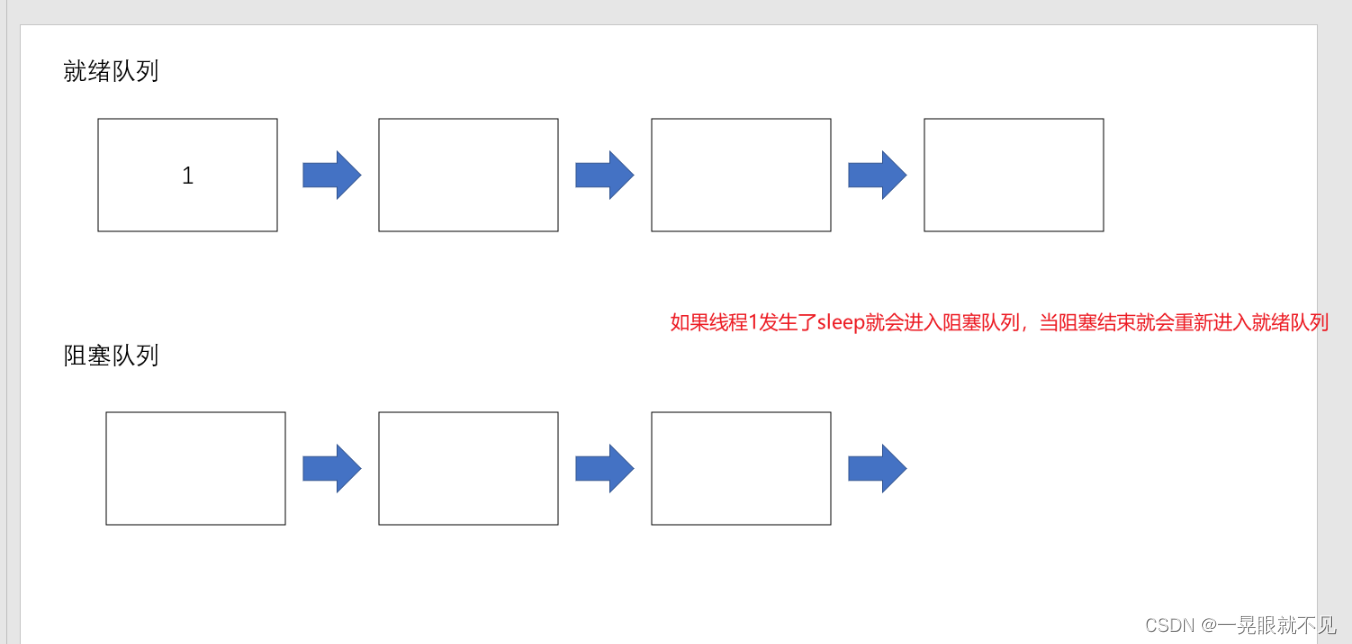
问题:使用Keras做分类任务,model.predict预测得到的值为每个类别的概率值,而不是类别。
源码:
y_test_pred = model.predict(x_test, batch_size=256, verbose=1)
解决:
import numpy as np
y_test_pred = model.predict(x_test, batch_size=256, verbose=1)
y_test_pred = np.argmax(y_test_pred, axis=1)
注意:axis值为你要转换的行,而且输出为一维数据,即每个样本对应一个类别值。
总结:
Keras框架能使用的函数是predict和predict_classes;Sklearn中能使用的函数是predict和predict_proba。
predict函数:
1.训练后返回一个概率值数组,此数组的大小为n·k,第i行第j列上对应的数值代表模型对此样本属于某类标签的概率值,行和为1。例如预测结果为:[[0.66651809 0.53348191],代表预测样本的标签是0的概率为0.66651809,1的概率为0.53348191。
2.输出预测值很简单,只需要在括号内加入处理好的数据集。
pt = predict(test)
output:
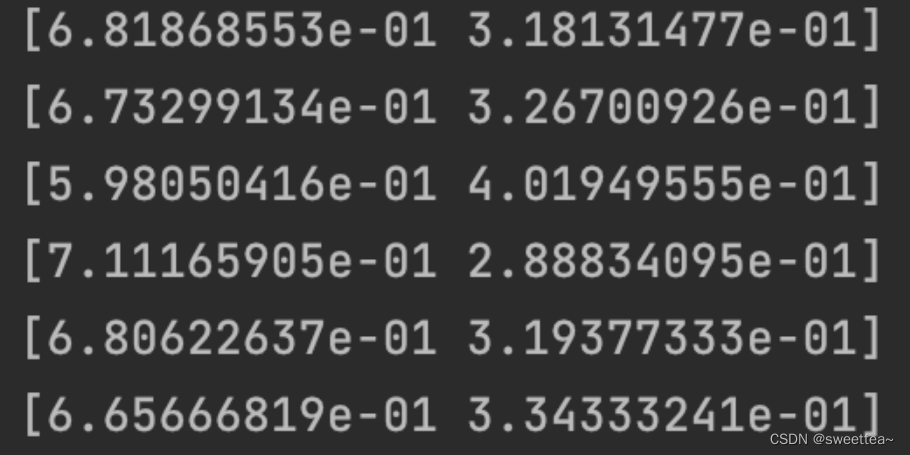
3.将预测值转换为0/1值,方法有两种,第一种是使用predict_classes直接输出标签值,第二种是用Numpy转换一下,具体操作如下:
print(np.argmax(pt, axis=1))
output:

注意:
本人在实际操作时发现,使用predict_classes()会出现报错:'Model' object has no attribute 'predict_classes'。这是因为本系统在搭建模型时,先进行了神经网络的编写,之后使用model = Model(input=inp, output=outp)方法,此时这种综合起来的方法无法使用predict_classes(),所以需要配合numpy.argmax()方法将样本最大概率归属类别的值转化为样本的预测数组。
![[ctf.show pwn] 新手杯,七夕杯](https://img-blog.csdnimg.cn/img_convert/86a2d8e10ef011a24ca0bf675f169e5b.png)