基于OpenCompass大模型评测
关于评测的三个问题Why/What/How
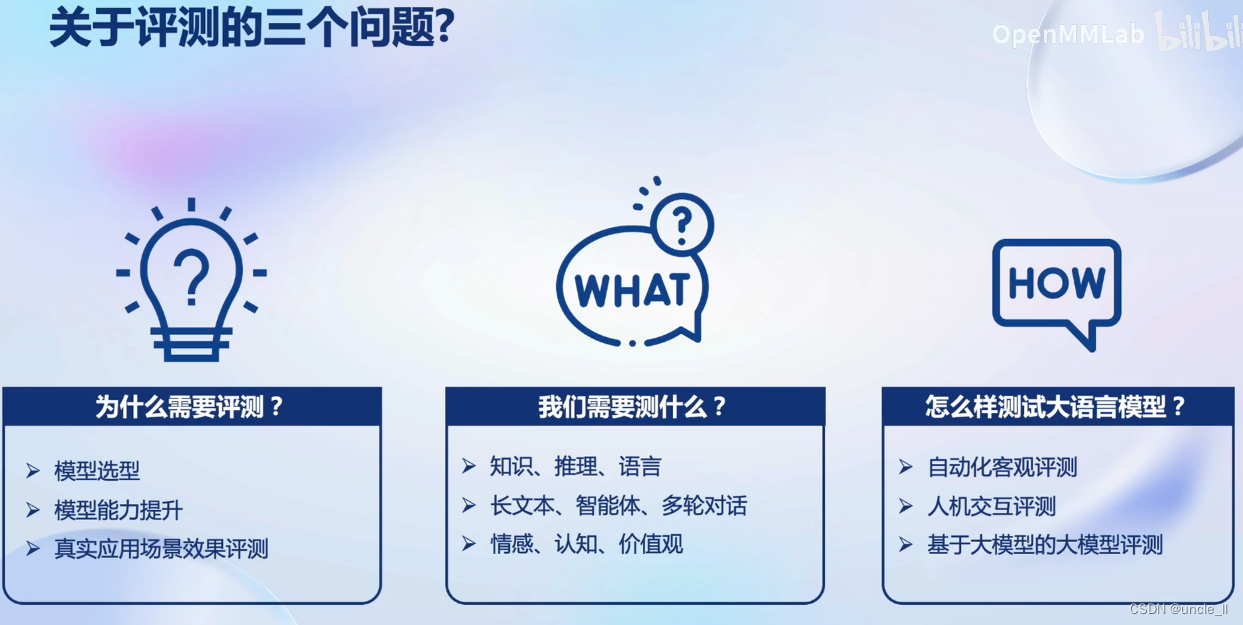
Why


What
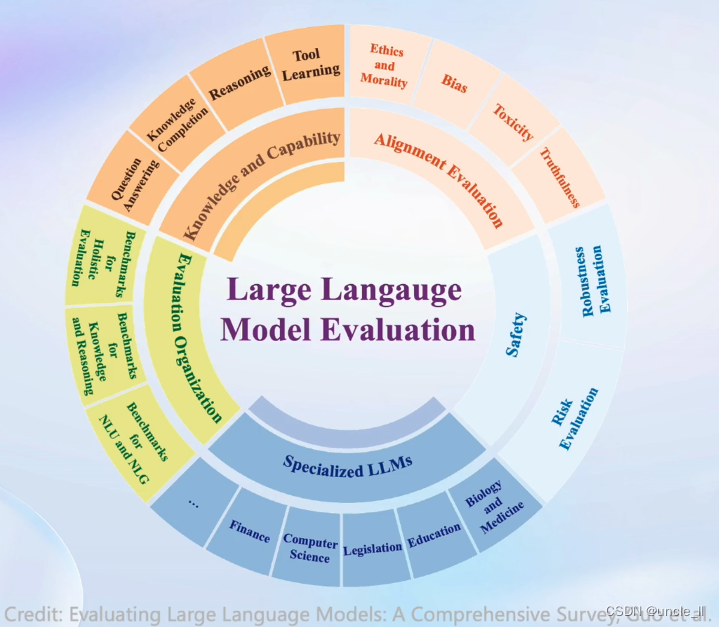
有许多任务评测,包括垂直领域
How



包含客观评测和主观评测,其中主观评测分人工和模型来评估。
提示词工程

主流评测框架

OpenCompass 能力框架


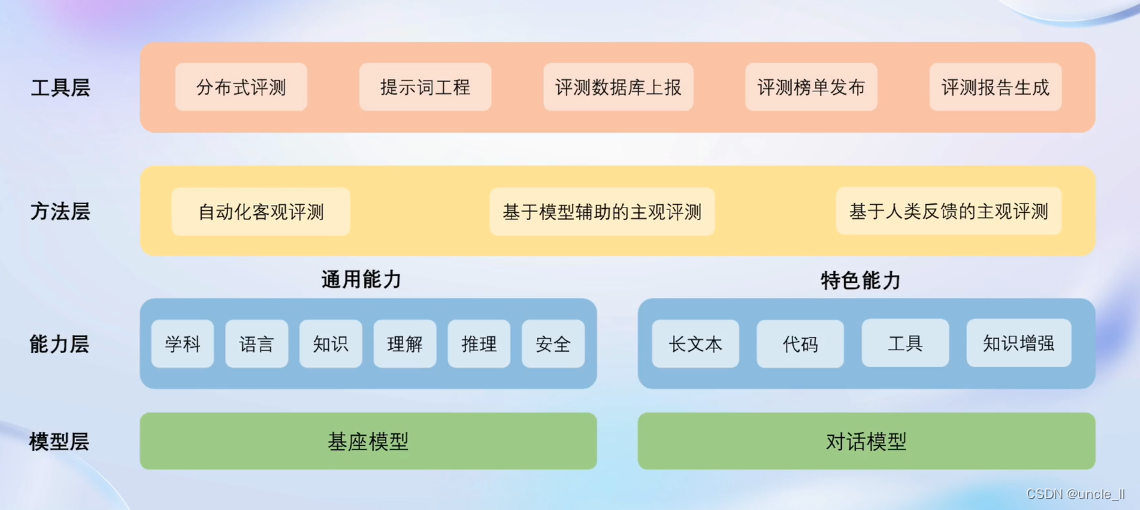
- 模型层
- 能力层
- 方法层
- 工具层

支持丰富的模型
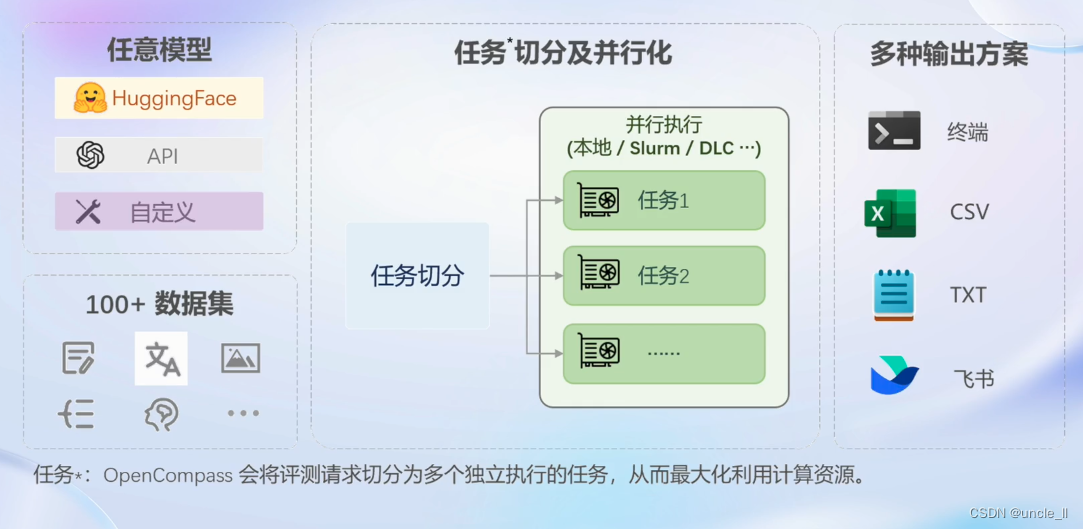
评测流水线设计,能切分多个独立执行的任务,最大化利用计算资源。
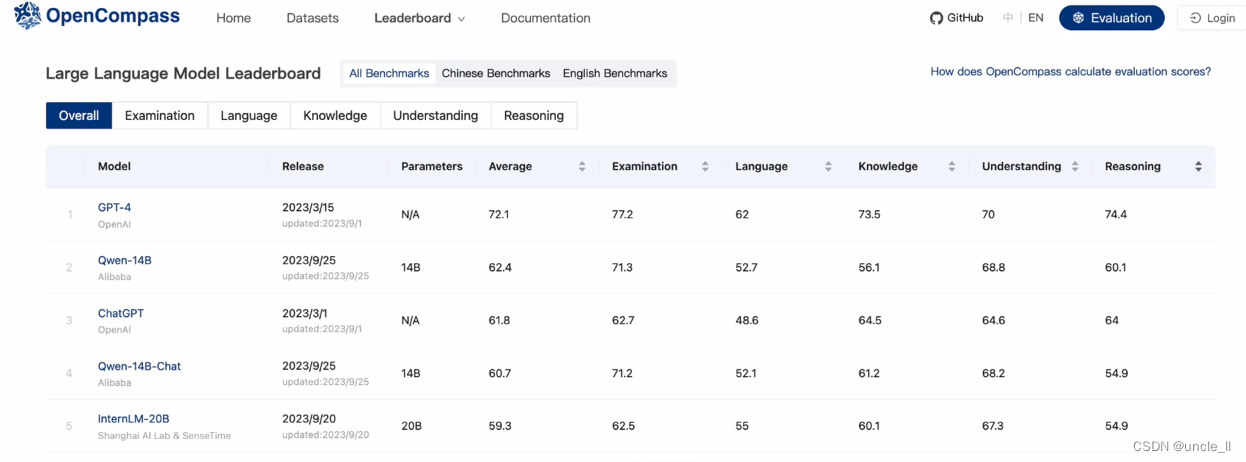
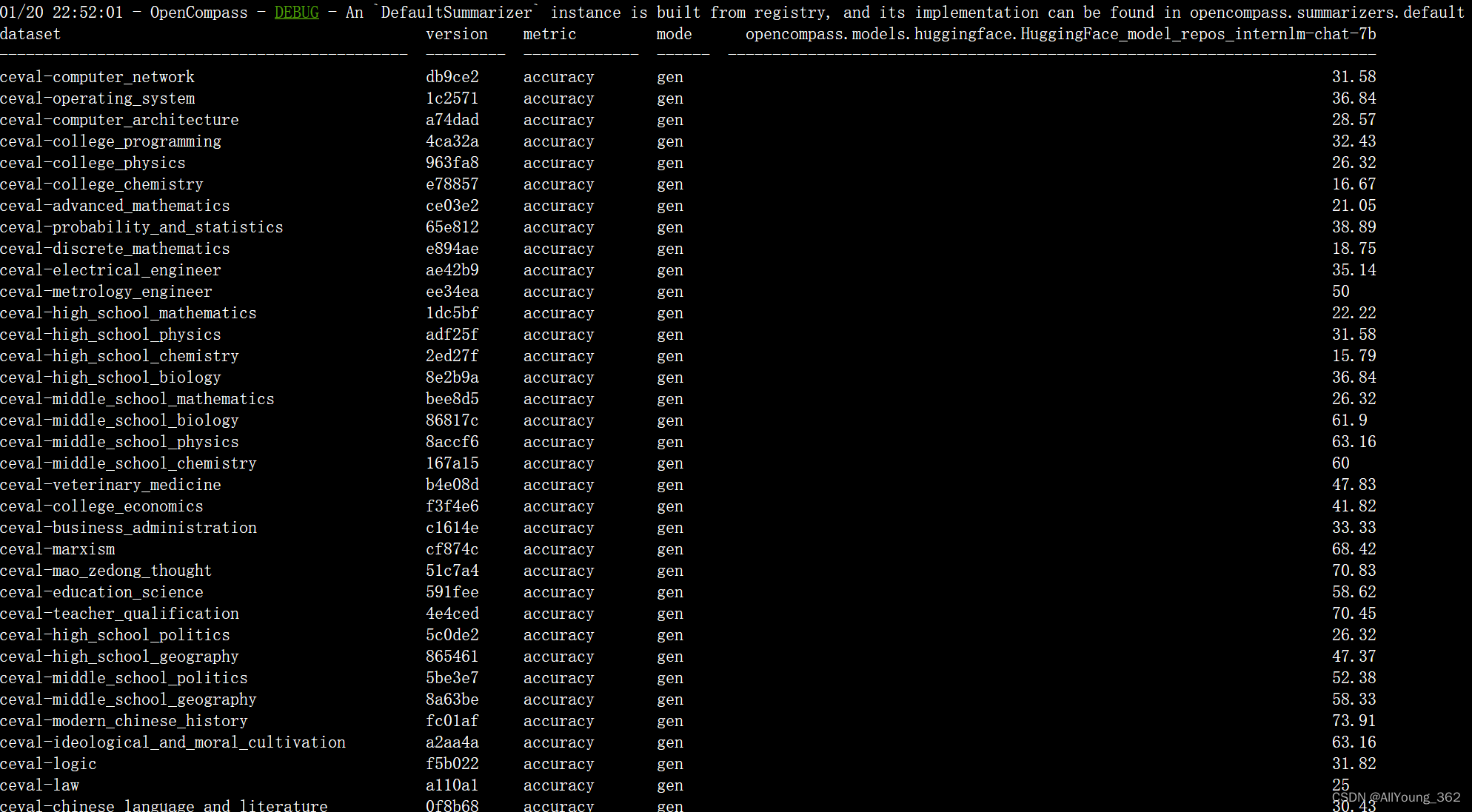
大模型能力对比结果输出
前言探索
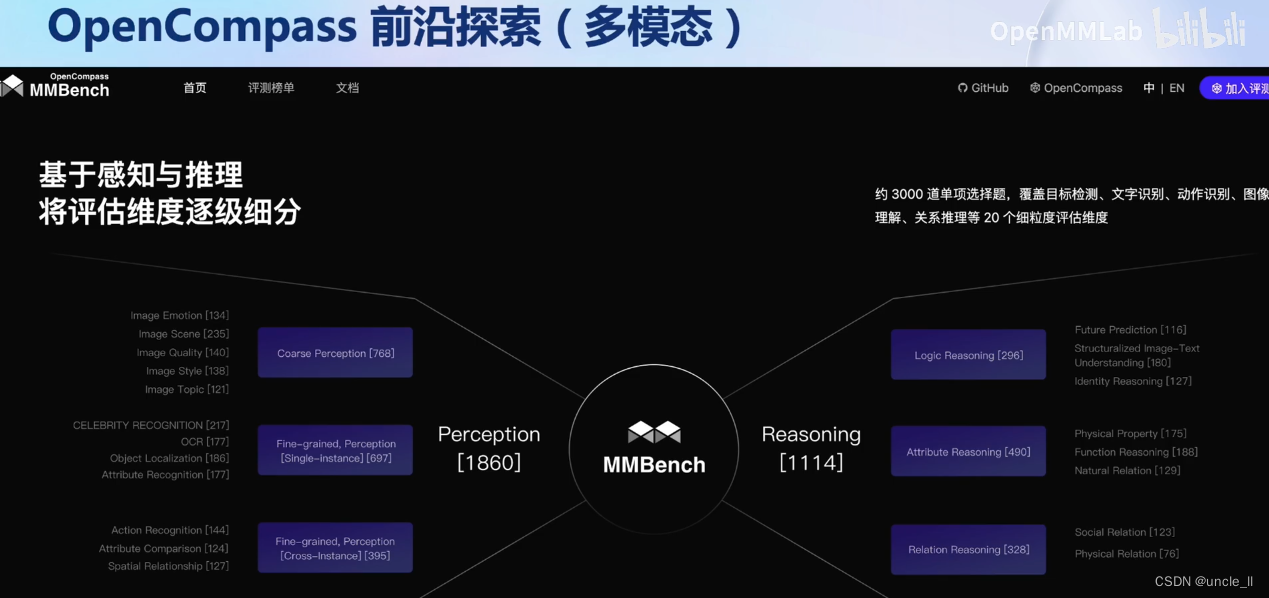
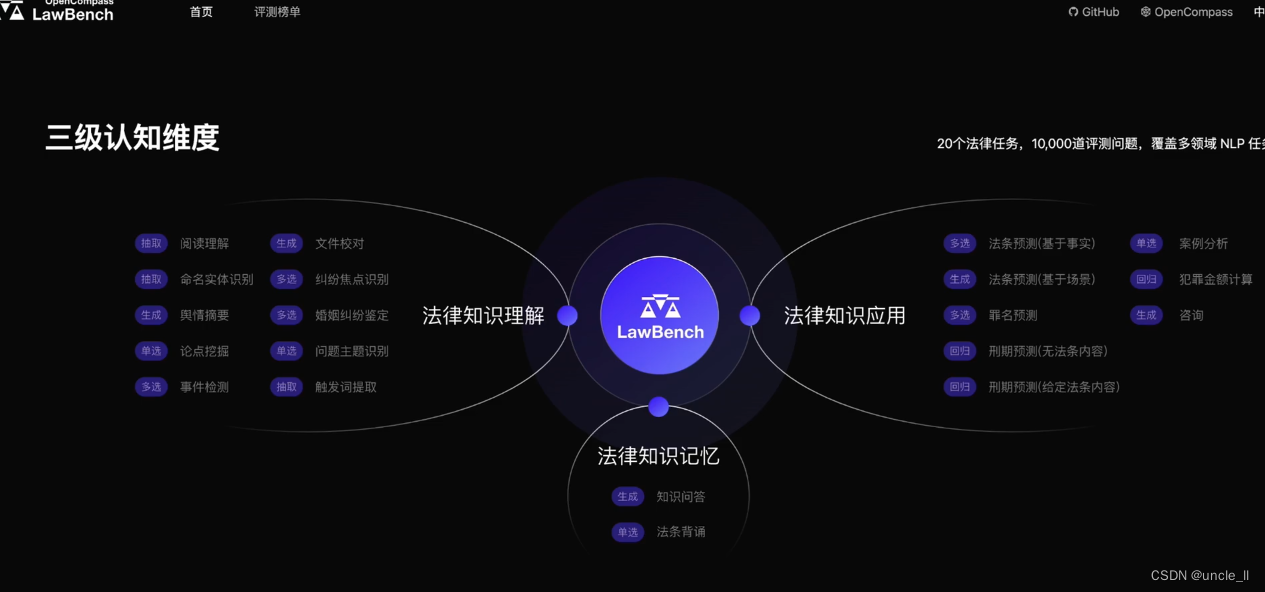
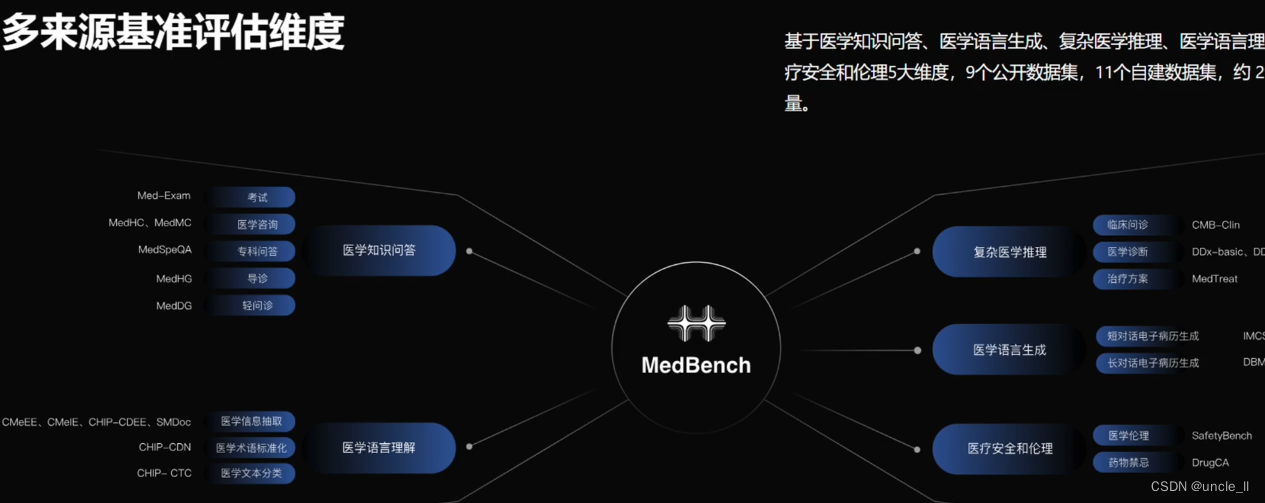
探索性方向涵盖:
- 多模态
- 法律
- 医生
挑战
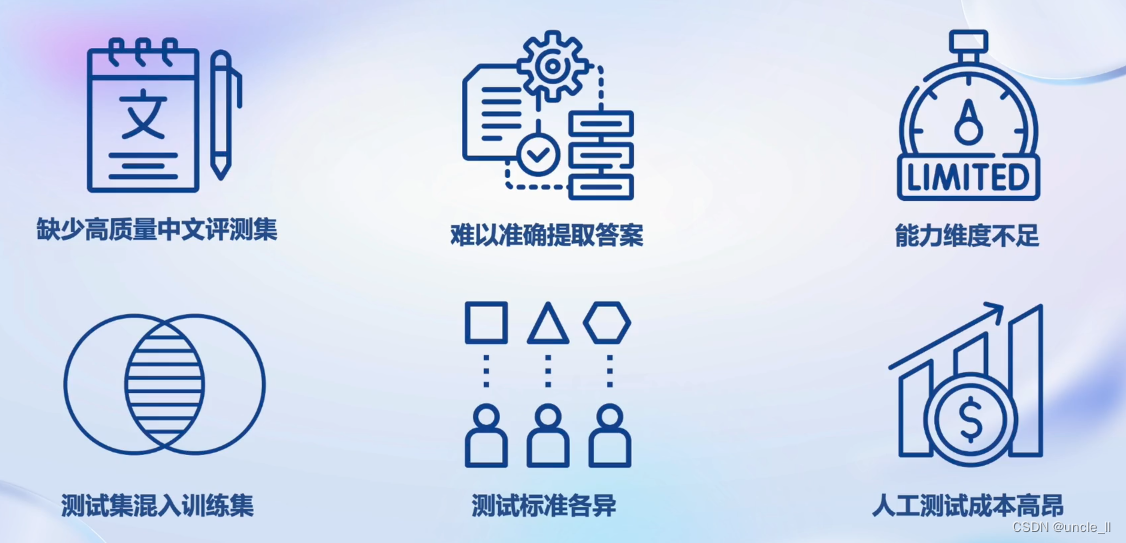
实践
创建开发环境和准备数据集

查看支持的数据集:
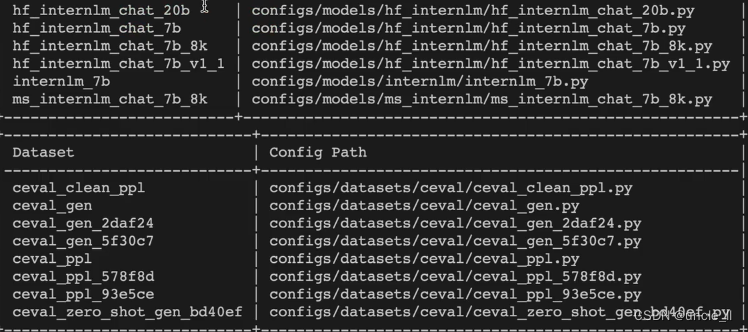
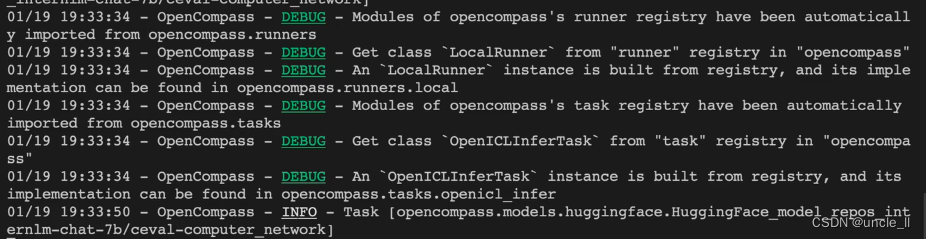
启动评测
客观评测
主要是run.py代码文件

- datasets:指定数据集
- hf-path:模型文件
- tokenizer-path:tokenizer路径
- max-seq-len:模型读入的最大长度
- max-out-len:模型输出的最大长度,客观题设置一般较小
- –debug:debug模式,打印出所有的过程

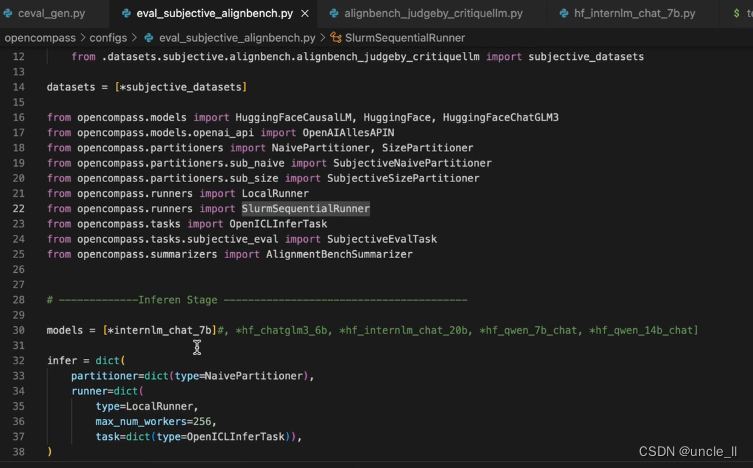
主观评测
主要是eval_sbujective_alignbench.py文件修改,需要注意model,max_out_len等处的修改。