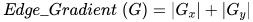0.LoFTR简介
Local Feature Transformers (LoFTR)是一种Detector-free的局部特征匹配方法,使用了具有自注意层和互注意层的Transformer模块来处理从卷积网络中提取的密集局部特征:首先在低特征分辨率(图像维度的1/8)上提取密集匹配,然后从这些匹配中选择具有高可信度的匹配,使用基于相关的方法将其细化到高分辨率的亚像素级别。这样,模型的大感受野使转换后的特征符能够体现出上下文和位置信息,通过多次自注意力和互注意层,LoFTR学习在GT中的匹配先验。另外,LOFTR还采用Linear Attention方法将计算复杂度降低到可接受的水平。
源码地址:https://github.com/zju3dv/LoFTR
论文下载地址:https://arxiv.org/pdf/2104.00680.pdf
在LoFTR之前的图像匹配算法中,都比较依赖于检测到的特征点,一旦点找不到,就没有办法完成匹配;对于位置不同的两个点,如果它们的背景特征相似或者说缺乏纹理特征,也会导致匹配失败。LoFTR的优势就是不需要先得到特征点,而且采用End2End的方式,用起来比较方便。
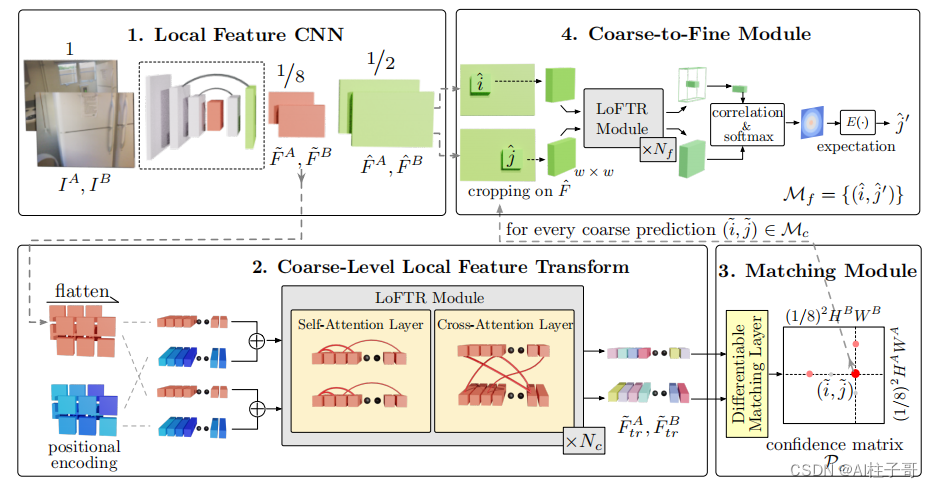
- 局部特征CNN从图像对中提取粗粒度特征图 F ~ A \tilde{F}^{A} F~A , F ~ B \tilde{F}^{B} F~B,以及细粒度特征图 F ^ A \hat{F}^{A} F^A , F ^ B \hat{F}^{B} F^B
- 粗粒度的特征经过flatten操作并添加位置编码,然后由LoFTR模块进行处理;该模块中包括自注意和互注意层,并重复
Nc 次 - 使用可微匹配层来匹配LoFTR模块输出的特征 F ~ t r A \tilde{F}_{tr}^{A} F~trA , F ~ t r B \tilde{F}_{tr}^{B} F~trB,得到一个置信矩阵 P c P_c Pc ,然后根据置信阈值和最近邻算法(MNN)选择匹配对,得到粗粒度的匹配预测 M c M_c Mc
- 对于每个粗粒度匹配对 ,从细粒度级特征图中裁剪一个大小为w*w的局部窗口,粗粒度匹配将在此窗口内细化为亚像素级别,并作为最终的匹配预测 M f M_f Mf
1.源码解析
源码的结构层次比较鲜明,在模型文件loftr.py的forward函数中,可以清晰的看到整个模型的前向路径:
- Local Feature CNN
- coarse-level loftr module
- match coarse-level
- fine-level refinement
- match fine-level
基础特征提取模块Local Feature CNN
通过CNN提取特征图
# 1. Local Feature CNN
data.update({
'bs': data['image0'].size(0),
'hw0_i': data['image0'].shape[2:], 'hw1_i': data['image1'].shape[2:]
})
if data['hw0_i'] == data['hw1_i']: # faster & better BN convergence
print(torch.cat([data['image0'], data['image1']], dim=0).shape)
feats_c, feats_f = self.backbone(torch.cat([data['image0'], data['image1']], dim=0))
print(feats_c.shape) # 1/8
print(feats_f.shape) # 1/2
(feat_c0, feat_c1), (feat_f0, feat_f1) = feats_c.split(data['bs']), feats_f.split(data['bs'])
print(feat_c0.shape)
print(feat_c1.shape)
print(feat_f0.shape)
print(feat_f1.shape)
else: # handle different input shapes
(feat_c0, feat_f0), (feat_c1, feat_f1) = self.backbone(data['image0']), self.backbone(data['image1'])
print(feat_c0.shape)
print(feat_c1.shape)
print(feat_f0.shape)
print(feat_f1.shape)
data.update({
'hw0_c': feat_c0.shape[2:], 'hw1_c': feat_c1.shape[2:],
'hw0_f': feat_f0.shape[2:], 'hw1_f': feat_f1.shape[2:]
})
这里的backbone就是一系列的卷积和连接操作,可以跳入self.backbone中去:
def forward(self, x):
# ResNet Backbone
x0 = self.relu(self.bn1(self.conv1(x)))
x1 = self.layer1(x0) # 1/2
x2 = self.layer2(x1) # 1/4
x3 = self.layer3(x2) # 1/8
# FPN
x3_out = self.layer3_outconv(x3)
x3_out_2x = F.interpolate(x3_out, scale_factor=2., mode='bilinear', align_corners=True)
x2_out = self.layer2_outconv(x2)
x2_out = self.layer2_outconv2(x2_out+x3_out_2x)
x2_out_2x = F.interpolate(x2_out, scale_factor=2., mode='bilinear', align_corners=True)
x1_out = self.layer1_outconv(x1)
x1_out = self.layer1_outconv2(x1_out+x2_out_2x)
return [x3_out, x1_out]
注意力机制应用 coarse-level loftr module
# 2. coarse-level loftr module
# add featmap with positional encoding, then flatten it to sequence [N, HW, C]
# 添加位置编码
feat_c0 = rearrange(self.pos_encoding(feat_c0), 'n c h w -> n (h w) c')
print(feat_c0.shape)
feat_c1 = rearrange(self.pos_encoding(feat_c1), 'n c h w -> n (h w) c')
print(feat_c1.shape)
mask_c0 = mask_c1 = None # mask is useful in training
if 'mask0' in data:
mask_c0, mask_c1 = data['mask0'].flatten(-2), data['mask1'].flatten(-2)
# 进入transformer模块,这是论文的核心模块
feat_c0, feat_c1 = self.loftr_coarse(feat_c0, feat_c1, mask_c0, mask_c1)
print(feat_c0.shape)
print(feat_c1.shape)
进入self.loftr_coarse模块,这里需要计算自身的attention注意力,还需要将两张图像计算cross attention,从代码中的循环中可以看到,self和cross两种操作分别是自己和自己计算注意力以及自己和其他特征图计算注意力,从layer的计算参数可以明确这一点。
def forward(self, feat0, feat1, mask0=None, mask1=None):
"""
Args:
feat0 (torch.Tensor): [N, L, C]
feat1 (torch.Tensor): [N, S, C]
mask0 (torch.Tensor): [N, L] (optional)
mask1 (torch.Tensor): [N, S] (optional)
"""
assert self.d_model == feat0.size(2), "the feature number of src and transformer must be equal"
for layer, name in zip(self.layers, self.layer_names):
if name == 'self':
feat0 = layer(feat0, feat0, mask0, mask0)
print(feat0.shape)
feat1 = layer(feat1, feat1, mask1, mask1)
print(feat1.shape)
elif name == 'cross':
feat0 = layer(feat0, feat1, mask0, mask1)
print(feat0.shape)
feat1 = layer(feat1, feat0, mask1, mask0)
print(feat1.shape)
else:
raise KeyError
print(feat0.shape)
print(feat1.shape)
return feat0, feat1
具体的计算layer在LoFTREncoderLayer定义中,这里就是基本的attention计算方法,主要是QKV的计算和一些线性计算、连接操作。
def forward(self, x, source, x_mask=None, source_mask=None):
"""
Args:
x (torch.Tensor): [N, L, C]
source (torch.Tensor): [N, S, C]
x_mask (torch.Tensor): [N, L] (optional)
source_mask (torch.Tensor): [N, S] (optional)
"""
bs = x.size(0)
query, key, value = x, source, source
# multi-head attention
query = self.q_proj(query).view(bs, -1, self.nhead, self.dim) # [N, L, (H, D)]
key = self.k_proj(key).view(bs, -1, self.nhead, self.dim) # [N, S, (H, D)]
value = self.v_proj(value).view(bs, -1, self.nhead, self.dim)
message = self.attention(query, key, value, q_mask=x_mask, kv_mask=source_mask) # [N, L, (H, D)]
message = self.merge(message.view(bs, -1, self.nhead*self.dim)) # [N, L, C]
message = self.norm1(message)
# feed-forward network
message = self.mlp(torch.cat([x, message], dim=2))
message = self.norm2(message)
return x + message
粗粒度匹配模块 match coarse-level
# 3. match coarse-level
self.coarse_matching(feat_c0, feat_c1, data, mask_c0=mask_c0, mask_c1=mask_c1)
跟入coarse_matching模块
通过注意力机制获取到两个图像的特征图,进入到粗粒度匹配模块,粗粒度匹配是采用的内积的计算方式,即下面代码的torch.einsum计算,然后通过softmax转成概率值。
def forward(self, feat_c0, feat_c1, data, mask_c0=None, mask_c1=None):
"""
Args:
feat0 (torch.Tensor): [N, L, C]
feat1 (torch.Tensor): [N, S, C]
data (dict)
mask_c0 (torch.Tensor): [N, L] (optional)
mask_c1 (torch.Tensor): [N, S] (optional)
Update:
data (dict): {
'b_ids' (torch.Tensor): [M'],
'i_ids' (torch.Tensor): [M'],
'j_ids' (torch.Tensor): [M'],
'gt_mask' (torch.Tensor): [M'],
'mkpts0_c' (torch.Tensor): [M, 2],
'mkpts1_c' (torch.Tensor): [M, 2],
'mconf' (torch.Tensor): [M]}
NOTE: M' != M during training.
"""
N, L, S, C = feat_c0.size(0), feat_c0.size(1), feat_c1.size(1), feat_c0.size(2)
# normalize
feat_c0, feat_c1 = map(lambda feat: feat / feat.shape[-1]**.5,
[feat_c0, feat_c1])
if self.match_type == 'dual_softmax':
sim_matrix = torch.einsum("nlc,nsc->nls", feat_c0,
feat_c1) / self.temperature
print(sim_matrix.shape)
if mask_c0 is not None:
sim_matrix.masked_fill_(
~(mask_c0[..., None] * mask_c1[:, None]).bool(),
-INF)
conf_matrix = F.softmax(sim_matrix, 1) * F.softmax(sim_matrix, 2)
print(conf_matrix.shape)
elif self.match_type == 'sinkhorn':
# sinkhorn, dustbin included
sim_matrix = torch.einsum("nlc,nsc->nls", feat_c0, feat_c1)
if mask_c0 is not None:
sim_matrix[:, :L, :S].masked_fill_(
~(mask_c0[..., None] * mask_c1[:, None]).bool(),
-INF)
# build uniform prior & use sinkhorn
log_assign_matrix = self.log_optimal_transport(
sim_matrix, self.bin_score, self.skh_iters)
assign_matrix = log_assign_matrix.exp()
conf_matrix = assign_matrix[:, :-1, :-1]
# filter prediction with dustbin score (only in evaluation mode)
if not self.training and self.skh_prefilter:
filter0 = (assign_matrix.max(dim=2)[1] == S)[:, :-1] # [N, L]
filter1 = (assign_matrix.max(dim=1)[1] == L)[:, :-1] # [N, S]
conf_matrix[filter0[..., None].repeat(1, 1, S)] = 0
conf_matrix[filter1[:, None].repeat(1, L, 1)] = 0
if self.config['sparse_spvs']:
data.update({'conf_matrix_with_bin': assign_matrix.clone()})
data.update({'conf_matrix': conf_matrix})
# predict coarse matches from conf_matrix
data.update(**self.get_coarse_match(conf_matrix, data))
跟入get_coarse_match模块
通过softmax获取到概率值之后,然后根据阈值使用mask矩阵过滤掉低于阈值的值,然后使用互最近邻来确定互相匹配关系。
def get_coarse_match(self, conf_matrix, data):
"""
Args:
conf_matrix (torch.Tensor): [N, L, S]
data (dict): with keys ['hw0_i', 'hw1_i', 'hw0_c', 'hw1_c']
Returns:
coarse_matches (dict): {
'b_ids' (torch.Tensor): [M'],
'i_ids' (torch.Tensor): [M'],
'j_ids' (torch.Tensor): [M'],
'gt_mask' (torch.Tensor): [M'],
'm_bids' (torch.Tensor): [M],
'mkpts0_c' (torch.Tensor): [M, 2],
'mkpts1_c' (torch.Tensor): [M, 2],
'mconf' (torch.Tensor): [M]}
"""
axes_lengths = {
'h0c': data['hw0_c'][0],
'w0c': data['hw0_c'][1],
'h1c': data['hw1_c'][0],
'w1c': data['hw1_c'][1]
}
_device = conf_matrix.device
# 1. confidence thresholding
mask = conf_matrix > self.thr
print(mask.shape)
mask = rearrange(mask, 'b (h0c w0c) (h1c w1c) -> b h0c w0c h1c w1c',
**axes_lengths)
print(mask.shape)
if 'mask0' not in data:
mask_border(mask, self.border_rm, False)
else:
mask_border_with_padding(mask, self.border_rm, False,
data['mask0'], data['mask1'])
mask = rearrange(mask, 'b h0c w0c h1c w1c -> b (h0c w0c) (h1c w1c)',
**axes_lengths)
print(mask.shape)
# 2. mutual nearest
print(conf_matrix.max(dim=2, keepdim=True)[0].shape)
mask = mask \
* (conf_matrix == conf_matrix.max(dim=2, keepdim=True)[0]) \
* (conf_matrix == conf_matrix.max(dim=1, keepdim=True)[0])
print(mask.shape)
# 3. find all valid coarse matches
# this only works when at most one `True` in each row
mask_v, all_j_ids = mask.max(dim=2)
print(mask_v.shape)
print(all_j_ids.shape)
b_ids, i_ids = torch.where(mask_v)
print(b_ids.shape)
print(i_ids.shape)
j_ids = all_j_ids[b_ids, i_ids]
print(j_ids.shape)
mconf = conf_matrix[b_ids, i_ids, j_ids]
print(mconf.shape)
# 4. Random sampling of training samples for fine-level LoFTR
# (optional) pad samples with gt coarse-level matches
if self.training:
# NOTE:
# The sampling is performed across all pairs in a batch without manually balancing
# #samples for fine-level increases w.r.t. batch_size
if 'mask0' not in data:
num_candidates_max = mask.size(0) * max(
mask.size(1), mask.size(2))
else:
num_candidates_max = compute_max_candidates(
data['mask0'], data['mask1'])
num_matches_train = int(num_candidates_max *
self.train_coarse_percent)
num_matches_pred = len(b_ids)
assert self.train_pad_num_gt_min < num_matches_train, "min-num-gt-pad should be less than num-train-matches"
# pred_indices is to select from prediction
if num_matches_pred <= num_matches_train - self.train_pad_num_gt_min:
pred_indices = torch.arange(num_matches_pred, device=_device)
else:
pred_indices = torch.randint(
num_matches_pred,
(num_matches_train - self.train_pad_num_gt_min, ),
device=_device)
# gt_pad_indices is to select from gt padding. e.g. max(3787-4800, 200)
gt_pad_indices = torch.randint(
len(data['spv_b_ids']),
(max(num_matches_train - num_matches_pred,
self.train_pad_num_gt_min), ),
device=_device)
mconf_gt = torch.zeros(len(data['spv_b_ids']), device=_device) # set conf of gt paddings to all zero
b_ids, i_ids, j_ids, mconf = map(
lambda x, y: torch.cat([x[pred_indices], y[gt_pad_indices]],
dim=0),
*zip([b_ids, data['spv_b_ids']], [i_ids, data['spv_i_ids']],
[j_ids, data['spv_j_ids']], [mconf, mconf_gt]))
# These matches select patches that feed into fine-level network
coarse_matches = {'b_ids': b_ids, 'i_ids': i_ids, 'j_ids': j_ids}
# 4. Update with matches in original image resolution
scale = data['hw0_i'][0] / data['hw0_c'][0]
scale0 = scale * data['scale0'][b_ids] if 'scale0' in data else scale
scale1 = scale * data['scale1'][b_ids] if 'scale1' in data else scale
mkpts0_c = torch.stack(
[i_ids % data['hw0_c'][1], i_ids // data['hw0_c'][1]],
dim=1) * scale0
mkpts1_c = torch.stack(
[j_ids % data['hw1_c'][1], j_ids // data['hw1_c'][1]],
dim=1) * scale1
# These matches is the current prediction (for visualization)
coarse_matches.update({
'gt_mask': mconf == 0,
'm_bids': b_ids[mconf != 0], # mconf == 0 => gt matches
'mkpts0_c': mkpts0_c[mconf != 0],
'mkpts1_c': mkpts1_c[mconf != 0],
'mconf': mconf[mconf != 0]
})
return coarse_matches
精细化调整 fine-level refinement
将特征图级别的匹配转换成像素点级别的匹配
# 4. fine-level refinement
# 预处理操作,拆解特征图,提取匹配到的候选点
feat_f0_unfold, feat_f1_unfold = self.fine_preprocess(feat_f0, feat_f1, feat_c0, feat_c1, data)
if feat_f0_unfold.size(0) != 0: # at least one coarse level predicted
feat_f0_unfold, feat_f1_unfold = self.loftr_fine(feat_f0_unfold, feat_f1_unfold)
这里self.loftr_fine也是进入到attention的计算,与粗粒度的计算时用的相同的算法
细粒度匹配 match fine-level
通过期望计算得到最终的输出结果
# 5. match fine-level
self.fine_matching(feat_f0_unfold, feat_f1_unfold, data)
跳入FineMatching的forward函数中
原文中使用55的矩阵进行细粒度匹配,这里匹配的时候会计算55矩阵中各个点与中间点的关系,生成热度图heatmap,然后计算这个热度图的期望dsnt.spatial_expectation2d,然后还原到图像中即可。
def forward(self, feat_f0, feat_f1, data):
"""
Args:
feat0 (torch.Tensor): [M, WW, C]
feat1 (torch.Tensor): [M, WW, C]
data (dict)
Update:
data (dict):{
'expec_f' (torch.Tensor): [M, 3],
'mkpts0_f' (torch.Tensor): [M, 2],
'mkpts1_f' (torch.Tensor): [M, 2]}
"""
M, WW, C = feat_f0.shape
W = int(math.sqrt(WW))
scale = data['hw0_i'][0] / data['hw0_f'][0]
self.M, self.W, self.WW, self.C, self.scale = M, W, WW, C, scale
# corner case: if no coarse matches found
if M == 0:
assert self.training == False, "M is always >0, when training, see coarse_matching.py"
# logger.warning('No matches found in coarse-level.')
data.update({
'expec_f': torch.empty(0, 3, device=feat_f0.device),
'mkpts0_f': data['mkpts0_c'],
'mkpts1_f': data['mkpts1_c'],
})
return
feat_f0_picked = feat_f0_picked = feat_f0[:, WW//2, :]
print(feat_f0_picked.shape)
sim_matrix = torch.einsum('mc,mrc->mr', feat_f0_picked, feat_f1)
print(sim_matrix.shape)
softmax_temp = 1. / C**.5
heatmap = torch.softmax(softmax_temp * sim_matrix, dim=1).view(-1, W, W)
print(heatmap.shape)
# compute coordinates from heatmap
coords_normalized = dsnt.spatial_expectation2d(heatmap[None], True)[0] # [M, 2]
print(coords_normalized.shape)
grid_normalized = create_meshgrid(W, W, True, heatmap.device).reshape(1, -1, 2) # [1, WW, 2]
print(grid_normalized.shape)
# compute std over <x, y>
var = torch.sum(grid_normalized**2 * heatmap.view(-1, WW, 1), dim=1) - coords_normalized**2 # [M, 2]
std = torch.sum(torch.sqrt(torch.clamp(var, min=1e-10)), -1) # [M] clamp needed for numerical stability
# for fine-level supervision
data.update({'expec_f': torch.cat([coords_normalized, std.unsqueeze(1)], -1)})
# compute absolute kpt coords
self.get_fine_match(coords_normalized, data)