读到一段巧妙的正则表达式,勾起我对正则表达式欠缺知识点的探寻: P y t h o n Python Python正则表达式中的“回引用(回溯)”——分组别名引用与序号引用的差异及正则表达式中的“P”关键字详情。
(笔记模板由python脚本于2024年01月14日 07:49:35创建,本篇笔记适合熟悉基础编程,了解正则表达式的coder翻阅)
-
Python 官网:https://www.python.org/
-
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单……
地址:https://lqpybook.readthedocs.io/
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚
- My CSDN主页、My HOT博、My Python 学习个人备忘录
- 好文力荐、 老齐教室

本文质量分:
本文地址: https://blog.csdn.net/m0_57158496/article/details/135579291
CSDN质量分查询入口:http://www.csdn.net/qc
- ◆ 正则表达式中的“回引用(回溯)”
- 1、奇妙的代码
- 2、 A I AI AI解疑
- 2.1 解析“`神奇`”代码
- 2.2 询问“`回引用`”
- 3、“P”关键字
- 4、别名引用与序号引用
- 5、参考文章
- 6、本笔记样例完整源码(Python)
◆ 正则表达式中的“回引用(回溯)”
1、奇妙的代码
奇妙
p
y
t
h
o
n
python
python代码
text = '''I have two feet, it has one foot.
She's singing a song.
canada bananas'''
result = re.findall(r'(\b\w*(?P<f>\w+)(?P=f)\w*\b)', text)
print(result)
上面这段代码,是在闲逛 c s d n csdn csdn时捡回来的,当时是因为新奇它的正则表达写法,因为没见过,也读不明白,就 c v cv cv回来了。更“惊艳”其输出: [ ( ′ f e e t ′ , ′ e ′ ) , ( ′ f o o t ′ , ′ o ′ ) , ( ′ s i n g i n g ′ , ′ i n g ′ ) , ( ′ b a n a n a s ′ , ′ n a ′ ) ] [('feet', 'e'), ('foot', 'o'), ('singing', 'ing'), ('bananas', 'na')] [(′feet′,′e′),(′foot′,′o′),(′singing′,′ing′),(′bananas′,′na′)]
上面那个代码运行截屏图片

通配表达式r'(\b\w*(?P<f>\w+)(?P=f)\w*\b)',为啥可以有这样子的输出,我“百思不得其解”,也没有搜索到恰当的答案,就一直搁置了下来。
今天我才幡然醒悟,“为何不让我的ai助理智谱清言给解析解析”。世上流行的AI,大多对书写代码非常在行,尤其对Python更是精通。
2、 A I AI AI解疑
2.1 解析“神奇”代码
-
向我的a i ai ai助理智谱清言提问截屏图片

-
智 谱 清 言 智谱清言 智谱清言
回复文本原文抄录:
在您提供的文本中,使用正则表达式\w*(?P<f>\w+)(?P=f)\w*尝试匹配的是一个特定的模式,该模式试图找到一个单词,然后它自己重复一次,并被一个或多个字母包围。但这个表达式可能会产生一些问题,因为它试图匹配的重复单词部分可能会匹配到字符串中重复出现的单词,而不是特定模式下的重复。
例如,在 “I have two feet, it has one foot.” 这句话中,“two” 和 “one” 都是完整的单词,所以它们会匹配这个表达式。但在 “foot” 中,“oo” 部分并不符合该模式,因为它不是由一个单词重复而来。
正则表达式r'\w+'将会匹配一个或多个字母或数字字符组成的单词。所以,如果要用这个表达式来找到所有单词,可以这样写:
import re
text = '''I have two feet, it has one foot.
She's singing a song.
Canada bananas'''
result = re.findall(r'\w+', text)
print(f"\n文本:\n{text}\n\nre通配表达式:r'\w+'\nre.findall函数匹配结果:\n{result}\n\n{'':~^40}")
这段代码会找到并打印出文本中所有的单词。
在您的代码中,注释掉的
f
i
n
d
a
l
l
findall
findall 函数调用使用了不同的正则表达式,但由于该表达式的问题,它可能不会按预期工作。在正则表达式中,(?P=f) 是一种回引用,它指的是在同一个正则表达式中定义的命名捕获组 。但在这个特定的表达式中,它的使用可能是不正确的,因为它试图匹配的是同一个捕获组的内容,这在没有其他组提供内容的情况下是无法工作的。
如果您的目标是找到所有重复的单词,您可能需要调整正则表达式以适应您的具体需求,或者使用其他方法来处理文本。如果您有更具体的模式或者需求,请提供详细信息,以便我能够给出更准确的帮助。
从回复文本可以看出,“智谱清言”对中文语义的“理解”也是比较到位的,虽然有些绕,但已经不妨碍我理解了。😜从
a
i
ai
ai回复中,我终于明白了,“神奇”代码用了一种叫
回
引
用
回引用
回引用的正则表达式“魔法糖”,产生了我认为的“近乎奇幻”的输出。
2.2 询问“回引用”
再问问“
智
谱
清
言
智谱清言
智谱清言”回引用是个啥吧。
向我的a i ai ai助理智谱清言提问截屏图片

-
智
谱
清
言
智谱清言
智谱清言
回复文本原文抄录:
回引用( B a c k r e f e r e n c e Backreference Backreference):
在正则表达式中是一个特殊的语法,用于引用前面在表达式中定义的命名捕获组(named capture group)或非命名捕获组(unnamed capture group)的内容。回引用的目的是为了匹配之前匹配到的文本。
在正则表达式中,使用\num或\name形式来表示回引用,其中num是捕获组的编号,而name是捕获组的名称。

这个表达式定义了一个命名捕获组 ,它匹配一个或多个字母数字字符。紧接着\1就是对第一个捕获组(即<word>)的回引用,它将会匹配与<word>中相同的内容。这意味着整个表达式将会匹配一个单词后跟一个与这个单词相同的单词,例如 “apple apple”。
这个“概念解释”的回复完全是$ai$吐人言,我毫不费力地阅读和理解了。😜
3、“P”关键字
正则通配表达式中的“P”,是被我遗漏的知识点。它一直都在,只是被我无情遗漏在了角落。
“P”的知识点
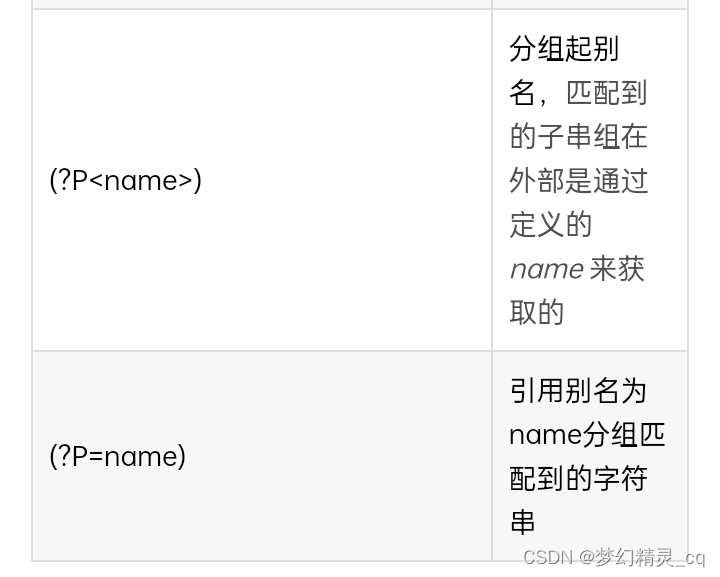
(本截屏图片来自: c s d n csdn csdn博文“python——正则表达式(re模块)详解”,可以点击蓝色文字跳转查阅。)
给分组取别名
f
f
f的Python代码
text = '''I have two feet, it has one foot.
She's singing a song.
canada bananas'''
result = re.findall(r'(\b\w*(?P<f>\w+)(?P=f)\w*\b)', text)
print(result)
给分组取别名
n
a
m
e
name
name的Python代码
text = '''I have two feet, it has one foot.
She's singing a song.
canada bananas'''
result = re.findall(r'(\b\w*(?P<name>\w+)(?P=name)\w*\b)', text)
print(result)
代码运行效果截屏图片
如图,两种写法都可以得到一样的结果。
事实上, n a m e name name可以是任意没有被 p y t h o n python python占用的非数字字符(如果是数字字符,可能会被误认为是序号引用),甚至可以是中文。
中文分组
n
a
m
e
name
name
result = re.findall(r'(\b\w*(?P<梦>\w+)(?P=梦)\w*\b)', text)
print(result)
n
a
m
e
name
name是下划线
result = re.findall(r'(\b\w*(?P<_>\w+)(?P=_)\w*\b)', text)
print(result)
4、别名引用与序号引用
p
y
t
h
o
n
python
python代码
regexStr = r'(\b\w*(?P<name>\w+)(?P=name)+(?P=name)*\w*\b)'
regex = compile(regexStr)
regexStr2 = r'(\b\w*(?P<name>\w+)(\2)(\2)*\w*\b)'
regex2 = compile(regexStr2)
regexStr3 = r'(\b\w*(?P<name>\w+)(?P=name)+(?P=name)*(?P=name)*\w*\b)'
regex3 = compile(regexStr3)
print(f"\n文本:\n{text}\n\nre通配表达式:\n1、“{regexStr}”,\n有{regex.groups}个分组{regex.findall(text)[0]};\n\n2、“{regexStr3}”,有{regex3.groups}个分组分组{regex3.findall(text)[0]};\n\n3、“{regexStr2}”,有{regex2.groups}个分组分组{regex2.findall(text)[0]}。\n")
代码运行效果截屏图片
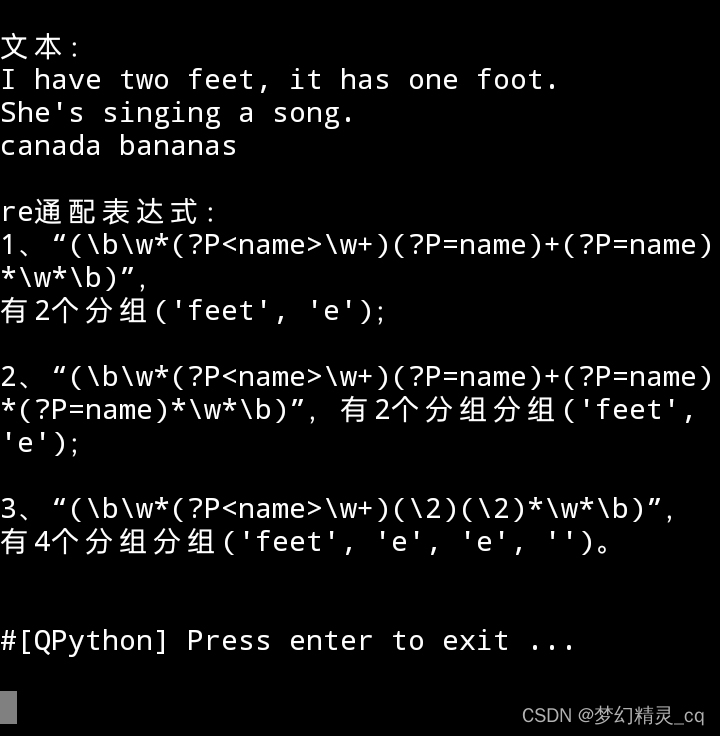
由代码及运行效果截屏图片可以看出,别名引用,不管用别名引用多少次,都只增加一个分组;而序号引用,一次引用算一个分组。再如:
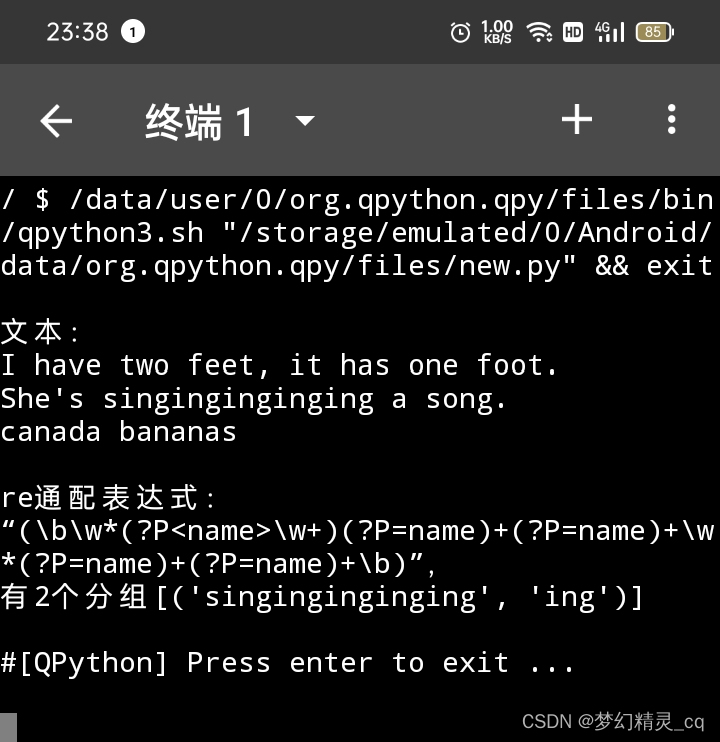
Python代码
text = '''I have two feet, it has one foot.
She's singinginginging a song.
canada bananas'''
regexStr = r'(\b\w*(?P<name>\w+)(?P=name)+(?P=name)+\w*(?P=name)+(?P=name)+\b)'
regex = compile(regexStr)
result = regex.findall(text)
if result:
print(f"\n文本:\n{text}\n\nre通配表达式:\n“{regexStr}”,\n有{regex.groups}个分组{result}")
else:
print(f"\n文本:\n{text}\n\nre通配表达式:\n“{regexStr}”,\n有{regex.groups}个分组,无法在文本中匹配。")
运行效果截屏图
Python代码
regexStr = r'(\b\w*(?P<name>\w+)(\2)+(\2)+\w*(\2)+(\2)+\b)'
运行效果截屏图

python代码
regexStr = r'(\b\w*(\w+)(\2)+(\2)+\w*(\2)+(\2)+\b)'
代码运行效果截屏
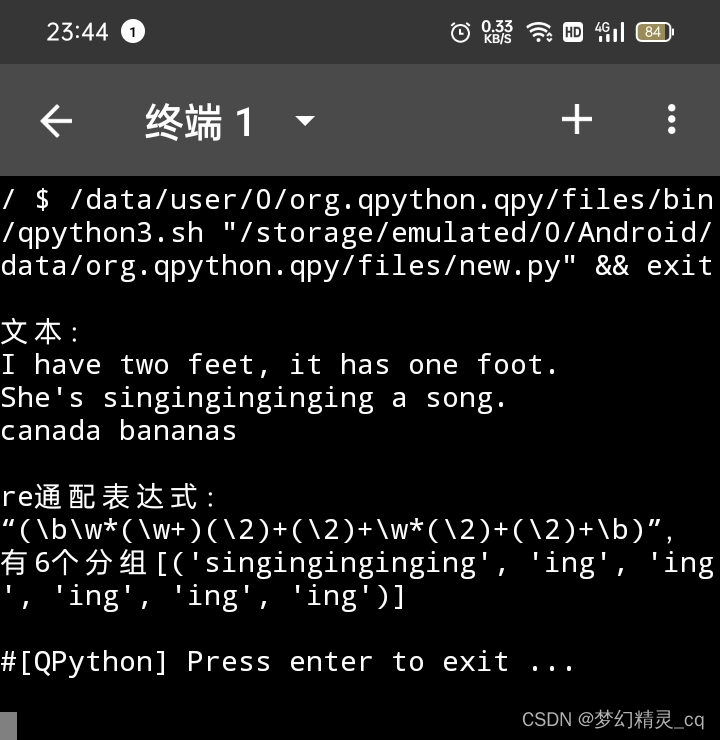
不管分组取没取别名,只要是用序号回引用,都是一样引用一次会增加一个分组。
5、参考文章
a
a
a、关于正则“反向引用(回溯)”的精彩分析文章
-
正则的回溯引用(搜索)
-
正则的回溯引用backreference如何使用
-
正则表达式的回溯使用
-
java正则反向匹配_正则表达式——反向引用
b b b、python——正则表达式(re模块)详解
6、本笔记样例完整源码(Python)
(源码较长,点此跳过源码)
#!/sur/bin/nve python
# coding: utf-8
import re
from re import compile
text = '''I have two feet, it has one foot.
She's singinginginging a song.
canada bananas'''
#regexStr = r'(\b\w*(?P<name>\w+)(?P=name)+(?P=name)+\w*(?P=name)+(?P=name)+\b)'
#regexStr = r'(\b\w*(?P<name>\w+)(\2)+(\2)+\w*(\2)+(\2)+\b)'
regexStr = r'(\b\w*(\w+)(\2)+(\2)+\w*(\2)+(\2)+\b)'
regex = compile(regexStr)
result = regex.findall(text)
if result:
print(f"\n文本:\n{text}\n\nre通配表达式:\n“{regexStr}”,\n有{regex.groups}个分组{result}")
else:
print(f"\n文本:\n{text}\n\nre通配表达式:\n“{regexStr}”,\n有{regex.groups}个分组,无法在文本中匹配。")
exit()
text = '''I have two feet, it has one foot.
She's singing a song.
canada bananas'''
result = re.findall(r'(\b\w*(?P<f>\w+)(?P=f)\w*\b)', text)
print(result)
result = re.findall(r'(\b\w*(?P<梦>\w+)(?P=梦)\w*\b)', text)
print(result)
result = re.findall(r'(\b\w*(?P<_>\w+)(?P=_)\w*\b)', text)
print(result)
regexStr = r'(\b\w*(?P<name>\w+)(?P=name)+(?P=name)*\w*\b)'
regex = compile(regexStr)
regexStr2 = r'(\b\w*(?P<name>\w+)(\2)(\2)*\w*\b)'
regex2 = compile(regexStr2)
regexStr3 = r'(\b\w*(?P<name>\w+)(?P=name)+(?P=name)*(?P=name)*\w*\b)'
regex3 = compile(regexStr3)
print(f"\n文本:\n{text}\n\nre通配表达式:\n1、“{regexStr}”,\n有{regex.groups}个分组{regex.findall(text)[0]};\n\n2、“{regexStr3}”,有{regex3.groups}个分组分组{regex3.findall(text)[0]};\n\n3、“{regexStr2}”,有{regex2.groups}个分组分组{regex2.findall(text)[0]}。\n")
exit()
regex = compile(regexStr)
regex2 = compile(regexStr2)
result = regex.findall(text)
print(f"\n文本:\n{text}\n\nre通配表达式:\n1、“{regexStr}”,\n有{regex.groups}个分组。\n\n2、“{regexStr2}”,有{regex2.groups}个分组。\n\n输出:\nre.findall函数匹配前面文本结果:\n{result}\n\n{'':~^40}")
上一篇: “当实力撑不起野心的时候,学习才是唯一的出路”(2023回顾与展望)(“当实力撑不起野心的时候,学习才是唯一的出路”,窃以此言铭已,以激励学习路上不懈怠。这是我今年最庆幸的事:窃得一条铭言💪)
下一篇:
我的HOT博:
本次共计收集289篇博文笔记信息,总阅读量44.72w。数据采集于2023年12月11日 23:07:13,用时5分11.8秒。阅读量不小于4.0k的有17篇。
- ChatGPT国内镜像站初体验:聊天、Python代码生成等
地址:https://blog.csdn.net/m0_57158496/article/details/129035387
浏览阅读:6.2w
点赞:127 收藏:809 评论:71
(本篇笔记于2023-02-14 23:46:33首次发布,最后修改于2023-07-03 05:50:55)
- 让QQ群昵称色变的神奇代码
地址:https://blog.csdn.net/m0_57158496/article/details/122566500
浏览阅读:5.8w
点赞:24 收藏:86 评论:17
(本篇笔记于2022-01-18 19:15:08首次发布,最后修改于2022-01-20 07:56:47)
- Python列表(list)反序(降序)的7种实现方式
地址:https://blog.csdn.net/m0_57158496/article/details/128271700
浏览阅读:9.9k
点赞:5 收藏:30 评论:8
(本篇笔记于2022-12-11 23:54:15首次发布,最后修改于2023-03-20 18:13:55)
- pandas 数据类型之 DataFrame
地址:https://blog.csdn.net/m0_57158496/article/details/124525814
浏览阅读:9.4k
点赞:7 收藏:34
摘要:pandas 数据类型之 DataFrame_panda dataframe。
(本篇笔记于2022-05-01 13:20:17首次发布,最后修改于2022-05-08 08:46:13)
- 个人信息提取(字符串)
地址:https://blog.csdn.net/m0_57158496/article/details/124244618
浏览阅读:7.7k
摘要:个人信息提取(字符串)_python个人信息提取。
(本篇笔记于2022-04-18 11:07:12首次发布,最后修改于2022-04-20 13:17:54)
- Python字符串居中显示
地址:https://blog.csdn.net/m0_57158496/article/details/122163023
浏览阅读:7.2k
评论:1
- 罗马数字转换器|罗马数字生成器
地址:https://blog.csdn.net/m0_57158496/article/details/122592047
浏览阅读:7.2k
(本篇笔记于2022-01-19 23:26:42首次发布,最后修改于2022-01-21 18:37:46)
- 斐波那契数列的递归实现和for实现
地址:https://blog.csdn.net/m0_57158496/article/details/122355295
浏览阅读:5.6k
点赞:4 收藏:2 评论:8
- 回车符、换行符和回车换行符
地址:https://blog.csdn.net/m0_57158496/article/details/123109488
浏览阅读:5.5k
点赞:2 收藏:3
摘要:回车符、换行符和回车换行符_命令行回车符。
(本篇笔记于2022-02-24 13:10:02首次发布,最后修改于2022-02-25 20:07:40)
- python清屏
地址:https://blog.csdn.net/m0_57158496/article/details/120762101
浏览阅读:5.3k
- 练习:字符串统计(坑:f‘string‘报错)
地址:https://blog.csdn.net/m0_57158496/article/details/121723096
浏览阅读:5.1k
- 练习:尼姆游戏(聪明版/傻瓜式•人机对战)
地址:https://blog.csdn.net/m0_57158496/article/details/121645399
浏览阅读:5.1k
点赞:14 收藏:44
- 我的 Python.color() (Python 色彩打印控制)
地址:https://blog.csdn.net/m0_57158496/article/details/123194259
浏览阅读:4.6k
点赞:2 收藏:8
摘要:我的 Python.color() (Python 色彩打印控制)_python color。
(本篇笔记于2022-02-28 22:46:21首次发布,最后修改于2022-03-03 10:30:03)
- 练习:生成100个随机正整数
地址:https://blog.csdn.net/m0_57158496/article/details/122558220
浏览阅读:4.6k
(本篇笔记于2022-01-18 13:31:36首次发布,最后修改于2022-01-20 07:58:12)
- 密码强度检测器
地址:https://blog.csdn.net/m0_57158496/article/details/121739694
浏览阅读:4.4k
(本篇笔记于2021-12-06 09:08:25首次发布,最后修改于2022-11-27 09:39:39)
- 罗马数字转换器(用罗马数字构造元素的值取模实现)
地址:https://blog.csdn.net/m0_57158496/article/details/122608526
浏览阅读:4.2k
(本篇笔记于2022-01-20 19:38:12首次发布,最后修改于2022-01-21 18:32:02)
- 练习:班里有人和我同生日难吗?(概率probability、蒙特卡洛随机模拟法)
地址:https://blog.csdn.net/m0_57158496/article/details/124424935
浏览阅读:4.0k
摘要:班里有人和我同生日难吗?(概率probability、蒙特卡洛随机模拟法)_生日模拟问题,计算频率,并画出随着试验次数n的增大,频率和理论概率的 关系图。
(本篇笔记于2022-04-26 12:46:25首次发布,最后修改于2022-04-27 21:22:07)
截屏图片

(此文涉及ChatPT,曾被csdn多次下架,前几日又因新发笔记被误杀而落马。躺“未过审”还不如回收站,回收站还不如永久不见。😪值此年底清扫,果断移除。留此截图,以识“曾经”。2023-12-31)

精品文章:
- 好文力荐:齐伟书稿 《python 完全自学教程》 Free连载(已完稿并集结成书,还有PDF版本百度网盘永久分享,点击跳转免费🆓下载。)
- OPP三大特性:封装中的property
- 通过内置对象理解python'
- 正则表达式
- python中“*”的作用
- Python 完全自学手册
- 海象运算符
- Python中的 `!=`与`is not`不同
- 学习编程的正确方法
来源:老齐教室
◆ Python 入门指南【Python 3.6.3】
好文力荐:
- 全栈领域优质创作者——[寒佬](还是国内某高校学生)博文“非技术文—关于英语和如何正确的提问”,“英语”和“会提问”是编程学习的两大利器。
- 【8大编程语言的适用领域】先别着急选语言学编程,先看它们能干嘛
- 靠谱程序员的好习惯
- 大佬帅地的优质好文“函数功能、结束条件、函数等价式”三大要素让您认清递归
CSDN实用技巧博文:
- 8个好用到爆的Python实用技巧
- python忽略警告
- Python代码编写规范
- Python的docstring规范(说明文档的规范写法)