目录
介绍:
一、Gaussian Naive Bayes(连续型变量)
1.1数据处理
1.2建模
1.3cross_val_score函数评估
1.4classification_report函数评估
1.5classification_report函数和cross_val_score函数的区别
二、 Multinomial Naive Bayes(离散型变量)
2.1数据处理
2.2建模
2.3CountVectorizer举例说明
介绍:
贝叶斯算法是一种基于概率模型的分类算法,它利用贝叶斯定理来对待分类样本进行概率推断。贝叶斯定理是一种条件概率关系,它的核心思想是根据已知的先验概率和新的证据信息,来更新对事件发生概率的估计。
贝叶斯算法的基本步骤如下:
- 收集和准备数据集:收集已知样本,对数据进行清洗和预处理,确保数据的质量和准确性。
- 计算先验概率:根据已知样本的类别标签,计算各个类别的先验概率,即在没有其他信息的情况下,每个类别发生的概率。
- 计算条件概率:对于每个类别,计算每个特征的条件概率,即在该类别下,每个特征取某个值的概率。
- 利用贝叶斯定理进行分类:对于待分类样本,计算其在每个类别下的后验概率,即给定待分类样本的特征值条件下,该样本属于每个类别的概率。
- 选择概率最大的类别作为最终分类结果。
贝叶斯算法的优点包括:
- 算法简单,实现容易;
- 对小样本数据和多类别分类问题表现良好;
- 可以通过增量学习来处理在线分类问题。
然而,贝叶斯算法也存在一些缺点:
- 对于输入特征之间存在强相关性的数据,算法性能可能会下降;
- 对于输入特征空间过大的数据,算法的计算复杂度较高;
- 贝叶斯算法假设特征之间相互独立,当这个假设不成立时,算法的分类效果不佳。
贝叶斯算法在文本分类、垃圾邮件过滤、情感分析等领域具有广泛应用。
贝叶斯公式是一种统计学概率定理,用于计算在已知一些先验信息的情况下,对于新的证据出现后,更新先验概率为后验概率的方法。
公式表达为:P(A|B) = P(B|A) * P(A) / P(B)
其中,P(A|B)表示在已知B发生的情况下,A发生的概率,称为后验概率。P(B|A)表示在已知A发生的情况下,B发生的概率,称为似然函数。P(A)表示A发生的先验概率,P(B)表示B发生的先验概率。
对于一个给定的邮件,我们可以通过贝叶斯公式来计算它是垃圾邮件的概率。贝叶斯公式如下:
P(垃圾邮件|邮件) = P(邮件|垃圾邮件) * P(垃圾邮件) / P(邮件)
其中,P(垃圾邮件|邮件)表示给定邮件是垃圾邮件的概率,P(邮件|垃圾邮件)表示垃圾邮件中的邮件概率,P(垃圾邮件)表示任一邮件是垃圾邮件的概率,P(邮件)表示任一邮件的概率。
在垃圾邮件过滤中,我们可以通过以下步骤来计算一个邮件是垃圾邮件的概率:
1. 建立训练集:收集大量已经标记好的垃圾邮件和非垃圾邮件。
2. 提取特征:对每封邮件提取一些特征,比如关键词、发件人、附件等等。
3. 训练模型:根据训练集中的邮件和它们的标记,计算出每个特征在垃圾邮件和非垃圾邮件中的概率。
4. 过滤邮件:对于一个新的邮件,计算它是垃圾邮件的概率。根据设置的阈值,判断该邮件是否为垃圾邮件。
通过利用贝叶斯公式进行垃圾邮件过滤,可以提高过滤的准确性和效率。
一、Gaussian Naive Bayes(连续型变量)
高斯朴素贝叶斯(Gaussian Naive Bayes)是朴素贝叶斯分类算法的一种变体。它基于贝叶斯定理和假设特征之间的独立性。与其他朴素贝叶斯算法类似,高斯朴素贝叶斯用于分类问题,并假设特征之间的相关性可以通过计算协方差矩阵来建模。
与其他朴素贝叶斯算法不同的是,高斯朴素贝叶斯假设特征的概率分布为高斯分布。因此,它适用于特征是连续变量的情况。对于每个类别,算法计算每个特征的均值和方差,并使用这些统计量来估计每个特征的概率分布。在预测时,算法使用贝叶斯定理来计算样本属于每个类别的概率,并选择具有最高概率的类别作为预测结果。
高斯朴素贝叶斯算法的优点包括计算效率高、对缺失数据鲁棒性强和可处理大量的特征。然而,它的缺点是它对于特征之间的相关性的建模能力有限。
总而言之,高斯朴素贝叶斯是一种简单但有效的分类算法,适用于特征为连续变量的问题。它用于估计特征的概率分布,并使用贝叶斯定理进行分类预测。
1.1数据处理
import numpy as py#应用Gaussian Naive Bayes,连续型
import pandas as pd
df = pd.read_csv("Titanic.csv")
df.drop(['PassengerId','Name','SibSp','Parch','Ticket','Cabin','Embarked'],axis='columns',inplace=True)
X=df.drop('Survived',axis="columns")
y=df.Survived
dummies= pd.get_dummies(X.Sex)
X=pd.concat([X,dummies],axis='columns')
X.drop(['Sex','male'],axis='columns',inplace=True)
X.columns[X.isna().any()]#含空的
X['Age'].isnull().sum()#含空的个数
X.Age=X.Age.fillna(X.Age.mean())#均值赋给空的
1.2建模
from sklearn.model_selection import train_test_split#将数据分成测试和训练集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)#测试集占百分之三十,random_state=0随机抽取数据集里的成为测试集
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train,y_train)
model.score(X_test,y_test)
#结果:0.8575063613231552
y_test[0:10]
'''结果:1 1 0 0 1 0 0 0 1 1'''
model.predict(X_test[0:10])
#结果:array([1, 1, 0, 0, 1, 0, 0, 0, 1, 1], dtype=int64)
1.3cross_val_score函数评估
cross_val_score是一个用于评估模型性能的函数,它可以对模型进行交叉验证并返回每个验证的得分。它的基本语法如下:
cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
参数说明:
- estimator: 用于拟合数据的模型对象
- X: 特征数据
- y: 目标变量
- scoring: 使用哪个指标对模型进行评估,默认为None,即使用模型的score方法进行评估
- cv: 交叉验证的折数,默认为None,即使用默认的3折交叉验证
- n_jobs: 并行运行的作业数,默认为None,即使用单个作业运行
- verbose: 控制详细程度的整数,默认为0,即不输出任何信息
- fit_params: 额外的拟合参数,传递给estimator的fit方法
- pre_dispatch: 控制作业预分派的整数或字符串,默认为'2*n_jobs'
cross_val_score函数会将数据分成cv份,并返回每个验证的得分。得分可以用于对模型进行评估,例如取平均值作为模型的最终评分。交叉验证可以有效地评估模型的性能,并防止过拟合。
from sklearn.model_selection import cross_val_score
cross_val_score(GaussianNB(),X_train,y_train,cv=5)
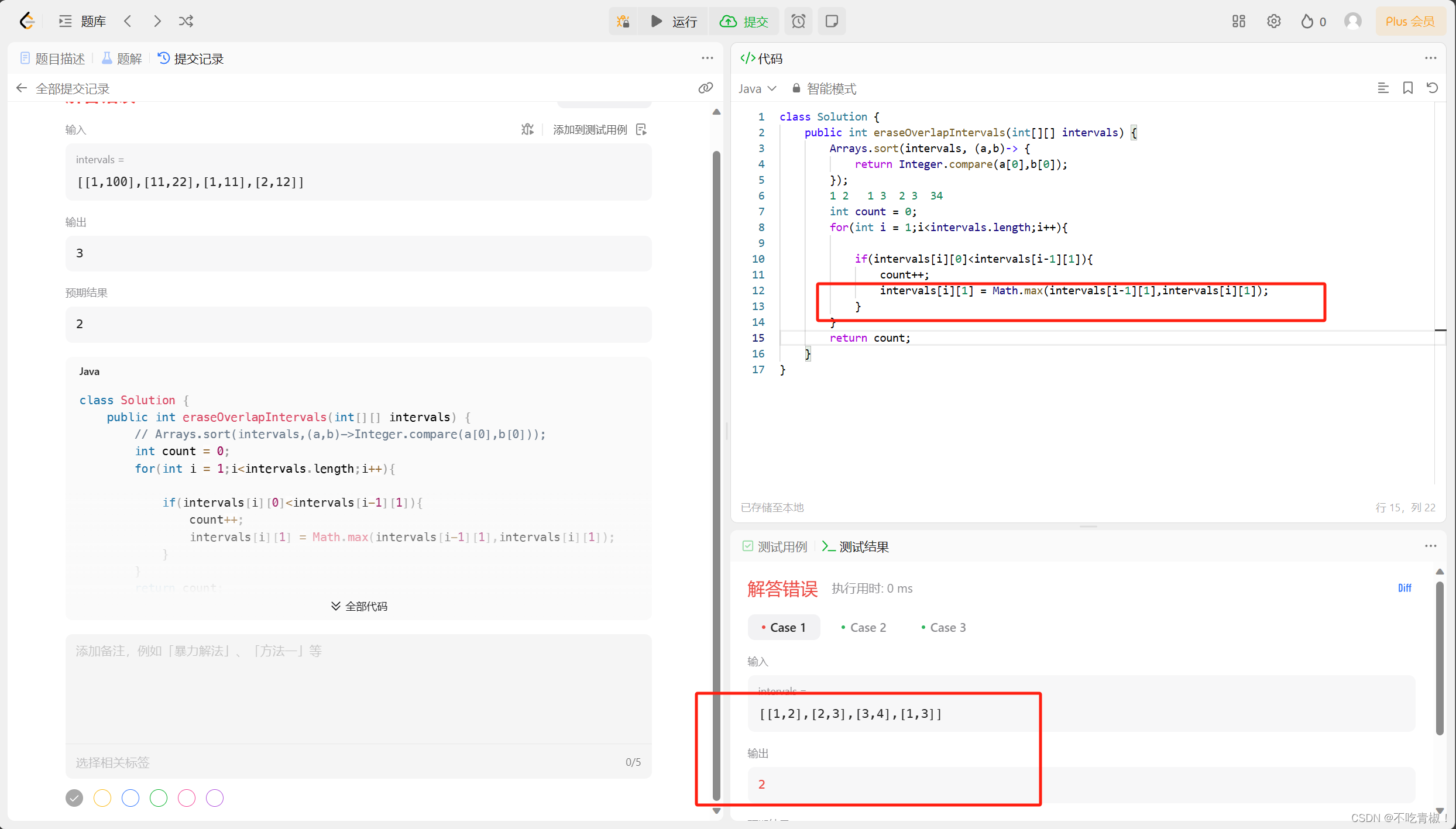
#结果:array([0.86956522, 0.80327869, 0.83606557, 0.83606557, 0.83060109])1.4classification_report函数评估
classification_report是一个用于评估分类模型性能的函数。它通常用在机器学习领域中,特别是在分类问题中。classification_report可以计算模型在不同类别上的精确率、召回率、F1分数和支持数等指标。
具体来说,classification_report会根据模型对样本进行预测的结果和真实标签之间的对比,计算出每个类别的精确率、召回率、F1分数和支持数。其中,精确率表示模型预测为某个类别的样本中,真实属于该类别的比例;召回率表示模型正确预测为某个类别的样本数占真实属于该类别的样本数的比例;F1分数是精确率和召回率的加权平均值,可以用来衡量模型在某个类别上的综合性能;支持数表示真实属于某个类别的样本数量。
通过使用classification_report,可以对分类模型的性能进行全面的评估,并且可以比较不同类别之间的性能差异。这对于选择合适的模型或者调整模型参数非常有帮助。
from sklearn.metrics import classification_report
print(classification_report(y_test[0:10],model.predict(X_test[0:10])))
'''结果:
precision recall f1-score support
0 1.00 1.00 1.00 5
1 1.00 1.00 1.00 5
accuracy 1.00 10
macro avg 1.00 1.00 1.00 10
weighted avg 1.00 1.00 1.00 10
'''1.5classification_report函数和cross_val_score函数的区别
classification_report和cross_val_score都是评估模型性能的工具,但是两者用途和计算方式有所不同。
classification_report是用于评估分类模型性能的工具,它主要用于计算模型的精确度、召回率、F1分数等指标。在使用classification_report之前,需要先计算模型的预测结果和真实结果,然后根据这些结果计算指标。classification_report适用于评估单个模型的性能。
cross_val_score是用于交叉验证评估模型性能的工具,它可以自动地将数据集划分为训练集和验证集,并计算模型的交叉验证分数。具体地,cross_val_score将数据集划分为k个子集,然后使用每个子集作为验证集,剩下的k-1个子集作为训练集。最后,将每次得到的模型性能评分的平均值作为模型的最终性能评分。cross_val_score适用于评估模型在不同数据集上的性能,因为它可以通过多次交叉验证来减少过拟合或欠拟合的影响。
综上所述,classification_report用于评估单个模型的性能,而cross_val_score用于评估模型在不同数据集上的性能。两者的计算方式和结果呈现方式也有所不同。
二、 Multinomial Naive Bayes(离散型变量)
Multinomial Naive Bayes是一种基于朴素贝叶斯算法的分类器,适用于处理离散特征数据的分类问题。它是朴素贝叶斯算法的扩展,用于处理多类别问题。
该算法假设每个特征的类别之间相互独立,并且特征之间的概率分布服从多项式分布。通过计算每个类别的概率,选择具有最高概率的类别作为预测结果。
Multinomial Naive Bayes广泛应用于文本分类问题,如垃圾邮件过滤、情感分析等。它在构建模型时只需要计算特征的频率,因此具有较高的速度和性能。
2.1数据处理
#离散变量,Multinomial Naive Bayes
df1 = pd.read_csv("spam.csv")
df1=df1.drop(df1.iloc[:,-3:],axis=1)
df1.groupby('v1').describe()
'''结果:
v2
count unique top freq
v1
ham 4825 4516 Sorry, I'll call later 30
spam 747 653 Please call our customer service representativ... 4
'''
dummies= pd.get_dummies(df1.v1)
X=pd.concat([df1,dummies],axis=1)
y=X.spam
X=X.v2
2.2建模
from sklearn.model_selection import train_test_split#将数据分成测试和训练集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)#测试集占百分之三十,random_state=0随机抽取数据集里的成为测试集
from sklearn.feature_extraction.text import CountVectorizer#向量,语言用向量表示
v = CountVectorizer()
X_train_T = v.fit_transform(X_train.values)
X_train_T.toarray()[:3]#在字典里是否出现
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(X_train_T,y_train)
X_test_T = v.transform(X_test)
model.score(X_test_T,y_test)
#结果:0.9838516746411483
emails = [
"hey moban, can we get together to watch football game tomorrow?",
"Upto 20% discount on parking, exclusive offer just for you. Dont miss this reward!"
]
emails_T = v.transform(emails)
model.predict(emails_T)#预测结果第一句不是垃圾邮件,第二句是,因为第二句出现discount折扣这类词
#结果:array([0, 1], dtype=uint8)2.3CountVectorizer举例说明
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()#初始化字典
X = vectorizer.fit_transform(corpus)#构建字典
vectorizer.get_feature_names_out()#字典
'''结果:
array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third',
'this'], dtype=object)
'''
print(X.toarray())#单词出现次数
'''结果:
[[0 1 1 1 0 0 1 0 1]
[0 2 0 1 0 1 1 0 1]
[1 0 0 1 1 0 1 1 1]
[0 1 1 1 0 0 1 0 1]]
'''
vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2))#初始化字典,两个词分割
X2 = vectorizer2.fit_transform(corpus)
vectorizer2.get_feature_names_out()
'''结果:
array(['and this', 'document is', 'first document', 'is the', 'is this',
'second document', 'the first', 'the second', 'the third',
'third one', 'this document', 'this is', 'this the'], dtype=object)
'''
print(X2.toarray())
'''结果:
[[0 0 1 1 0 0 1 0 0 0 0 1 0]
[0 1 0 1 0 1 0 1 0 0 1 0 0]
[1 0 0 1 0 0 0 0 1 1 0 1 0]
[0 0 1 0 1 0 1 0 0 0 0 0 1]]
'''
![[嵌入式C][入门篇] 快速掌握基础(9个语句)](https://img-blog.csdnimg.cn/direct/05930fad5523414990bad694bc64ed15.png)






![[论文分享]TimesURL:通用时间序列表示学习的自监督对比学习](https://img-blog.csdnimg.cn/img_convert/a67ef28dfba8ef5729d16357da243b0b.png)