👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:详解SpringCloud微服务技术栈:深入ElasticSearch(3)——数据同步(酒店管理项目)
📚订阅专栏:微服务技术全家桶
希望文章对你们有所帮助
ElasticSearch本身就是分布式的,在这里将要讨论如何用3个docker容器来模拟实现ElasticSearch的集群搭建,并且提出集群会出现的脑裂问题并讨论解决方案。
但是这里集群的部署需要我们的Linux虚拟机至少拥有4G的内存空间,内存有限就不要做了。
深入ElasticSearch(4)——ES集群
- 集群结构介绍
- 搭建集群
- 集群职责及脑裂
- 分布式新增和查询流程
- 故障转移
集群结构介绍
单机的ElasticSearch做数据存储,会面临两个问题:海量数据存储问题,单点故障问题。
针对这两个问题,不得不用集群来解决了:
海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
单点故障问题:将分片数据在不同节点备份(replica),也就是说其主分片和副本分片不能在同一个节点
搭建集群
没有多台电脑,所以这里会利用3个docker容器来模拟3个ES结点。
编写docker-compose文件,里面包含了三个容器结点的部署方案,大致看懂语句的意思是什么:
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1 # 镜像
container_name: es01 # 容器名,与服务es01名称保持一致
environment:
- node.name=es01 # 结点名称,与服务es01名称保持一致
- cluster.name=es-docker-cluster # 集群名称,三个节点的名称都要一样,ES就会自动组装成集群
- discovery.seed_hosts=es02,es03 # 集群中另外两个结点,docker中可以直接在容器内互联,不一定要ip地址
- cluster.initial_master_nodes=es01,es02,es03 # 初始化主节点,这三个节点都可以参与主节点的选举
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
这个docker-compose文件直接可以从百度网盘中下载并上传到虚拟机:
链接:https://pan.baidu.com/s/10By3MR6RYqqMmjBgwDOr7w?pwd=mycu
提取码:mycu
ES运行需要修改一些Linux系统权限,修改/etc/sysctl.conf文件:
vi /etc/sysctl.conf
添加下面内容:
vm.max_map_count = 262144
再执行语句让配置生效:
sysctl -p
最后执行docker-compose up -d执行即可。
集群的状态监控这里不再推荐kibana了,配置比较复杂,推荐使用cerebro来监控ES集群的状态,压缩包从网盘下载:
链接:https://pan.baidu.com/s/1kywnAFGyVbbpRN4weRF8Ag?pwd=laz2
提取码:laz2
下载完就在本地解压,然后进入其中的bin目录,双击其中的cerebro.bat即可启动服务。访问9000端口就可以访问了。
在这里就可以创建索引库,并且可以直接指定需要分片的数量为3,每个分片锁被备份的数量为1。
集群职责及脑裂
ElasticSearch中节点的角色有4中:
| 节点类型 | 配置参数 | 默认值 | 节点职责 |
|---|---|---|---|
| master eligible | node.master | true | 作为备选主节点,一旦当选,则:管理和记录集群状态;处理分片在哪个节点;处理创建和删除索引库的请求 |
| data | node.data | true | 数据节点:存储数据、搜索、聚合、CRUD |
| ingest | node.ingest | true | 数据存储之前的预处理 |
| coordinating | 上面3个参数都为false则为coordinating节点 | 无 | 路由请求到其它节点;合并其它节点处理的结果,返回给用户 |
这种方式把职责分开显然是很好的,但是还是可能会出现问题,即脑裂问题。
默认情况下,每个节点都是master eligible节点,因此一旦master节点宕机,其它候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能会出现脑裂问题。如下:
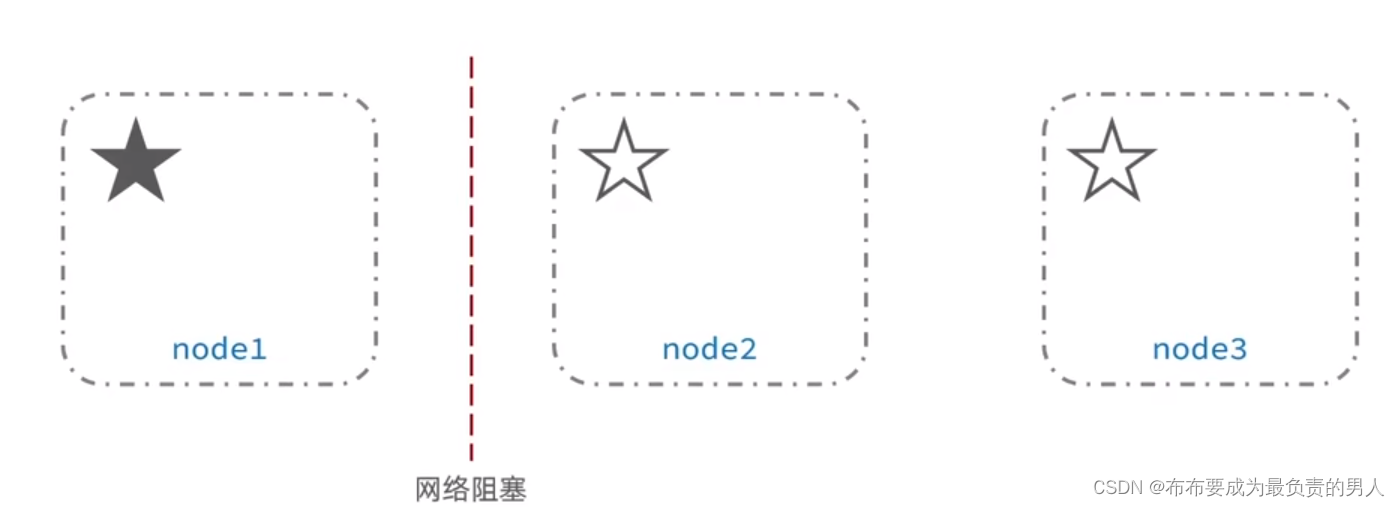
node1位主节点,原先就是没有故障的,但是和备选主节点node2、node3由于网络阻塞问题没办法互联了,这时候node2或node3可能就会误认为node1宕机了,自动选举出主节点。从而造成了集群中有2个主节点,它们共同执行了系统的业务,当网络恢复正常的时候,访问节点的数据的时候就会发生数据不一致的问题。
为了避免脑裂,需要要求选票超过(eligible节点数量+1)/2才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,但在ES7.0以后,已经成为默认配置,因此一般不会出现脑裂问题。
分布式新增和查询流程
当新增文档时,应该保存到不同的分片,保证数据均衡,coordinating node可以确定数据该存储到哪个分片中。
例如,配置好的三台ES,从9200端口中保存3条文档,可以发现9201和9202端口都可以查询到这三条文档,同时三条消息分别分片到了三台不同的机器上。这就是协调结点起到的作用。
实际上,这个数据分片是利用一个算法来实现的:
s
h
a
r
d
=
h
a
s
h
(
_
r
o
u
t
i
n
g
)
%
n
u
m
b
e
r
_
o
f
_
s
h
a
r
d
s
shard = hash(\_routing) \% number\_of\_shards
shard=hash(_routing)%number_of_shards
_routing默认是文档的id
算法与分片数量有关,因此索引库一旦创建,分片数量不能修改
这样的话,3台机器运算后的结果只会是0、1、2中的一个,从而实现数据的分布式新增。
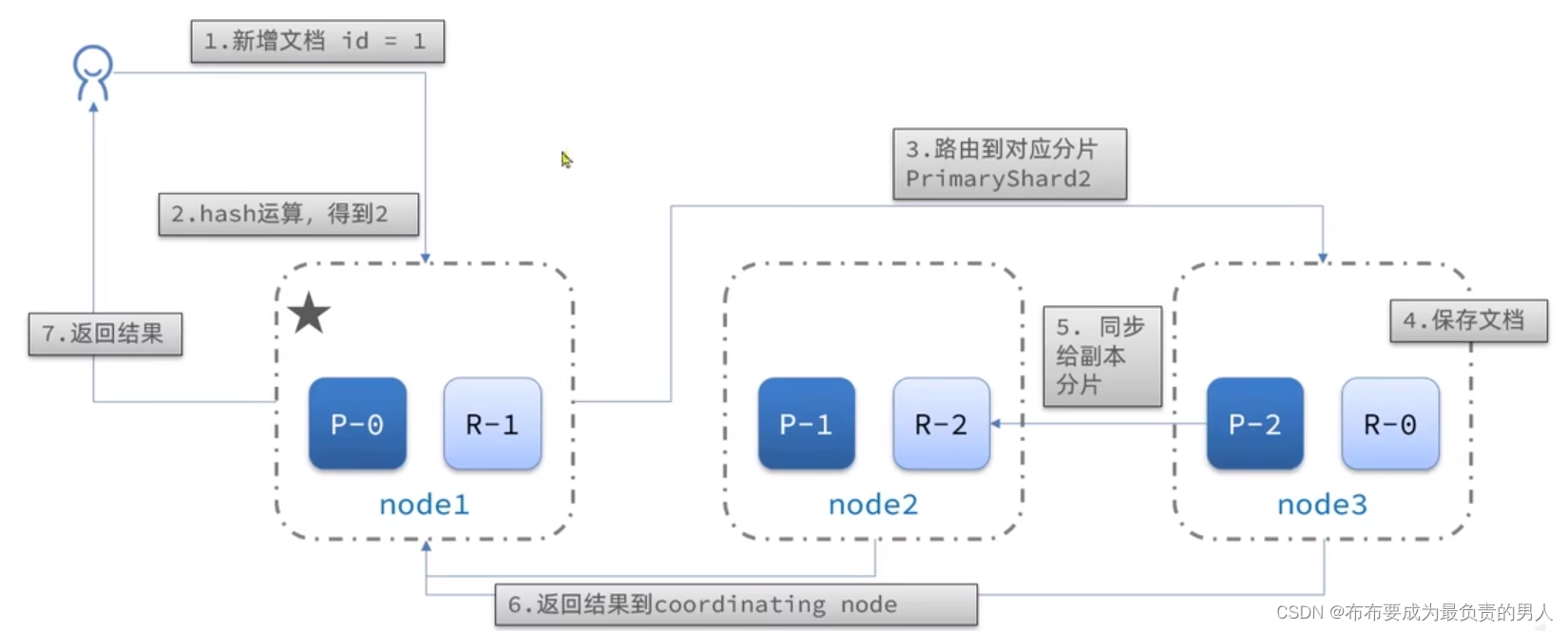
查询分成2个阶段:
scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
总结:
1、分布式新增如何确定分片:coordinating node根据id做hash运算,得到结果对shard数量取余,余数就是对应的分片
2、分布式查询:分散阶段、聚集阶段
故障转移
故障转移是ES节点一个非常重要的功能,集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据的安全,即为故障转移。
也就是说,当数据节点发生故障时,主节点会监控到这种状态,就会将节点中的所有分片和副本都转移到其它的节点,确保数据的安全。
而主节点本身宕机的话,EligibleMaster就会选举出新的主节点出来