关键词:字典序排列 dfs 回溯 哈希
这种全排列题目可以考虑用下一个排列的方法做,这是最优解(方法四)
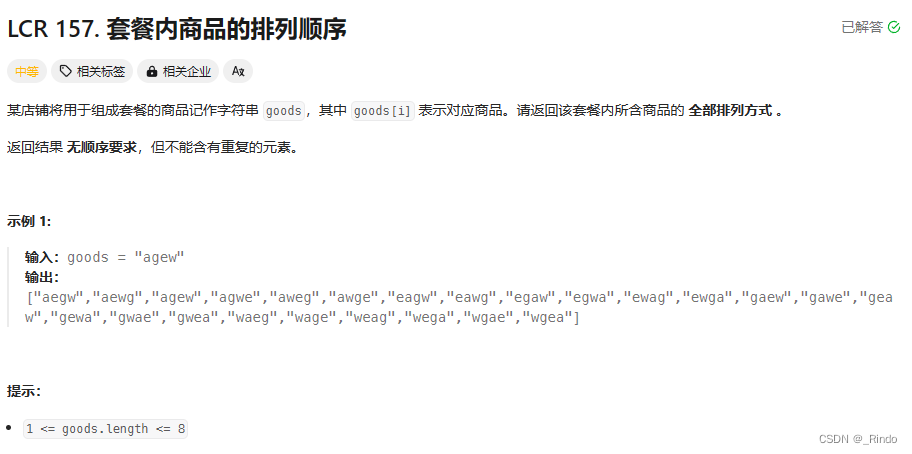
题目:套餐内商品的排列顺序
我的:[ 用时: 21 m 11 s ] 回溯 dfs 哈希表
方法一:我写的
回溯 dfs 哈希表
思路:
用dfs套路做。
避免重复结果的方法:
如果goods=aab,那么输出就会有aab aab aba aba baa baa,重复了。
为了避免重复,我在这里的办法是:
开辟一个哈希表,在存进结果之前先用哈希表检查这个字符串是不是已经在结果里面出现了,如果出现过了,就跳过不存。
if(count>=goods.size()) //dfs的中止条件,所有都填完了
{
auto p=hash.find(temp);//检查得到的单词是否有重复
if(p==hash.end()) //如果没有重复,则加入res
{
hash[temp]=1;
res.push_back(temp);
}//如果重复就跳过
return;
}复杂度计算:
时间复杂度O(n!n) 每一个结果都要算一遍
空间复杂度O(n*n+n!) 除了下文提到的,我还有一个哈希表

代码:
class Solution {
//关键:填字母
public:
vector<string> res;//记录结果
unordered_map<string,int> hash;//记录某个结果是否已经存在
vector<string> goodsOrder(string goods) {
vector<int> vis(goods.size());//记录这个字母的使用状态
string temp;
int count=0;//记录填到第几个字母
dfs(goods,temp,vis,count);//dfs
return res;
}
void dfs(string goods,string& temp,vector<int>& vis,int count)
{
if(count>=goods.size()) //dfs的中止条件,所有都填完了
{
auto p=hash.find(temp);//检查得到的单词是否有重复
if(p==hash.end()) //如果没有重复,则加入res
{
hash[temp]=1;
res.push_back(temp);
}//如果重复就跳过
return;
}
for(int i=0;i<goods.size();++i)//给第count位填字母,从goods里面选
{
if(vis[i]==1) continue;//如果这个字母已经被填过,就跳过
temp.push_back(goods[i]);//读取,填入temp
vis[i]=1;//记录 已经访问过
dfs(goods,temp,vis,count+1);//填下一个单词count+1
vis[i]=0;//回溯 vis
temp.pop_back();//回溯 temp
}
return;
}
};方法二:我写的 优化了方法一
回溯 dfs 哈希表
去掉了大的哈希表,减少空间复杂度,优化了时间。
添加了小的哈希表,查询每一位某个字母是否被用过。
思路:
避免重复结果的方法:
如果goods=aab,那么输出就会有aab aab aba aba baa baa,重复了。
为了避免重复,我在这里的办法是:
每一位都开辟一个哈希表,这个哈希表记录这一位已经填过的字母,比如goods=aab,第一位已经填了第一个a:axx,再次填第一位的时候,查询哈希表,发现第一位已经填过a了,所以这一位就不用再填a了,跳过。
auto p=vischar.find(goods[i]);//查询这一位是否填过goods[i]
if(vis[i]==1||p!=vischar.end()) continue;//如果这个字母在这个字符串中被填过或者这个字母在这一位被填过,剪枝
vischar[goods[i]]=1;//记录 填过这个字母复杂度计算:
时间复杂度O(n!n)
空间复杂度O(n*n)
代码:
class Solution {
public:
vector<string> res;//记录结果
vector<string> goodsOrder(string goods) {
vector<int> vis(goods.size());//记录这个字母的使用状态
string temp;
int count=0;//记录填到第几个字母
dfs(goods,temp,vis,count);//dfs
return res;
}
void dfs(string goods,string& temp,vector<int>& vis,int count)
{
if(count>=goods.size()) //dfs的中止条件,所有都填完了
{
res.push_back(temp);
return;
}
unordered_map<char,int> vischar;//记录这一位填过的字母
for(int i=0;i<goods.size();++i)//遍历每一种条件
{
auto p=vischar.find(goods[i]);//查询这一位是否填过goods[i]
if(vis[i]==1||p!=vischar.end()) continue;//如果这个字母在这个字符串中被填过或者这个字母在这一位被填过,剪枝
vischar[goods[i]]=1;//记录 填过这个字母
temp.push_back(goods[i]);//载入temp
vis[i]=1;//记录 这个字符串的这个字母已经访问过
dfs(goods,temp,vis,count+1);
vis[i]=0;//回溯 vis
temp.pop_back();//回溯 temp
}
return;
}
};方法三:
我写的:回溯 dfs 先快排 利用快排进行查重
依据方法二,可以用快排把小的哈希表优化掉。
思路:
避免重复结果的方法:
如果goods=aab,那么输出就会有aab aab aba aba baa baa,重复了。
为了避免重复,方法三这里的办法是:
先给goods快排。比如abaa,快排成aaab。
每次填字母,都按顺序从第一个可以填的字母开始填:查询当前字母goods[i]和上一个字母goods[i-1]是否相同如果相同,并且如果vis[i-1]==0,说明这个字母已经在这一位被填过了,不需要再在这一位填这个字母了,跳过。
必须要有vis[i-1]==0的判断,因为:我们要从第一个可以填的字母开始填
比如:
count=0,填第一位,填第一个a:temp=axxx,此时状态。
| vis | 1 | 0 | 0 | 0 |
| goods | a | a | a | b |
count=1,填第二位,我们想要填第二个a,vis[i-1]==1,不会跳过,成功填上。
| vis | 1 | 1 | 0 | 0 |
| goods | a | a | a | b |
再次回到填第一位的状态:
count=0,填第一位,我们想要填第二个a时,vis[i-1]==0,跳过了。我们只要第一个可以填的,这是第二个,所以不行。
如果没有这个vis[i-1]==0的判断,aaab aab ab都只会输出ab。
if(vis[i]==1||(i>0&&vis[i-1]==0&&goods[i]==goods[i-1])) continue;复杂度计算:
时间复杂度O(n!n) 快排nlogn
空间复杂度O(n+n) vis->n 递归->n
代码:
class Solution {
public:
vector<string> res;
vector<string> goodsOrder(string goods) {
sort(goods.begin(),goods.end());
vector<int> vis(goods.size());
string temp;
int count=0;
dfs(goods,temp,vis,count);
return res;
}
void dfs(string goods,string& temp,vector<int>& vis,int count)
{
if(count>=goods.size())
{
res.push_back(temp);
return;
}
for(int i=0;i<goods.size();++i)
{
if(vis[i]==1||(i>0&&vis[i-1]==0&&goods[i]==goods[i-1])) continue;
temp.push_back(goods[i]);
vis[i]=1;
dfs(goods,temp,vis,count+1);
vis[i]=0;
temp.pop_back();
}
return;
}
};方法四:最优解
用的是下一个排列请看笔记。leetcode31有。
思路:

复杂度计算:
时间复杂度O(n!n)
空间复杂度O(1)

代码:
class Solution {
public:
bool nextPermutation(string& goods) {
bool stage=false;//如果没有找到goods[i]<goods[i+1],比如654321,则返回false,说明已经找完了
int i=goods.size()-2;
while(i>=0&&goods[i]>=goods[i+1])
{
--i;
}
if(i>=0)
{
stage=true;
int j=goods.size()-1;
while(j>=0&&goods[i]>=goods[j])
{
--j;
}
swap(goods[i],goods[j]);
}
reverse(goods.begin()+i+1,goods.end());
return stage;
}
vector<string> goodsOrder(string goods) {
vector<string> res;
sort(goods.begin(),goods.end());
res.push_back(goods);
while(nextPermutation(goods))
{
res.push_back(goods);
}
return res;
}
};




![[易语言]易语言部署yolox的onnx模型](https://img-blog.csdnimg.cn/direct/6f91a98289da4c2d825e1245af03ddc7.jpeg)