本地k8s集群内一键部署grafana+prometheus
说明:
此一键部署grafana+Prometheus已包含:
- victoria-metrics 存储
- prometheus-server
- grafana
- prometheus-kube-state-metrics
- prometheus-node-exporter
- blackbox-exporter
grafana内已导入基础的dashboard【7个】和alert rule【29个】
注意:
grafana使用mysql数据库
1.下载压缩文件,解压prometheus+grafana.tar.gz
链接:https://pan.baidu.com/s/1apBAS4mPboKyH178npmJ0A?pwd=s6e5
提取码:s6e5
tar -xvf prometheus+grafana.tar.gz
kubectl create ns prometheus
cd prometheus+grafana/2.执行一键安装脚本import-prometheus.sh,替换变量
./import-prometheus.sh -h mysql数据库ip -u mysql用户 -p mysql密码 -a 泛域名地址 -k node节点名字 -n 项目标识
例:
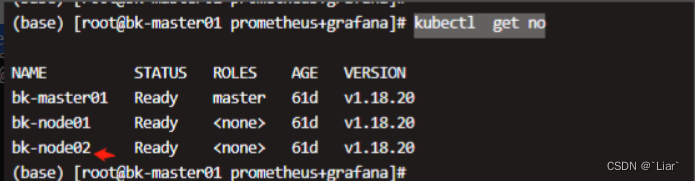
./import-prometheus.sh -h 100.64.22.195 -u mysql -p ****** -a testops.xxxxxxxx.com -k bk-node02 -n test-ops其中,-k 的node节点名字可通过kubectl get no得到,如图
-n 后的项目标识根据项目命名,可任意字符,如csp环境,csp
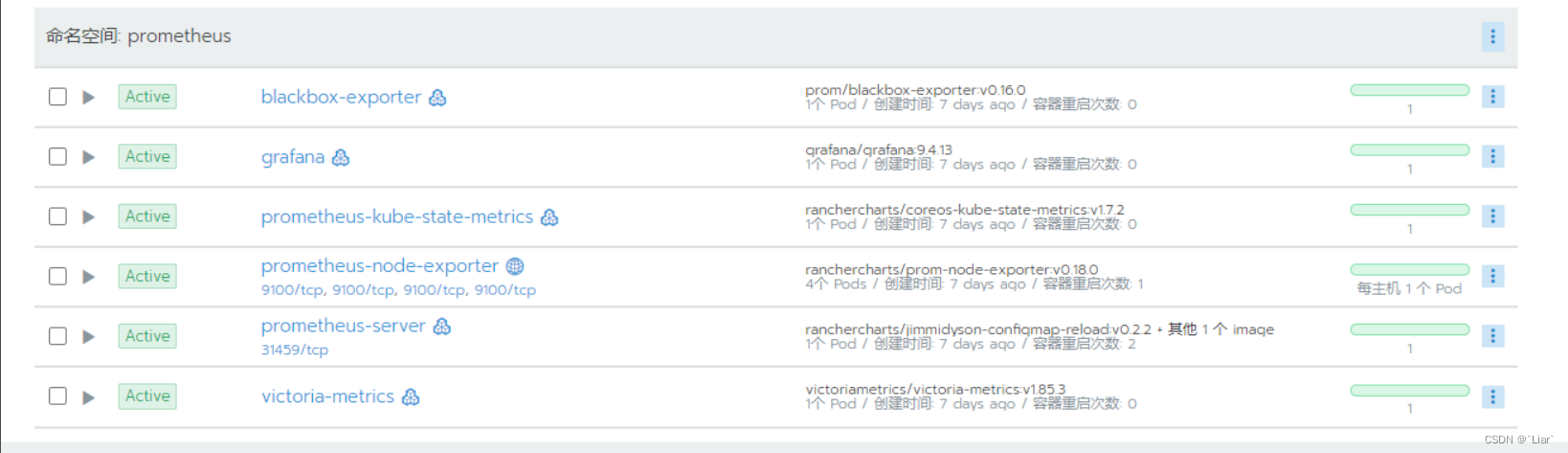
 执行成功后会有6个deployment
执行成功后会有6个deployment
3.根据ingress内配置的grafana域名,登录grafana。grafana.xxxxxxxx.com
账号:admin 密码:chinamcloud

常用的模板,告警规则都已存在
4.修改告警钉钉群为项目上的钉钉群
4.1 打开钉钉群,新建机器人,配置关键字告警,复制钉钉机器人地址
 4.2 打开grafana——》alert—-》修改ontact point,修改为4.1的钉钉机器人地址
4.2 打开grafana——》alert—-》修改ontact point,修改为4.1的钉钉机器人地址


问题:
1.ingress大屏未获取到数据
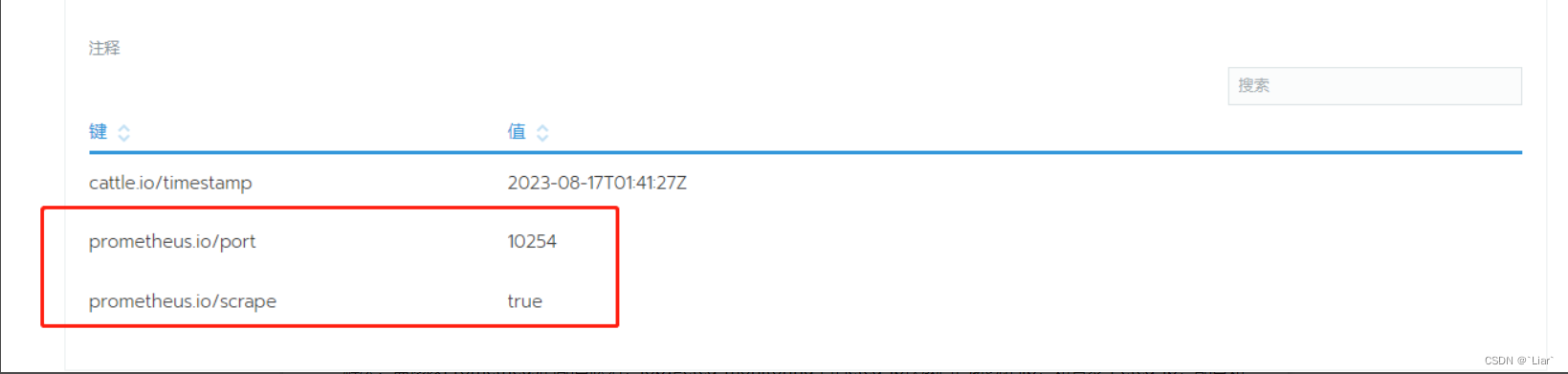
解决:ingress-nginx-controller的Deployment 下新增下面2个注释
prometheus.io/port=10254
prometheus.io/scrape=true
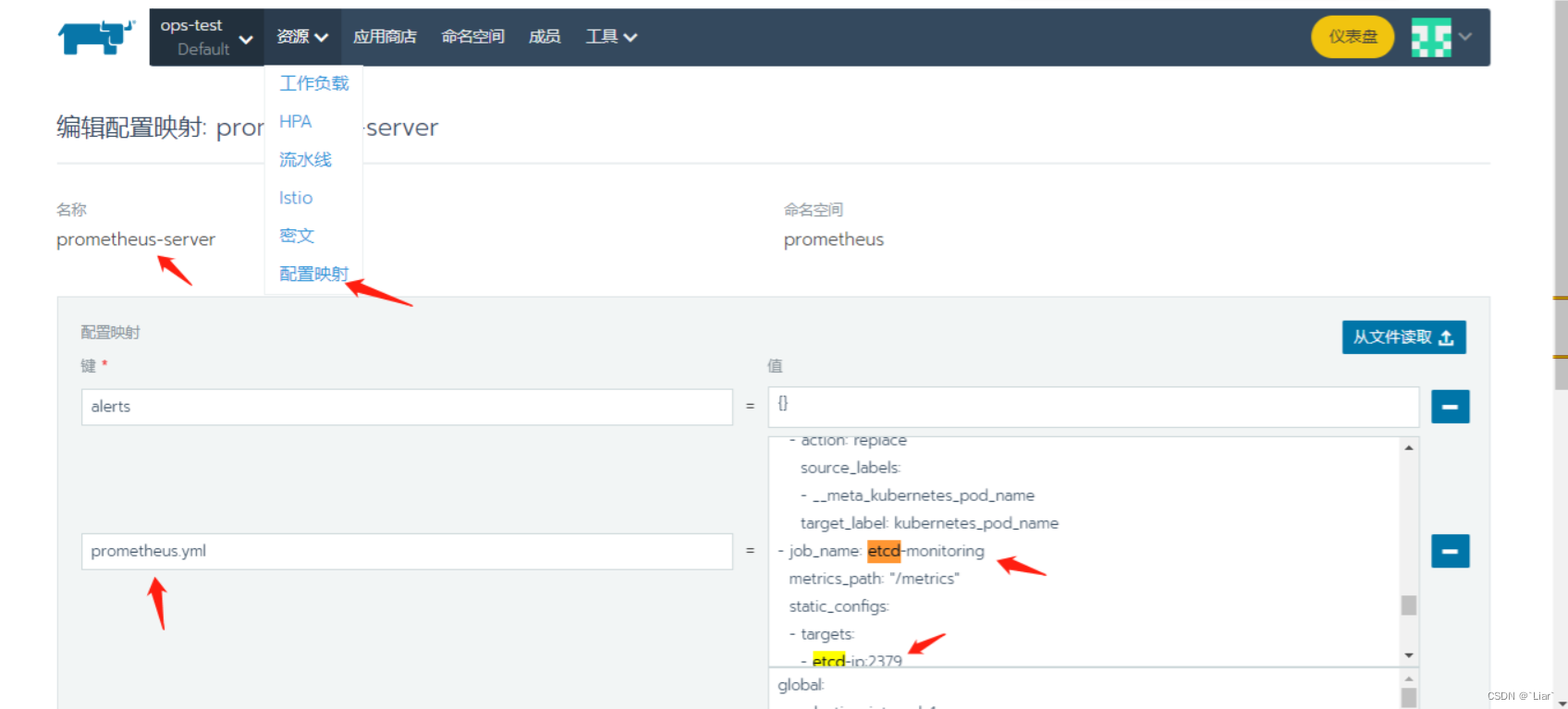
2.etcd大屏无数据
解决:需修改Prometheus的配置映射,job是etcd-monitoring下的etcd-ip换成自己环境的ip,如有多个etcd-ip,配置如下:
- job_name: etcd-monitoring
metrics_path: "/metrics"
static_configs:
- targets:
- etcd-ip1:2379
- etcd-ip2:2379
- etcd-ip3:2379