编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
本期内容速览
01. CLaMP: 面向音乐信息检索的语言-音乐对比预训练
02. LUT-NN: 通过查找表实现的高效神经网络推理
03. Large Search Model: 在大模型时代重定义搜索框架
顶会聚焦
CLaMP: 面向音乐信息检索的语言-音乐对比预训练

论文链接:https://arxiv.org/abs/2304.11029
项目链接:https://ai-muzic.github.io/clamp/
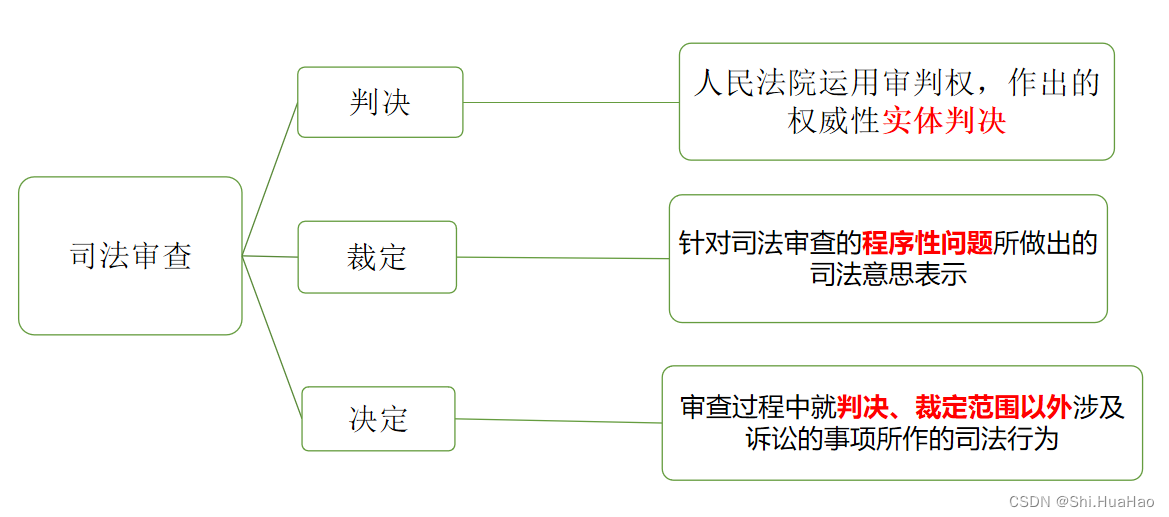
符号音乐信息检索是处理基于符号表示(如谱面或 MIDI 文件)的音乐的自动分析和检索领域。由于深度学习能够从大型数据集中提取复杂和抽象的音乐特征,因此在符号音乐信息检索中变得越来越流行。但大多数带标签的符号音乐数据集都规模较小,获取足够的带标签数据可能既昂贵又耗时。而语义搜索和零样本分类技术可以用来检索和标记大量未标记的数据。这些技术将可以让使用者能够通过给定的开放领域查询(例如,“快节奏的欢快音乐”)搜索音乐,或者根据定制标签自动识别音乐特征,且无需训练数据。
若想实现符号音乐的语义搜索和零样本分类,就需要建立音乐和语言之间的联系。为此,微软亚洲研究院的研究员们提出了 CLaMP:对比语言-音乐预训练,通过使用与对比损失一起训练的文本编码器和音乐编码器,来学习自然语言和符号音乐之间的交叉模态表示。为了预训练 CLaMP,这一研究收集了一个包含140万个音乐-文本对的大型数据集。它采用文本丢失作为数据增强技术,并使用小节分块技术来有效表示音乐数据,将序列长度缩短到小于10%。此外,该研究还提出了一个掩码音乐模型的预训练目标,以增强音乐编码器对音乐上下文和结构的理解。
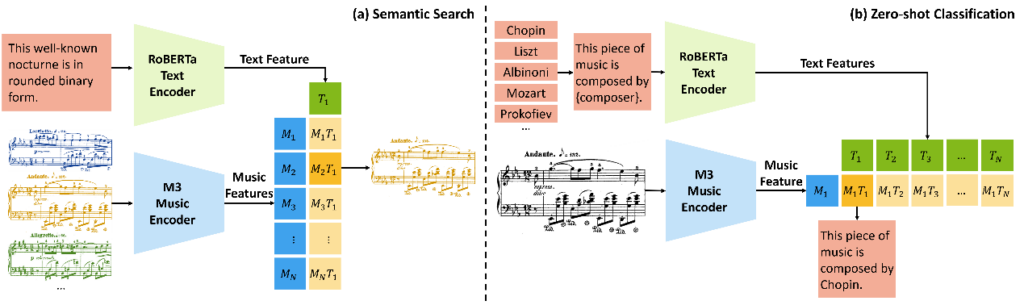
图1:CLaMP 执行跨模态符号音乐信息检索任务的过程,包括语义搜索和零样本分类,而无需特定任务的训练数据
实验表明,CLaMP 整合文本信息,实现了符号音乐的语义搜索和零样本分类,超越了先前模型的能力。与需要微调的目前最先进的模型相比,零样本的 CLaMP 在以乐谱为导向的数据集上展示出了与之相当或更优越的性能。该论文已被 ISMIR 2023 接收,并荣获最佳学生论文奖。
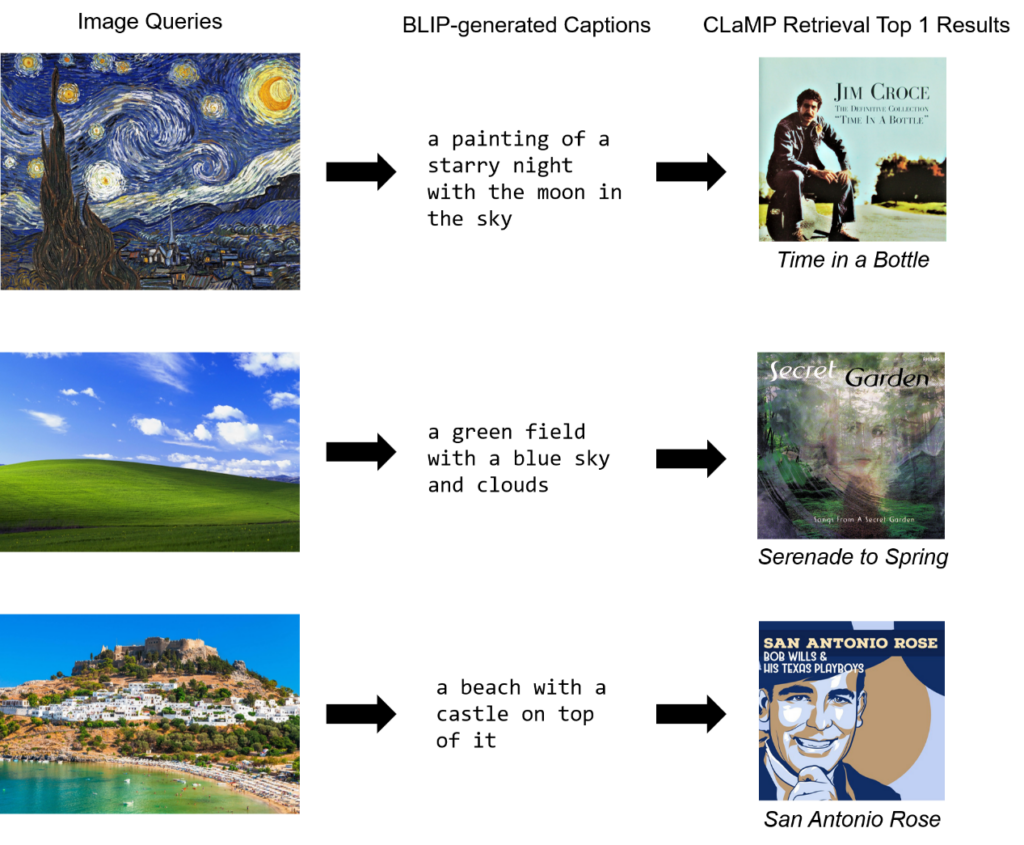
图2:基于 BLIP 生成标题的图像推荐音乐的结果
LUT-NN: 通过查找表实现的高效神经网络推理

论文链接:https://dl.acm.org/doi/10.1145/3570361.3613285
项目链接:https://github.com/lutnn
深度神经网络推理面临着张量计算的高硬件开销,以及张量算子开发的高人力成本。为了解决这一问题,微软亚洲研究院的研究员们创新地提出了 LUT-NN 深度神经网络推理系统。如图所示,LUT-NN 可以将网络推理中的线性计算算子转化为查表操作,从而省去了算子计算和实现的成本。
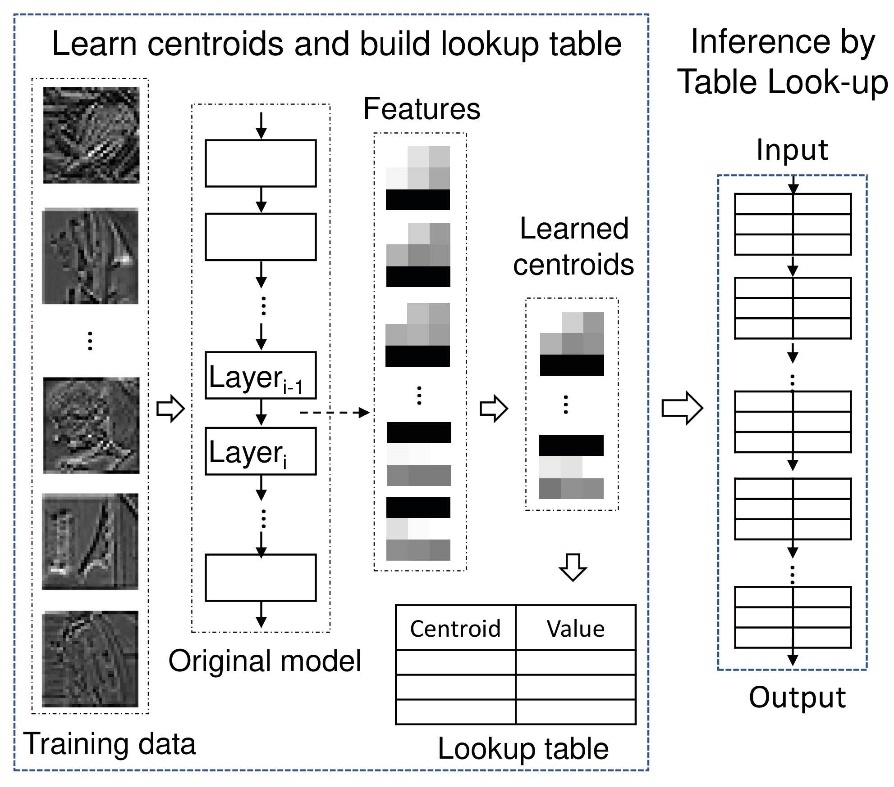
图3: LUT-NN 模型转换示例
为实现查表,研究员们从深度神经网络每层的计算出发。DNN 模型的每一层通常是将输入特征转换为更高级别的特征。即使是不同的输入数据,DNN 模型中每一层的特征也存在着语义上的相似性。LUT-NN 通过学习每个线性计算算子的典型特征(称为中心点 “centroid”),预先计算这些特征的结果来作为查找表(Look-up Tables, LUT)。在推理时,LUT-NN 可以直接从查找表中读取与输入特征最接近中心点的计算结果,作为该算子的近似输出。为了提高 LUT-NN 的准确性,LUT-NN 还采用了可微中心点学习(differentiable centroid learnings)技术。通过模型训练过程中的反向传播,LUT-NN 可以通过调整中心点,最小化 LUT-NN 模型的精度损失。此外,研究员们还优化了 LUT-NN 的推理执行,通过提升并行性、减少内存访问、充分利用已有的硬件加速指令等方式提升了模型的推理性能。
LUT-NN 在包括图像识别、语音识别和自然语言处理等多种领域的任务上进行了评估。与传统方法相比,LUT-NN 在保持相似的模型准确度的同时,显著减少了各项推理成本。其中:浮点运算 FLOPs 最多减少到1/16,模型大小最多减少到1/7,延迟最多减少到1/6.8,内存最多减少到1/6.5,功耗最多减少到41.7%。LUT-NN 首次使用了查找表来简化DNN推理过程,并且通过可微中心点的方式降低了模型训练成本,同时还保持了模型的准确度。这种方法为移动设备上的 DNN 推理提供了一种新的、效率更高的解决方案。该论文已被 MobiCom 2023 大会接受。
arXiv精选
Large Search Model: 在大模型时代重定义搜索框架

论文链接:https://arxiv.org/pdf/2310.14587.pdf
搜索引擎是十分重要的信息获取工具。当代搜索引擎包含一系列不同的模块,包括查询(query)理解、检索、多级排序和问答等。但这些模块往往是独立优化和部署的,缺少端到端的训练来优化整体的搜索体验。
对此,微软亚洲研究院的研究员们提出了一种称为“大型搜索模型”(Large Search Model)的新搜索概念框架,将不同的搜索模块统一成一个用于搜索的大型语言模型。在这个框架下,研究员们将各种搜索模块都转化为自回归任务,利用大型语言模型强大的理解和推理能力,在简化复杂搜索模块的同时提供更好的搜索结果。
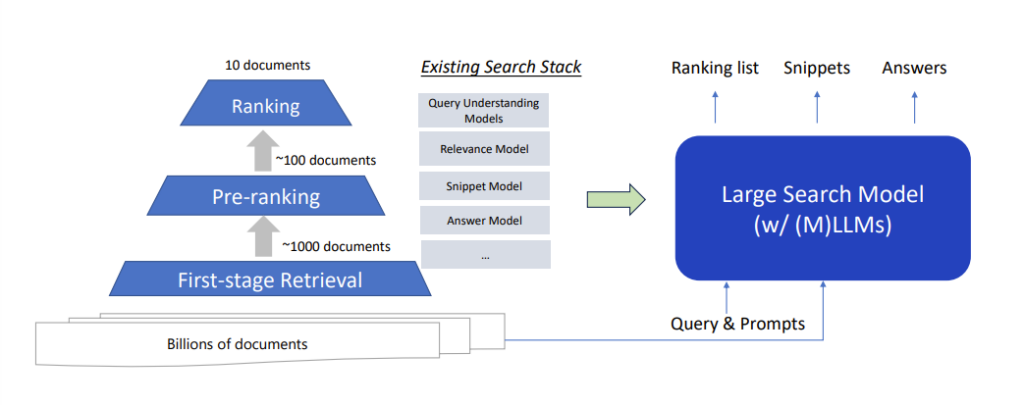
图4:Large Search Model 框架示意图
在传统搜索引擎中,检索模块负责根据用户查询从海量文档中返回数千相关文档,再通过多个不同的排序模块逐步从数千文档中筛选出最相关的数个文档,最后基于最相关的文档进行摘要抽取和问答等动作,从而生成搜索引擎结果页面(SERP)。而在新的 Large Search Model 框架中,则是使用一个大型语言模型作为一个统一的搜索模型,将检索返回的数千文档同时作为语言模型的输入,然后直接输出整个SERP,包括排序列表、摘要、问答结果等等。
为了实现此目标,研究员们认为 Large Search Model 应该具有统一建模多种检索任务的能力、通过提示词进行定制的能力、长文本建模能力和多模态处理能力。此外,语言模型的推理效率、幻觉和一致性也是实际中需要考虑的问题。研究员们在 MS-MARCO 数据集上进行了初步的实验。检索结果排序(表1)和结果生成(表2)的实验,都取得了优于基线的结果。
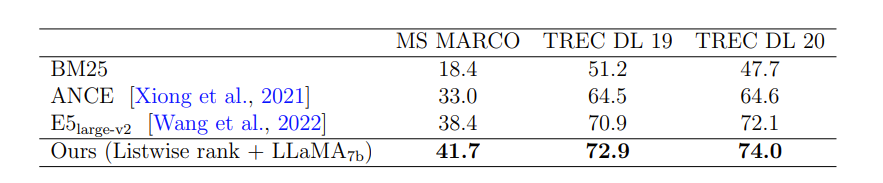
表1:列表排序的初步实验结果

表2:答案摘要生成结果示例
在未来,研究员们希望能在更大规模的真实场景下进行实验,并为搜索引擎的研究提供一种新的思路。