。
- 页(Page): 每个页的大小是 8192 字节(8KB)。这是 PostgreSQL 中默认的页大小,虽然在编译时可以配置为其他大小。
- 页头信息(Header Info): 每个页的开始部分是页头信息,包含以下字段:
• pd_lsn: 日志序列号(Log Sequence Number),记录了最后一次修改该页的事务日志位置。
• pd_checksum: 页的校验和,用于检测数据损坏。
• pd_flags: 页的标志,表明页的状态或属性。
• pd_pagesize_version: 包含页大小和版本信息。
• pd_special: 指向页中特殊数据区域的指针。
• pd_prune_xid: 可以修剪该页的最小事务ID。
• pd_lower: 指向该页中第一个空闲空间的指针。
• pd_upper: 指向该页中最后一个空闲空间的指针。 - 行指针(Line Pointers): 页头之后是一系列的行指针,它们指向页内部的各个记录(也称为元组或 tuple)。这些行指针是排序的,行指针 1 指向第一个元组,行指针 2 指向第二个元组,以此类推。
- 元组(Tuples): 元组是实际存储记录(record data)的地方,即表中的一行。图中显示了两个元组,元组 1 和元组 2。
- 空闲空间(Free Space / Hole): 页中未被使用的部分称为空闲空间或洞(hole)。当页中的数据被删除或更新时,可能会在页中产生空闲空间。
在 PostgreSQL 中,页(或块)是表数据存储的基本单位。每次数据插入或更新时,数据都被写入这些页中。数据库管理系统会管理这些页的分配和回收,以有效利用存储空间。图中的表示是一个典型的 PostgreSQL 数据页的抽象表示,它展示了如何在页中组织数据。
PageHeaderData 结构体
下面我么来看一下 PageHeaderData 结构体,一个数据库页可以包含多个元组。PageHeaderData 负责管理页级别的信息,包括页中有多少空间可用,以及元组在页中的位置。
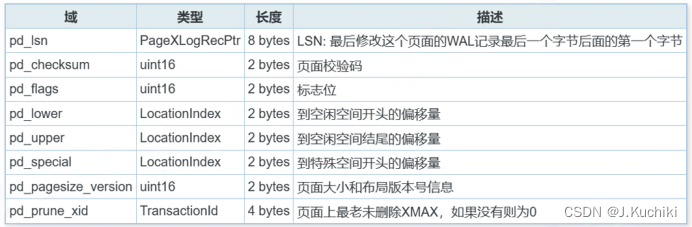
PageHeaderData 结构体用于表示 PostgreSQL 数据库中的页头。它包含了一系列的元数据字段,用于描述页(或块)的状态和内容。其结构体源码如下所示:(路径:src\include\storage\bufpage.h)
typedef struct PageHeaderData
{
/* LSN 是 *任何* 块的成员,不仅仅是页组织的块 */
PageXLogRecPtr pd_lsn; /* 日志序列号(LSN):最后一次更改此页的xlog记录的下一个字节 */
uint16 pd_checksum; /* 页校验和 */
uint16 pd_flags; /* 标志位,具体含义见下文 */
LocationIndex pd_lower; /* 自由空间开始的偏移量 */
LocationIndex pd_upper; /* 自由空间结束的偏移量 */
LocationIndex pd_special; /* 特殊空间开始的偏移量 */
uint16 pd_pagesize_version; /* 页大小和页布局版本号 */
TransactionId pd_prune_xid; /* 最老的可裁剪事务ID,如果没有则为零 */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* 行指针数组 */
} PageHeaderData;
HeapTupleHeaderData 结构
页中的每个元组都有一个 HeapTupleHeaderData 结构,这个结构跟踪了与该元组相关的特定信息,例如元组的事务可见性信息,元组的长度,以及元组中哪些列是空值。当数据库需要读取或写入一行数据时,它会先查找包含该行的页,然后使用 PageHeaderData 中的信息找到该页中的具体元组位置,最后读取或更新该元组的 HeapTupleHeaderData 以及它后面的实际数据。
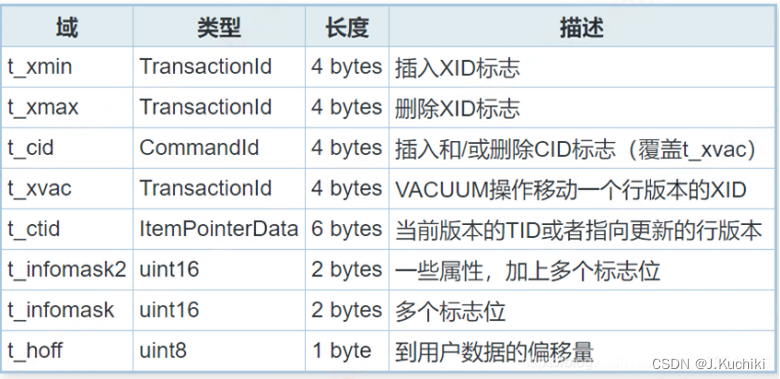
简而言之,PageHeaderData 用于管理页级别的结构和空间,而 HeapTupleHeaderData 用于管理页内单个元组级别的结构和元数据。两者结合起来允许 PostgreSQL 管理和维护表中行的存储和检索。HeapTupleHeaderData 结构体源码如下所示:(路径:src\include\access\htup_details.h)
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap; /* 如果是一个普通的元组,则使用此结构 */
DatumTupleFields t_datum; /* 如果是一个只有一个数据项的元组(比如返回函数结果),则使用此结构 */
} t_choice; /* 用于存储元组的不同数据类型 */
ItemPointerData t_ctid; /* 当前元组的元组标识符(TID),或者新元组的TID,
* 或者是一个推测性插入的标识 */
/* 以下字段必须与MinimalTupleData结构匹配! */
uint16 t_infomask2; /* 属性数量加上各种标志位 */
uint16 t_infomask; /* 各种标志位,详细内容见下文 */
uint8 t_hoff; /* 包括位图、填充在内的头部大小 */
/* ^ - 23 字节 - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* 用于表示NULL值的位图 */
/* 结构体末尾还有更多数据 */
};
解释一些关键部分:
- t_choice 字段是一个联合体(union),它根据元组的使用上下文存储不同的数据。如果元组是表的一部分,它会使用 t_heap;如果元组是一个单独的数据项,它会使用 t_datum。
- t_ctid 是一个 ItemPointerData 类型,用来存储当前元组的位置信息。这个位置可以是元组在表中的实际位置,或者在某些情况下(例如,一个尚未提交的插入操作),它可能是一个推测性插入的标记。
- t_infomask2 和 t_infomask 是两个掩码字段,包含了元组的元数据,比如属性数量、是否有空值等。
- t_hoff 是头部的大小,包括任何位图和必要的填充。
- t_bits 是一个位图,用来表示元组中每个属性是否为 NULL。这个数组是可伸缩的,其大小取决于表的属性数量。
详细信息参考下表(更多详细信息可以参考 Postgresql手册)
表空间
表空间是 PostgreSQL 中数据文件的物理存储位置。它允许数据库管理员定义数据库对象在磁盘上的存储位置。每个表空间可以指向文件系统中的一个目录,不同的数据库对象(如表和索引)可以存储在不同的表空间中。
表空间概念与数据库关系如下图所示:(图片来源:地址)

上图显示了 PostgreSQL 数据库集群的物理存储布局。图中展示了 PostgreSQL 数据库集群(Database Cluster)如何组织,以及数据在文件系统中的存储方式。图中的布局说明了 PostgreSQL 数据库集群的层次性和模块化设计。它允许多个数据库独立存在于同一个数据库集群中,每个数据库可以有自己的表空间、用户和权限设置。同时,通过 PGDATA 和表空间的物理路径,数据库管理员可以在文件系统级别管理和优化数据存储。以下是每个组件的详细解释:
- Database Cluster(数据库集群):
- 这是最外层的绿色虚线框,代表 PostgreSQL 的数据库集群。数据库集群是指一个 PostgreSQL 服务实例,它可以包含多个数据库。
- PGDATA/:
- 这个文件夹代表 PostgreSQL 的数据目录,通常环境变量 PGDATA 指向这个位置。这个目录包含了所有数据库文件、配置文件(如 postgresql.conf 和 pg_hba.conf)、WAL 日志等。
- template0:
- 这是 PostgreSQL 中的一个特殊数据库,作为创建新数据库的模板。它是只读的,以防止用户更改可能会影响新数据库创建的设置。
- newdb1 和 newdb2:
- 这些代表在数据库集群中创建的用户数据库。每个数据库都有自己的用户和表集合,这些都被存储在数据库对应的文件和目录中。
- tablespace/:
- 这个文件夹代表一个表空间目录,PostgreSQL 中的表空间允许数据库管理员定义数据文件在文件系统中的存储位置。用户可以创建多个表空间来组织数据文件的物理存储。
- 数据库对象:
- 图中的蓝色圆柱代表数据库对象,如表和索引。图中的网格状图标代表表。
表空间的作用:
表空间是数据库中的一个逻辑存储单位,它定义了数据在底层文件系统中的存储位置,使得数据库管理员能够有效地组织和管理数据文件。通过将数据分配到不同的表空间,管理员可以优化数据库性能,实现灵活的存储管理,提高数据安全性,以及更容易地进行数据库的备份与恢复。表空间的使用还允许进行细粒度的数据隔离和容量规划,它们是数据库架构中关键的元素,尤其在大型、分布式或高性能的数据库系统中扮演着至关重要的角色。
在 PostgreSQL 中,利用表空间,管理员可以细致地规划和调整数据库的磁盘布局。首先,当数据库的默认存储位置因为空间耗尽而无法扩展时,表空间可以创建在其他分区,为系统的维护和扩展提供了灵活性。其次,表空间使得管理员能够根据数据库对象的实际访问和性能需求进行调优,例如,将高频访问的索引放置在快速的存储介质上,而将低频访问的档案数据放置在成本较低的存储解决方案上。
执行\db可以查看表空间:
postgres=# \db
List of tablespaces
Name | Owner | Location
------------+---------+----------
pg_default | kuchiki |
pg_global | kuchiki |
(2 rows)
pg_default 和 pg_global 是两个预定义的表空间,它们有特定的用途和作用:
pg_default 表空间
pg_default 是 PostgreSQL 中默认的表空间。如果在创建数据库对象(如表或索引)时未指定特定的表空间,这些对象会默认存储在 pg_default 表空间中。实际上,如果你创建一个数据库而不指定表空间,它也会被创建在 pg_default 表空间。这个表空间通常位于 PostgreSQL 数据目录的基础路径下,也就是 PGDATA/base 目录。
pg_global 表空间
pg_global 表空间用于存储跨越整个数据库集群(或实例)的全局数据,例如共享的系统目录。这些数据不属于特定数据库,而是对整个 PostgreSQL 实例的所有数据库可见。pg_global 包含了一些全局表,这些表对所有数据库都很重要,比如存储用户信息和权限的表。pg_global 通常位于 PGDATA/global 目录。
表空间和数据库关系
下面描绘了从 PostgreSQL 的系统目录 pg_catalog.pg_database 中检索数据库的相关信息。pg_catalog.pg_database 是一个系统表,包含了 PostgreSQL 实例中所有数据库的元数据。
postgres=# select oid, datname, datlastsysoid, dattablespace from pg_catalog.pg_database;
oid | datname | datlastsysoid | dattablespace
-------+-----------+---------------+---------------
1 | template1 | 15093 | 1663
15093 | template0 | 15093 | 1663
15098 | postgres | 15093 | 1663
(3 rows)
下面这条 SQL 命令从 pg_catalog.pg_tablespace 系统目录中查询了所有表空间的信息。
postgres=# select oid,* from pg_catalog.pg_tablespace;
oid | spcname | spcowner | spcacl | spcoptions | spcmaxsize | relative
------+------------+----------+--------+------------+------------+----------
1663 | pg_default | 10 | | | | f
1664 | pg_global | 10 | | | | f
(2 rows)
其中,spcowner 为表空间的所有者,用其用户的 OID 表示。在这个例子中,OID 为 10 的用户是这两个表空间的所有者。OID 10 通常是初始设置的超级用户,如 postgres。spcacl 为访问控制列表,定义了哪些用户和角色拥有该表空间的访问权限。spcoptions 为表空间的其他选项。spcmaxsize 为表空间的最大大小,这里为空,意味着没有设置最大大小限制。relative 这个字段标识表空间路径是否是相对于 PostgreSQL 数据目录的。这里的 ‘f’ 表示 “false”,意味着这些表空间的路径是绝对路径,不是相对于 PostgreSQL 数据目录的。
在 PostgreSQL 中,表空间(Tablespace)是存储数据的物理位置,而数据库(Database)是存储和组织数据的逻辑容器。从查询结果来看,所有列出的数据库(template1、template0 和 postgres)默认使用同一个表空间 OID 1663,即 pg_default,来存储它们的数据。这表明在这个实例中,所有用户定义的数据和对象默认存储在 pg_default 表空间,而 pg_global 表空间(OID 1664)是用来存储全局数据,如跨数据库的共享目录。这样的设计允许数据库管理员在必要时将数据库对象的物理存储与数据库逻辑结构分离,从而提供了更大的灵活性和对磁盘布局的控制。
查看表的存储路径与大小如下所示:
postgres=# select pg_size_pretty(pg_relation_size('test'));
pg_size_pretty
----------------
8192 bytes
(1 row)
表空间执行案例
- 创建表空间
-- 创建一个名为 test_tablespace 的表空间,指向一个真实存在的目录
CREATE TABLESPACE test_tablespace LOCATION '/path/to/test_tablespace_directory';
-- 请确保 /path/to/test_tablespace_directory 路径存在,且 PostgreSQL 服务有权限读写该路径。
postgres=# CREATE TABLESPACE test_tablespace LOCATION '/home/kuchiki/tablespace';
CREATE TABLESPACE
postgres=# select oid,* from pg_catalog.pg_tablespace;
oid | spcname | spcowner | spcacl | spcoptions | spcmaxsize | relative
-------+-----------------+----------+--------+------------+------------+----------
1663 | pg_default | 10 | | | | f
1664 | pg_global | 10 | | | | f
32784 | test_tablespace | 10 | | | | f
(3 rows)
2. 在新创建的表空间中创建一个表并插入数据
postgres=# CREATE TABLE test (
postgres(# id SERIAL PRIMARY KEY,
postgres(# data TEXT
postgres(# ) TABLESPACE test_tablespace;
NOTICE: CREATE TABLE will create implicit sequence "test_id_seq" for serial column "test.id"
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "test_pkey" for table "test"
CREATE TABLE
postgres=# INSERT INTO test (data) VALUES ('Sample data 1'), ('Sample data 2'), ('Sample data 3');
INSERT 0 3
postgres=# SELECT * FROM test;
id | data
----+---------------
1 | Sample data 1
2 | Sample data 2
3 | Sample data 3
(3 rows)
查看 test 表的 oid:
postgres=# SELECT oid, relname AS table_name
postgres-# FROM pg_class
postgres-# WHERE relname = 'test';
oid | table_name
-------+------------
32798 | test
(1 row)
在新建的表空间下查询到对应的 test 表 oid:
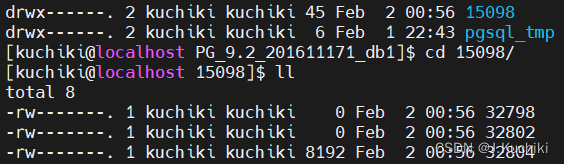
插入数据后可以看到表空间大小变大:

查看一下 32802 和 32804 对应的是什么表?
postgres=# SELECT relname AS table_name
postgres-# FROM pg_class
postgres-# WHERE oid = 32802;
table_name
----------------
pg_toast_32798
(1 row)
postgres=# SELECT relname AS table_name
FROM pg_class
WHERE oid = 32804;
table_name
----------------------
pg_toast_32798_index
(1 row)
这里 pg_toast_32798 和 pg_toast_32798_index 分别是什么呢?下面来解释一下:
在 PostgreSQL 中,当你创建一个新表(例如 test 表)时,除了表本身对应的 OID 外,你可能还会注意到与该表相关的其他几个 OID 出现在系统目录中。这些通常与 TOAST 机制有关。对于你提到的 pg_toast_32798 和 pg_toast_32798_index,它们分别代表 TOAST 表和 TOAST 表的索引。
注:TOAST (The Oversized-Attribute Storage Technique)
TOAST 是 PostgreSQL 用来处理大数据字段(如 TEXT、BYTEA)的一种机制。当一个表的行中包含的数据超过页面大小(默认为 8KB)时,PostgreSQL 会使用 TOAST 来压缩和/或分割这些大字段,将它们存储在一个专门的 TOAST 表中。这样做的目的是为了提高存储效率和查询性能。
pg_toast_32798 是针对 test 表自动生成的 TOAST 表,用于存储 test 表中超过页面大小的大型字段数据。32798 是 test 表的 OID,而 pg_toast_32798 使用这个 OID 来确保 TOAST 表的名称是唯一的。TOAST 表本身就像普通的 PostgreSQL 表,但它是系统自动管理的,通常用户不需要直接与之交互。
pg_toast_32798_index 是 pg_toast_32798 TOAST 表的索引,用于快速定位和检索 TOAST 表中的数据。这个索引同样是系统自动生成的,目的是优化对 TOAST 表数据的访问。索引的 OID(在这个例子中是 32804)与 TOAST 表的 OID 相关联,确保索引的唯一性。
- 删除表
执行drop table test;后可以观察到表空间清零;

- 删除表空间
执行DROP TABLESPACE test_tablespace;后可以观察到表空间被删除;

补充 —— 模式(Schema)
数据库中的模式(Schema)是定义和组织数据库内部数据结构的逻辑框架,它包含了一组数据库对象,如表、视图、索引和函数等。模式的作用在于提供了一种方式来逻辑上对数据库对象进行分组和管理,使得数据组织更为清晰,同时支持对数据访问的细粒度控制。通过使用模式,可以在同一数据库内创建隔离的环境,以便不同的用户或应用可以在不相互干扰的情况下操作自己的数据集合,这对于多用户数据库系统尤为重要。此外,模式也是数据库设计的一个关键组成部分,有助于实现数据的逻辑结构规划,确保数据完整性和安全性,以及简化数据库的维护和管理工作。
postgres=# \dn
List of schemas
Name | Owner
-------------+---------
cstore | kuchiki
dbe_perf | kuchiki
pkg_service | kuchiki
public | kuchiki
snapshot | kuchiki
(5 rows)
这个 PostgreSQL 命令 \dn 的输出显示了数据库中存在的模式(Schema)列表及其所有者。在给出的输出中,列出了五个不同的模式,以及每个模式的所有者。这里的所有者是 kuchiki(本人),这意味着 kuchiki 用户拥有这些模式,并且有权限对它们进行管理和操作。此外:
- cstore: 用于特定的存储或应用,与列存储有关。
- dbe_perf: 这个模式的表示它与数据库性能(Database Performance)相关,用于存储性能测试或监控数据。
- pkg_service: 这个模式用于某种服务或包管理。
- public: PostgreSQL 默认创建的模式,所有用户默认都有访问这个模式的权限。通常,如果没有指定模式,对象会被创建在 public 模式下。
- snapshot: 这个模式用于保存数据库的快照或某种形式的备份数据。
与模式相关的详细内容可以查看这篇文章:【PG】PostgreSQL 模式(Schema)。