文章目录
- 一. Hadoop日志
- 1.1 namenode日志
- 1.2 datanode日志
- 1.3 secondarynamenode日志
- 1.4 yarn日志
- 1.4.1 resourcemanger日志
- 1.4.2 nodemanager日志
- 1.5 historyServer日志
- 二. Hive日志
- 三. Spark日志
- 四. Flink日志
一. Hadoop日志
cd $HADOOP_HOME/logs
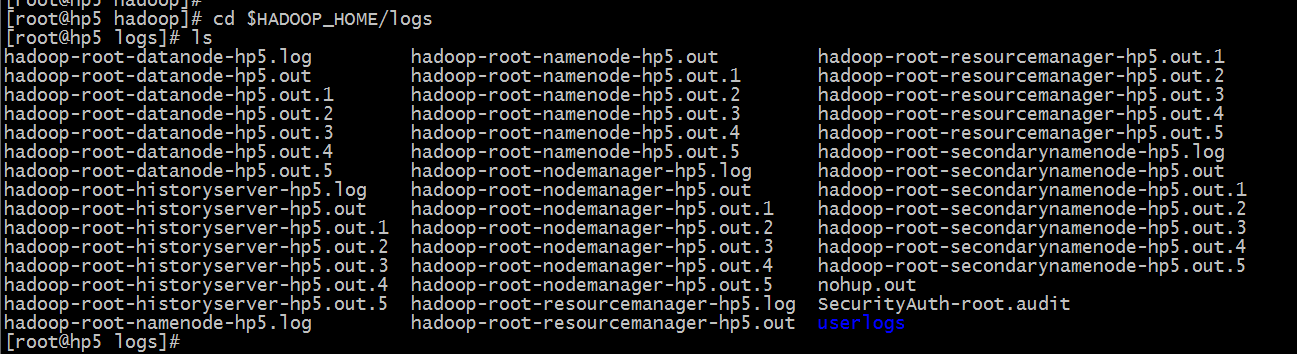
日志分类:
-
namenode日志
-
datanode日志
-
secondarynamenode日志
-
yarn日志
4.1 resourcemanger日志
4.2 nodemanager日志 -
historyServer日志
1.1 namenode日志
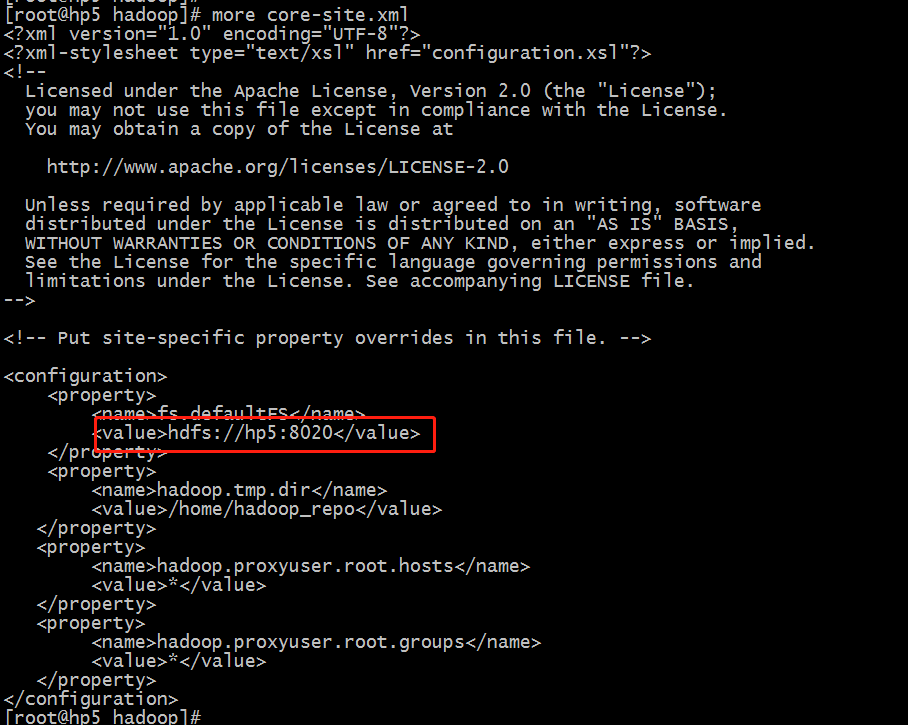
名称节点的日志,如果名称节点有问题,需要进行排查。一个hadoop大数据集群只有一个namenode,具体的信息可以查看配置文件
$HADOOP_HOME/etc/hadoop/core-site.xml
1.2 datanode日志
一个hadoop大数据平台一般有多个datanode,每个datanode节点都有自己的日志。
$HADOOP_HOME/etc/hadoop/works
1.3 secondarynamenode日志
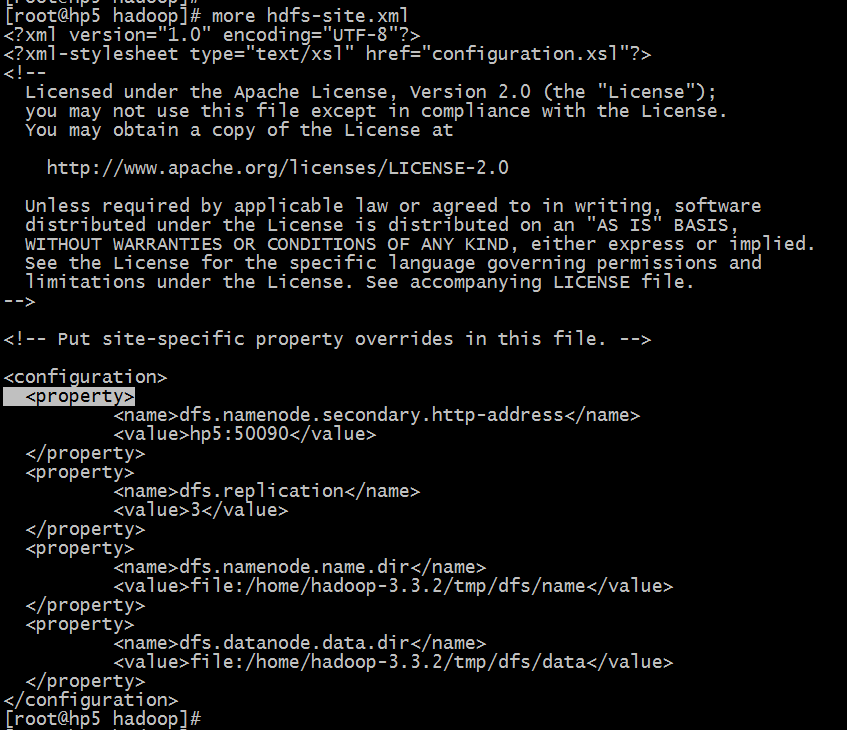
我们知道对HDFS进行读写,都需要通过namenode找到对应的datanode,如果集群节点众多且数据量非常大,那么namenode的压力是非常大的,于是诞生了secondarynamenode来分担namenode的压力。
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
1.4 yarn日志
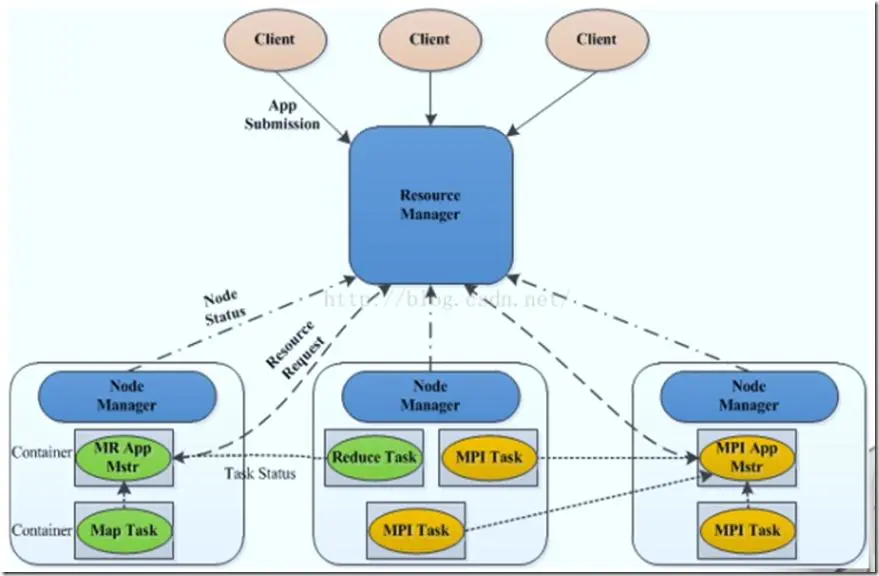
yarn图解:
1.4.1 resourcemanger日志
resourcemanger负责全局的资源管理和任务调度,把整个集群当作计算资源池,只关注分配,不管应用,且不负责容错。
$HADOOP_HOME/etc/hadoop/yarn-site.xml
1.4.2 nodemanager日志
Node节点下的Container管理
-
启动时向ResourceManager注册并定时发送心跳消息,等待ResourceManger的指令
-
监控Container的运行,维护Container的生命周期,监控Container的资源使用情况
-
启动或停止container,管理任务运行时的依赖包(根据APPlicationMaster的需要,启动Container之前将需要的程序以及依赖包,配置文件等COPY到本地)
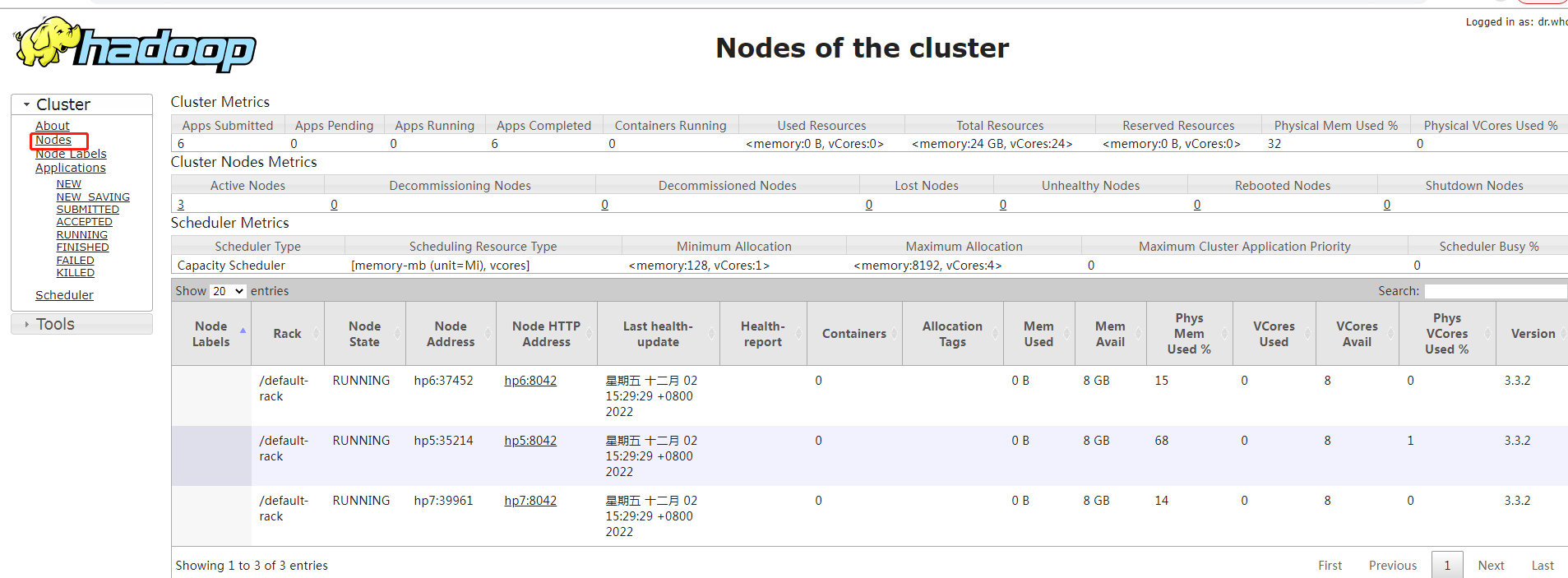
注意:
很多时候,我们需要查询nodemananger的日志,从这个地方可以看到我们的任务被分配到那个node了。
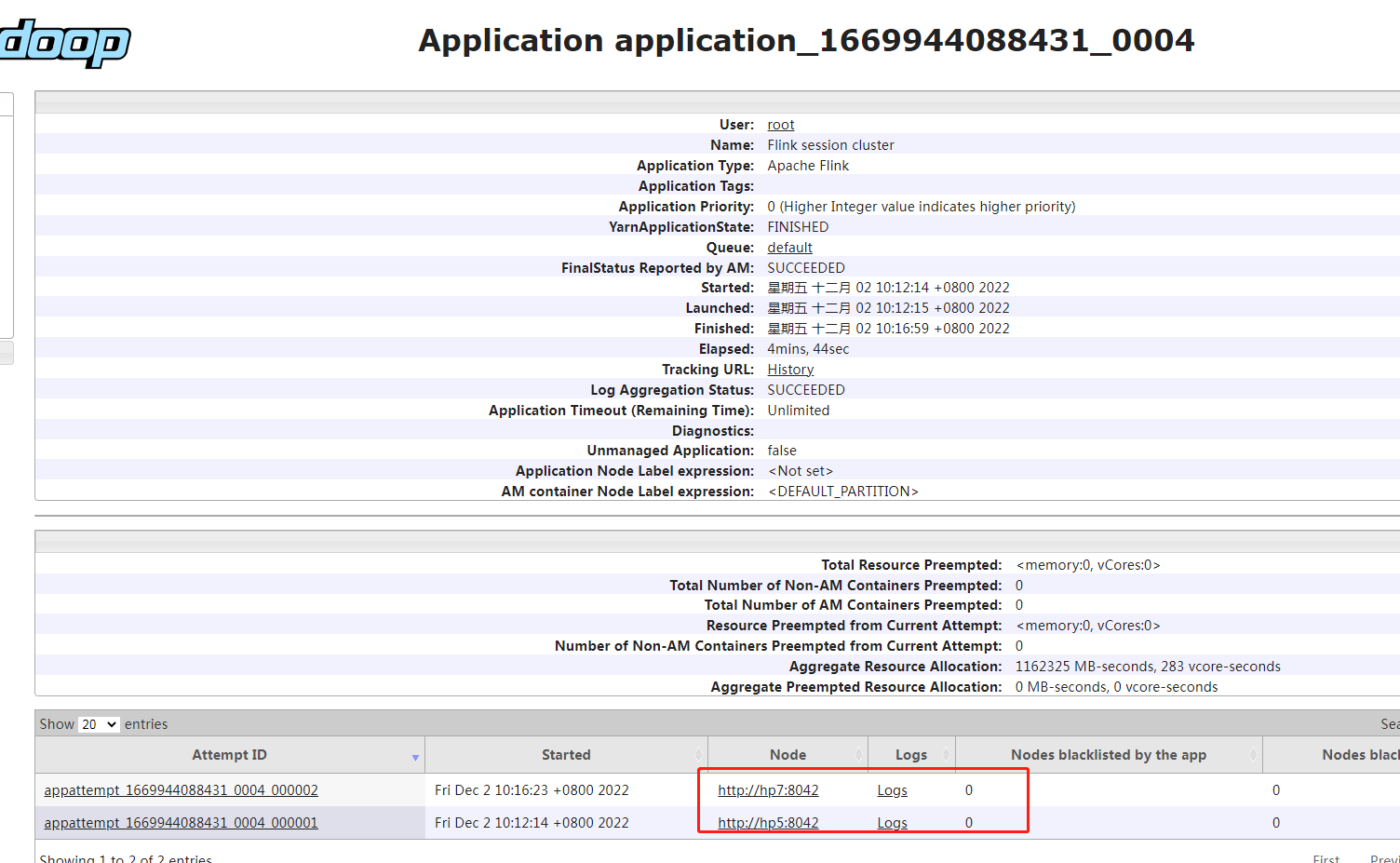
1.5 historyServer日志
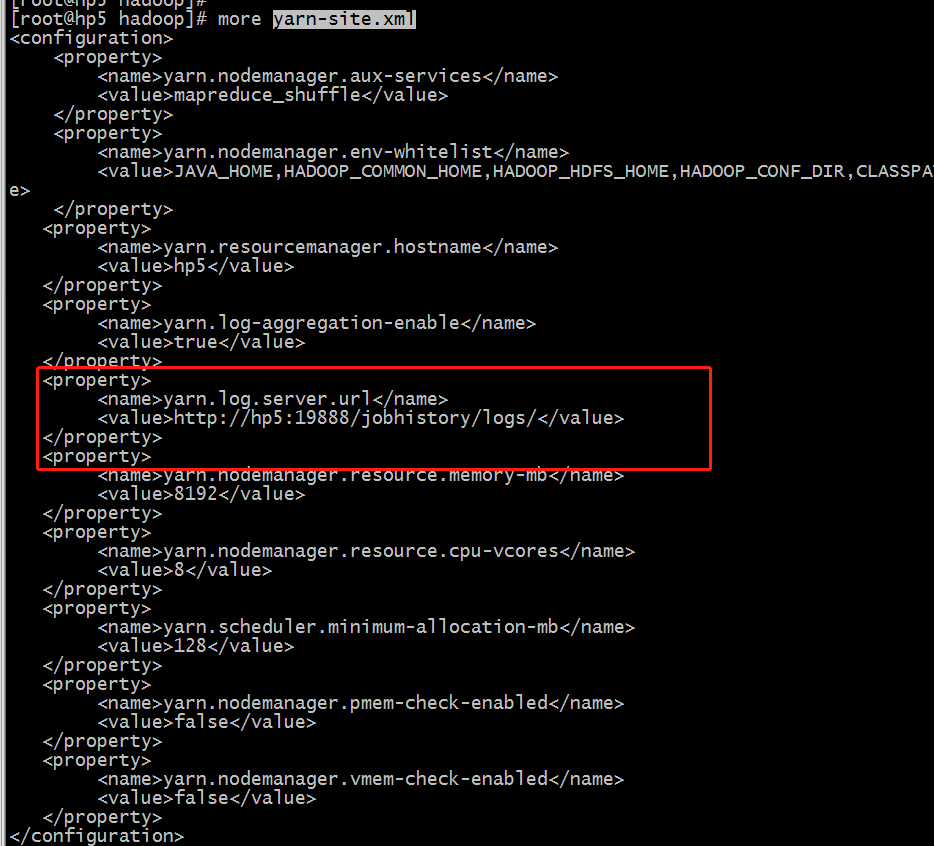
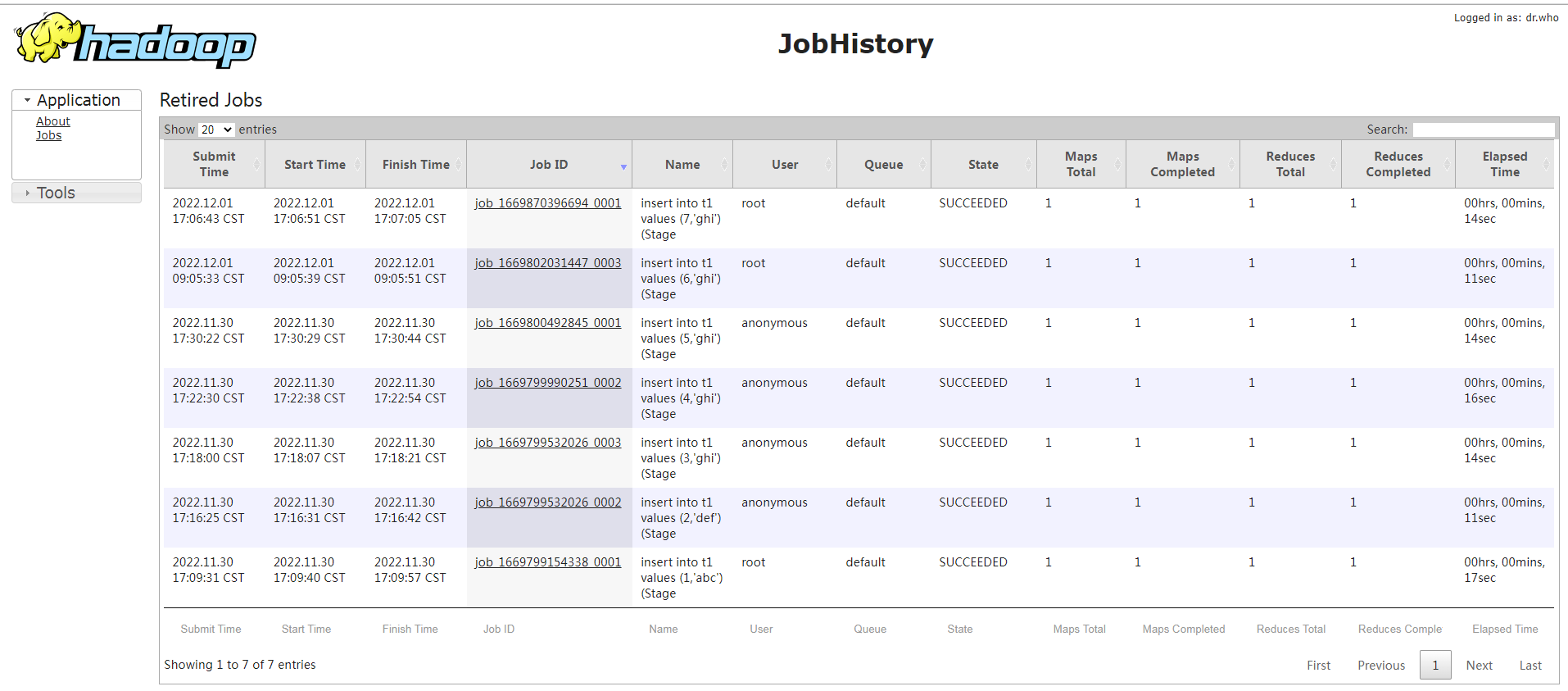
当我们重启yarn后,resourcemanger就没办法查看重启前的job运行的历史记录了,此时我们需要从historyServer上查看。
$HADOOP_HOME/etc/hadoop/yarn-site.xml
二. Hive日志
Hive的日志比较特殊,$HIVE_HOME 目录是没有logs目录的,其它的组件都是有logs目录的。
Hive的日志在节点(那个节点登陆hive)的/tmp/$username 目录下
例如:
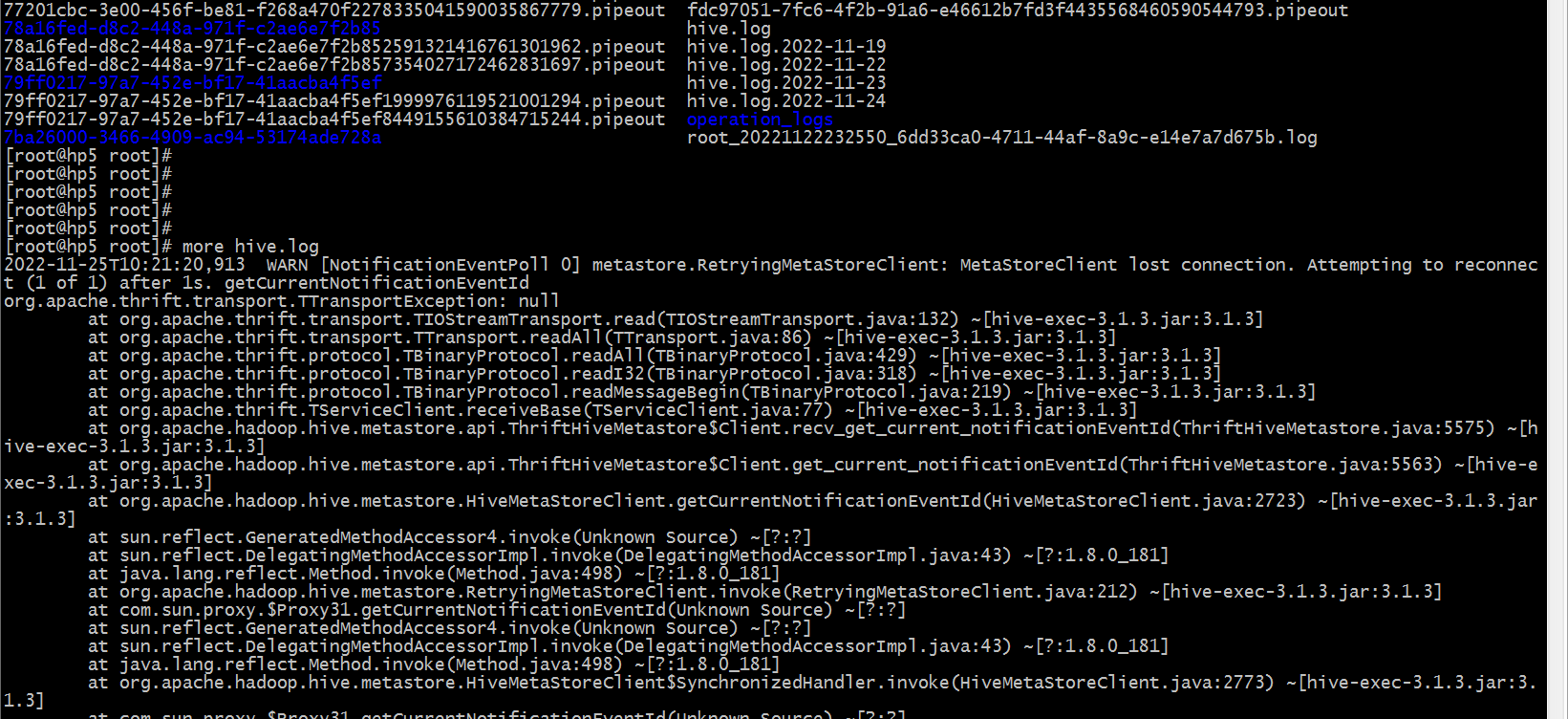
cd /tmp/root
ls
more hive.log
三. Spark日志
Spark的日志就区分 Master和worker日志
cd $SPARK_HOME/logs

四. Flink日志
Flink的日志 主要是standalone(独立部署)日志和 taskexecutor日志。
如果使用Flink SQL客户端还会有Flink SQL相关的日志。
cd $FLINK_HOME/log

![Bandit算法学习[网站优化]02——epsilon-Greedy 算法](https://img-blog.csdnimg.cn/07689f6aa1504895a38e270927c306db.png)


![[Amazon]人工智能入门学习笔记---AI-机器学习-深度学习](https://img-blog.csdnimg.cn/1bffc2c134f64bd29fc868c40356cf24.png)