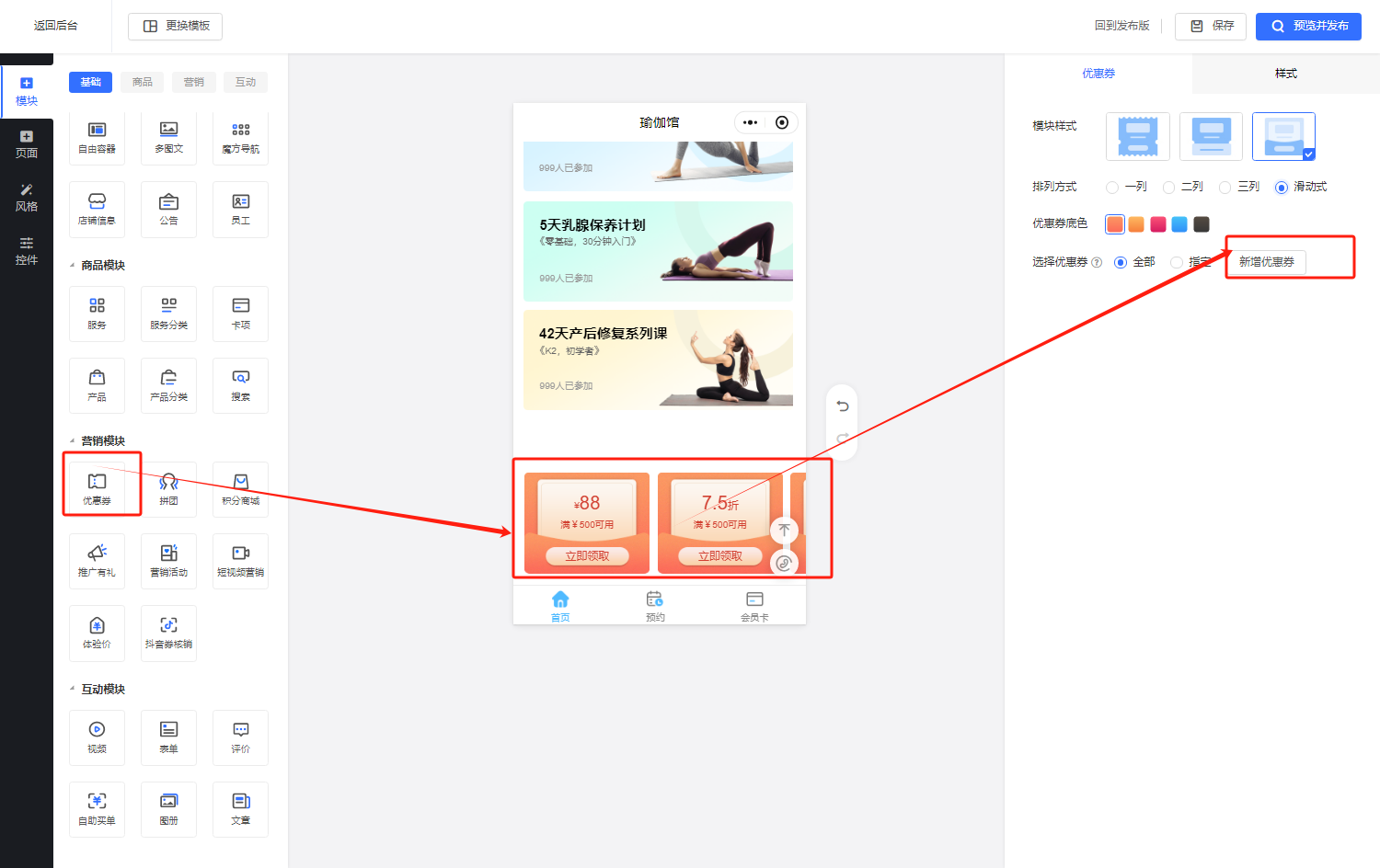
文章目录
- transformer的输入部分input coding
- BPE
- BPE所解决的问题——OOV
- PE(Position Encoding)位置编码
transformer的输入部分input coding
transformer的输入部分input coding=BPE+PE
BPE

BPE是指一种词分类算法。
起初,会将每个单词都拆分成一个个字母扔进词表中。
然后统计byte gram,选出出现次数最多的byte gram,将其塞入到词表中,若组成的byte gram使得原本单独的部分无其他非组成该byte gram的情况,则该部分需要从原先的词表进行删除。
比如e和s形成es,es在newest和widest均有出现,且出现的次数最多,所以可将e和s整合成es塞入到词表中,且s只在es中出现,所以在整合的过程中要在原先词表中删去s,让s作为es整体的部分进行出现。
BPE所解决的问题——OOV
OOV是out of vocabulary的简称.
OOV是指代一个问题,即目前出现的单词超出已有的知识范围。
而BPE能够处理OOV问题。
比如说BPE会通过学习将smartest拆分成smart和est,当他遇到并不认识的lowest时,会将其拆分成low和est,而可通过之前学习到的smart和est来进行泛化/推理,如果说词表中是含有low这个词项的话,那么是可以推理得到大概lowest的意思

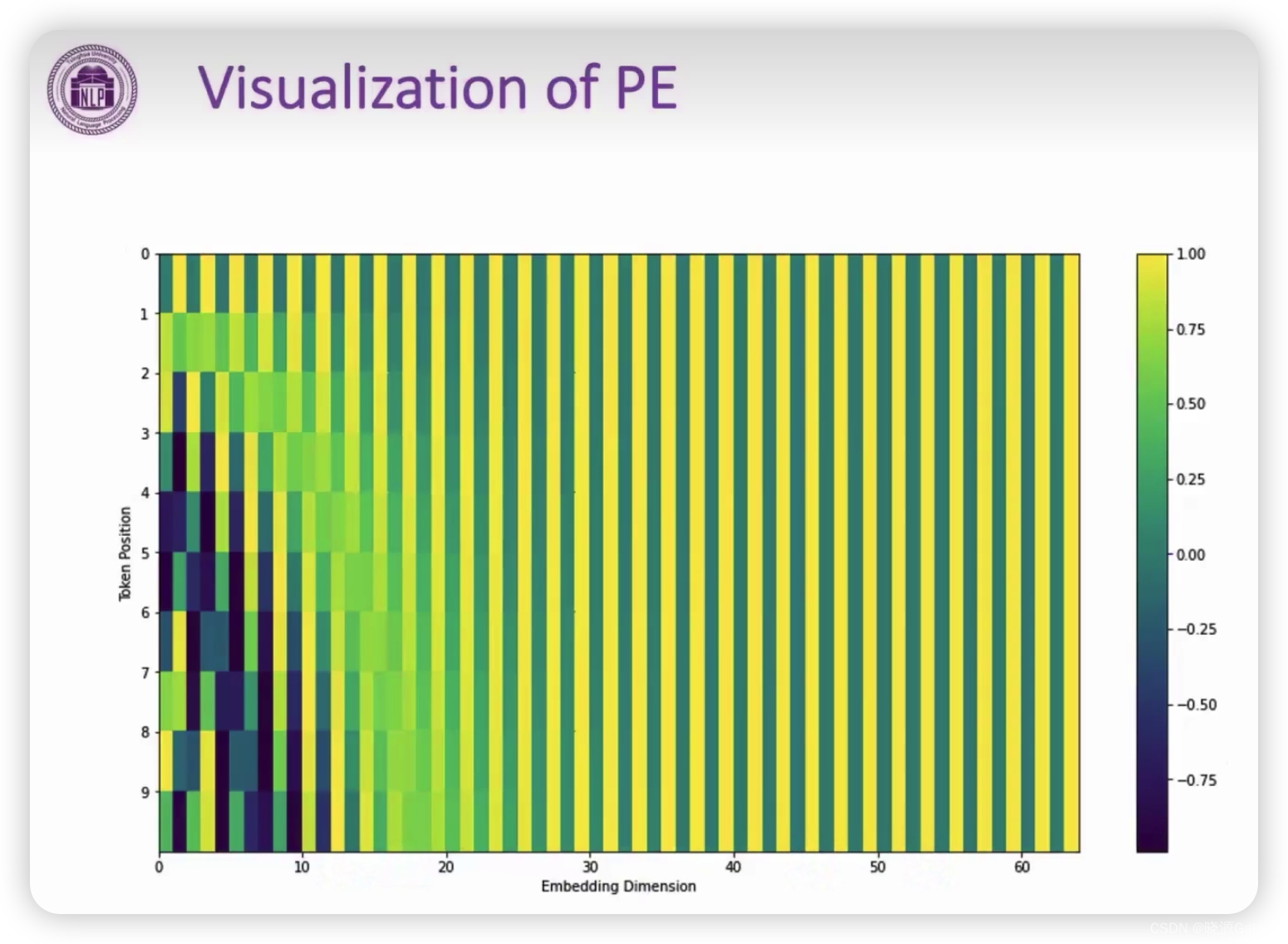
PE(Position Encoding)位置编码
作用:用于弥补transformer无法处理各输入部分的位置信息。(位置信息是很重要的,词的意思可通过上下文进一步明确,上文放在下文,可能就有不同的意思存在)
如“我吃鱼”和“鱼吃我”是两个不同的概念。


pos是指位置,比如说“我爱你”中的“爱”的位置为第二。
i是词在转为词向量后所得到的索引。比如embedding后的维度为512维,那么i对应其中一个维度。

PE算法会对应一个三角函数。
当索引为偶数时,
P
E
(
p
o
s
+
k
,
2
i
)
=
s
i
n
(
(
p
o
s
+
k
)
/
1000
0
2
i
d
m
o
d
e
l
)
=
s
i
n
(
(
p
o
s
)
/
1000
0
2
i
d
m
o
d
e
l
×
c
o
s
(
(
k
)
/
1000
0
2
i
d
m
o
d
e
l
+
s
i
n
(
(
k
)
/
1000
0
2
i
d
m
o
d
e
l
×
c
o
s
(
(
p
o
s
)
/
1000
0
2
i
d
m
o
d
e
l
=
P
E
(
p
o
s
,
2
i
)
P
E
(
k
,
2
i
+
1
)
+
P
E
(
k
,
2
i
)
P
E
(
p
o
s
,
2
i
+
1
)
PE(pos+k,2i) = sin((pos+k)/10000^{\frac{2i}{d_{model}}})=sin((pos)/10000^{\frac{2i}{d_{model}}}\times cos((k)/10000^{\frac{2i}{d_{model}}}+sin((k)/10000^{\frac{2i}{d_{model}}}\times cos((pos)/10000^{\frac{2i}{d_{model}}}=PE(pos,2i)PE(k,2i+1)+PE(k,2i)PE(pos,2i+1)
PE(pos+k,2i)=sin((pos+k)/10000dmodel2i)=sin((pos)/10000dmodel2i×cos((k)/10000dmodel2i+sin((k)/10000dmodel2i×cos((pos)/10000dmodel2i=PE(pos,2i)PE(k,2i+1)+PE(k,2i)PE(pos,2i+1)
同理,当索引为奇数时,也会得到对应的处理。
也就是说pos为6的位置编码为可以由1和5,2和4,3和3三对位置编码得到。
进而,位置编码可以认为是一种向量。然后向量是具有空间的,通过和积化差可以得到这个向量是由于某些向量线性组合而成,而线性组合也有对应的空间表示,从而通过线性组合区分位置关系。