机器学习项目中最冗长的步骤通常是数据清洗和预处理,Scikit-learn库中的Pipeline和 and ColumnTransformer通过一次封装替代逐步运行transformation步骤,从而减少冗余代码量。
1. Pipeline vs. ColumnTransformer
训练模型前,需要将数据集分为训练集和测试集。每个子集都需要经过数据清洗和预处理步骤,因而会造成代码冗余。
Pipeline是一个将所有数据操作步骤串成流程的工具,能够简洁地搭建模型训练工作流(下图)。
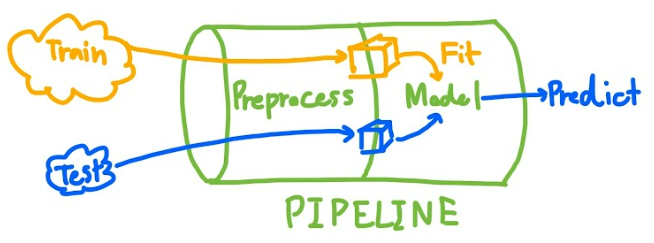
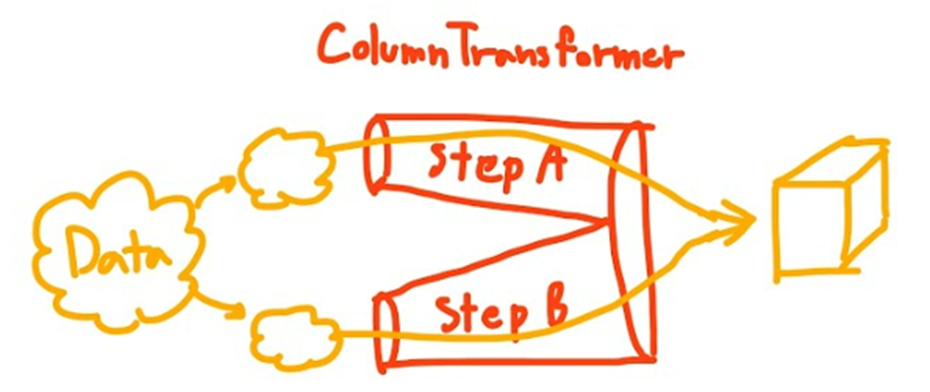
ColumnTransformer将分别转换不同组别的列,然后在合并到一起。
2. 用例
示例代码如下:
https://gitee.com/rysben/public/blob/master/datasets/HR_Analytics/pipeline.ipynb
参考
How to Improve Machine Learning Code Quality with Scikit-learn Pipeline and ColumnTransformer