文章目录
- 5.1 数据合并:Concatenate 和 Merge
- 5.1.1 基础知识
- 5.1.2 重点案例:客户订单数据合并
- 5.1.3 拓展案例一:产品目录和销售数据合并
- 5.1.4 拓展案例二:员工信息和部门数据合并
- 5.2 数据透视和重塑
- 5.2.1 基础知识
- 5.2.2 重点案例:销售数据透视
- 5.2.3 拓展案例一:员工工时记录重塑
- 5.2.4 拓展案例二:客户反馈调查结果聚合
- 5.3 分组与聚合操作
- 5.3.1 基础知识
- 5.3.2 重点案例:电商销售数据分析
- 5.3.3 拓展案例一:员工绩效评分统计
- 5.3.4 拓展案例二:客户反馈分析
5.1 数据合并:Concatenate 和 Merge
合并数据是数据分析中的一项基本技能,它允许我们将不同来源的数据集整合在一起,以进行更全面的分析。
5.1.1 基础知识
- Concatenate: 使用
pd.concat()可以沿着一条轴将多个对象堆叠到一起。适用于结构相同的数据框架合并。 - Merge: 使用
pd.merge()根据一个或多个键将不同的数据集的行连接起来。类似于 SQL 中的 JOIN 操作。
5.1.2 重点案例:客户订单数据合并
假设你有两个数据集,一个包含客户的基本信息,另一个包含客户的订单信息,你需要将这两个数据集合并在一起。
数据准备
import pandas as pd
# 示例客户基本信息数据
customers_data = {
'customer_id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie']
}
customers_df = pd.DataFrame(customers_data)
# 示例订单信息数据
orders_data = {
'order_id': ['A001', 'A002', 'A003'],
'customer_id': [3, 1, 2],
'order_value': [200, 150, 50]
}
orders_df = pd.DataFrame(orders_data)
合并数据
# 合并客户信息和订单信息
merged_df = pd.merge(customers_df, orders_df, on='customer_id')
5.1.3 拓展案例一:产品目录和销售数据合并
假设你有一个产品目录数据集和一个销售记录数据集,你需要将它们合并以分析每个产品的销售情况。
数据准备
# 示例产品目录数据
catalog_data = {
'product_id': [101, 102, 103],
'product_name': ['Product A', 'Product B', 'Product C']
}
catalog_df = pd.DataFrame(catalog_data)
# 示例销售记录数据
sales_data = {
'sale_id': ['S001', 'S002', 'S003'],
'product_id': [102, 103, 101],
'units_sold': [3, 2, 5]
}
sales_df = pd.DataFrame(sales_data)
合并数据
# 合并产品目录和销售记录
merged_sales_df = pd.merge(catalog_df, sales_df, on='product_id')
5.1.4 拓展案例二:员工信息和部门数据合并
如果你有员工信息的数据集和部门信息的数据集,需要合并它们来分析每个部门的员工分布。
数据准备
# 示例员工信息数据
employees_data = {
'employee_id': ['E01', 'E02', 'E03'],
'employee_name': ['Emily', 'Dan', 'Sarah'],
'department_id': ['D01', 'D02', 'D01']
}
employees_df = pd.DataFrame(employees_data)
# 示例部门信息数据
departments_data = {
'department_id': ['D01', 'D02'],
'department_name': ['HR', 'Tech']
}
departments_df = pd.DataFrame(departments_data)
合并数据
# 合并员工信息和部门信息
merged_employees_df = pd.merge(employees_df, departments_df, on='department_id')
通过这些案例,我们展示了如何使用 Pandas 的 concat() 和 merge() 方法来合并数据。这些操作是数据预处理和分析中不可或缺的步骤,无论是合并客户订单数据、产品销售数据还是员工部门数据。

5.2 数据透视和重塑
数据透视和重塑是数据分析中的强大工具,允许我们重新组织数据,以便更好地分析和可视化。
5.2.1 基础知识
- Pivot: 使用
pivot()方法可以重塑数据,并根据给定的索引/列值重新组织数据。 - Melt:
melt()方法用于将宽格式数据转换为长格式数据,是pivot()的反向操作。 - Pivot Table:
pivot_table()是pivot()的扩展,支持对数据进行聚合。
5.2.2 重点案例:销售数据透视
假设你有一份销售数据,包含多个产品在不同月份的销售情况,你需要将数据透视,以便分析每个产品的销售趋势。
数据准备
import pandas as pd
# 示例销售数据
sales_data = {
'month': ['January', 'February', 'January', 'February'],
'product': ['A', 'A', 'B', 'B'],
'sales': [100, 150, 200, 250]
}
sales_df = pd.DataFrame(sales_data)
数据透视
# 将数据透视,以月份为列展示每个产品的销售情况
pivot_sales_df = sales_df.pivot(index='product', columns='month', values='sales')
5.2.3 拓展案例一:员工工时记录重塑
处理一份员工每日工时的记录,需要将数据从长格式转换为宽格式,以便更好地分析员工的工作时间。
数据准备
# 示例员工工时数据
time_data = {
'employee': ['Alice', 'Bob', 'Alice', 'Bob'],
'date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'hours_worked': [8, 9, 7, 8]
}
time_df = pd.DataFrame(time_data)
重塑数据
# 将数据重塑为宽格式,显示每个员工每天的工时
pivot_time_df = time_df.pivot(index='date', columns='employee', values='hours_worked')
5.2.4 拓展案例二:客户反馈调查结果聚合
假设你有一份客户反馈调查的数据,包含客户对不同问题的评分,需要对数据进行聚合以分析平均评分。
数据准备
# 示例客户反馈数据
feedback_data = {
'customer_id': [1, 1, 2, 2],
'question': ['Service', 'Quality', 'Service', 'Quality'],
'rating': [4, 5, 3, 4]
}
feedback_df = pd.DataFrame(feedback_data)
创建数据透视表
# 创建数据透视表,计算每个问题的平均评分
pivot_feedback_df = feedback_df.pivot_table(index='question', values='rating', aggfunc='mean')
通过这些案例,我们展示了如何使用 Pandas 的数据透视和重塑功能来改变数据的组织方式。无论是分析销售趋势、员工工时还是客户反馈,这些技巧都能帮助你从数据中获得更深入的洞见。

5.3 分组与聚合操作
分组与聚合是数据分析中的核心操作,它们允许我们对数据集进行分段,并对每个段应用汇总统计,以便进行比较和模式识别。
5.3.1 基础知识
- GroupBy: 使用
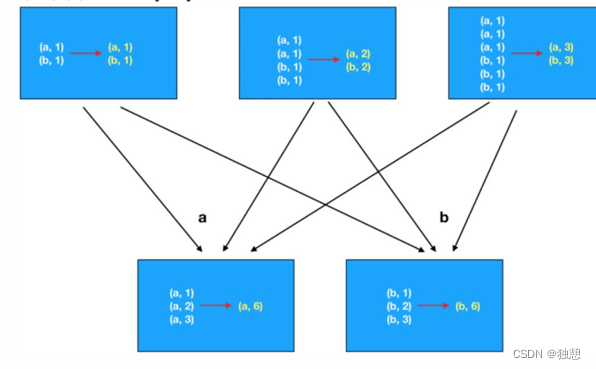
groupby()方法可以根据某个或某些列的值将数据分组。这对于分析子集内的统计数据非常有用。 - 聚合函数: 一旦数据被分组,就可以对分组应用多种聚合函数,如
sum()、mean()、max()、min()等,来计算统计数据。 - Transform:
transform()方法可以用来对分组数据应用一个函数,而且返回的对象与原始数据大小相同。 - Filter:
filter()方法允许你根据布尔条件过滤数据,对于去除或保留某些组非常有用。
5.3.2 重点案例:电商销售数据分析
假设你正在处理一份电商平台的销售数据,需要分析每个产品类别的总销售额。
数据准备
import pandas as pd
# 示例电商销售数据
ecommerce_data = {
'category': ['Electronics', 'Clothing', 'Home & Garden', 'Electronics', 'Clothing'],
'sales': [200, 150, 300, 250, 100]
}
ecommerce_df = pd.DataFrame(ecommerce_data)
分组与聚合
# 按产品类别分组并计算总销售额
category_sales = ecommerce_df.groupby('category').sum()
5.3.3 拓展案例一:员工绩效评分统计
处理一份员工绩效评分的数据,需要计算每个部门的平均绩效评分。
数据准备
# 示例员工绩效评分数据
performance_data = {
'department': ['HR', 'Tech', 'HR', 'Tech', 'HR'],
'score': [3, 4, 2, 5, 4]
}
performance_df = pd.DataFrame(performance_data)
计算平均绩效评分
# 按部门分组并计算平均绩效评分
department_performance = performance_df.groupby('department').mean()
5.3.4 拓展案例二:客户反馈分析
假设你有一份关于客户服务满意度的调查数据,需要过滤出平均评分低于3的服务类型。
数据准备
# 示例客户服务满意度数据
feedback_data = {
'service_type': ['Delivery', 'Product Quality', 'Customer Support', 'Delivery', 'Product Quality'],
'rating': [2, 5, 3, 1, 4]
}
feedback_df = pd.DataFrame(feedback_data)
过滤服务类型
# 计算服务类型的平均评分并过滤出平均评分低于3的类型
low_rating_service = feedback_df.groupby('service_type').filter(lambda x: x['rating'].mean() < 3)
通过这些案例,我们演示了如何在 Pandas 中进行分组与聚合操作,以及如何使用这些操作对数据进行分析。无论是处理电商销售数据、员工绩效评分,还是客户反馈,分组与聚合都是获取洞见的强大工具。