💫Hello World!
对于大家来说Hello World!应该是最熟悉不过的一句话,我们从Hello World!走进了计算机的世界,但是你真的了解Hello World!吗?你又思考过它背后蕴含的机理吗?他是怎么从代码变成程序的你真的思考过吗?
今天本篇文章会对它的底层做最基本的讲解,后续博主会再次对它进行深入解析!!
那么我们开始吧!!
💫被隐藏的部分——编译与链接
对于visual studio这样的集成开发平台(编译,链接,调试集一体),要看到细节是很难的,所有本文将使用Linux的gcc编译器进行操作。
一个源文件变成可执行程序需要经过以下几个步骤:
1.预处理(也叫预编译) 2.编译 3.汇编 4.链接
每个步骤又包含有许多小步骤。
⭐️预处理
预处理的工作主要有以下:
1.宏替换(删除所有的“#define”,展开所有的宏)
2.条件编译
3.头文件包含
4.去注释
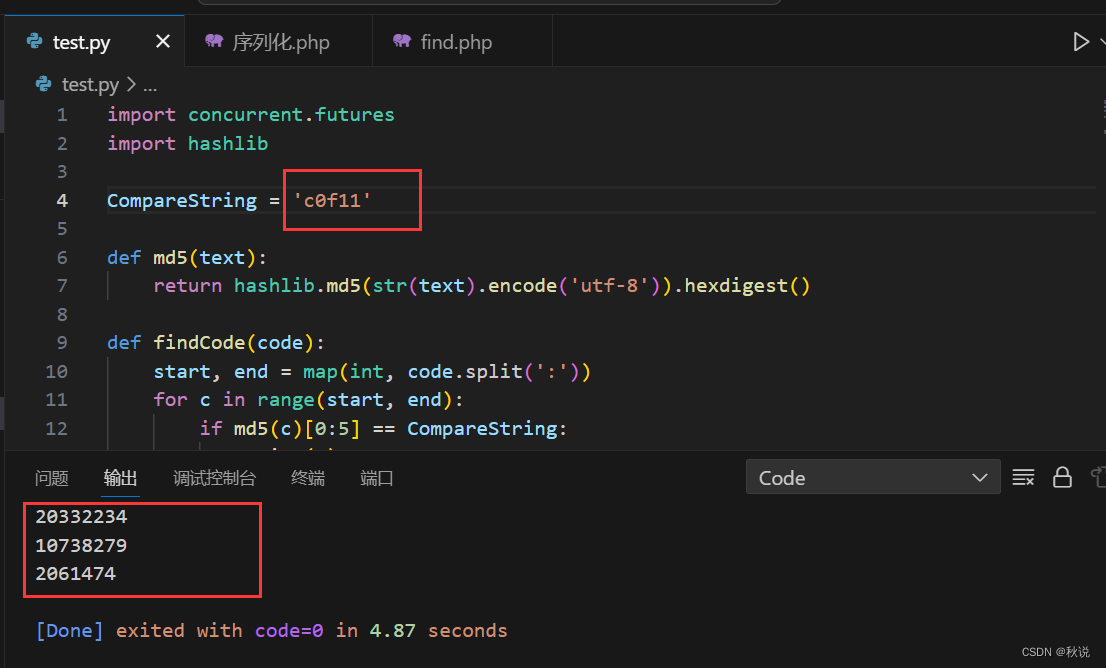
我们对以下程序做预处理:

我们输入编译指令,查看预处理之后生成的.i文件
输入指令gcc -E file.c -o file.i -Dversion1=1(与在文件内部#define version1 1作用相同)
(-E指令表示进行程序翻译在预处理完成后停下来)
(-o指令表示命名,上面指令表示把经过预处理后的文件命名为file.I)
(-D能够实现对程序进行动态裁剪,假如我们的version1,version2,version3分别表示程序的不同版本,那么通过条件编译就能控制程序不同版本的发布)
我们截取file.i的一部分
 我们可以看到,以上几个步骤实际发生了,这里需要提及一下头文件包含,实际上头文件包含就是把头文件里面的内容拷贝到了我们的文件里。
我们可以看到,以上几个步骤实际发生了,这里需要提及一下头文件包含,实际上头文件包含就是把头文件里面的内容拷贝到了我们的文件里。
⭐️编译
编译的过程就是对预处理后文件进行一系列的处理(词法分析,语法分析,语义分析,符号汇总以及优化过程)最后产生汇编代码的过程。
我们对一个最简单的表达式做以上处理:
int A=7+9;
词法分析简单来说就是记录符号的过程。
| 记号 | 类型 |
|---|---|
| A | 标识符 |
| 7 | 数字 |
| 9 | 数字 |
语法分析是生成语法树的过程。

语义分析就是对表达式做语义分析判断它是否有意义,语义又分为静态和动态语义,静态语义通常是声明和类型转换,动态语义指在程序运行出现的语义问题,例如除零错误。
语义分析后的语法树
 我们在命令行输入
我们在命令行输入
gcc -S file.i -o file.s
(-S指令表示开始程序翻译,编译步骤结束后停下来)
以下就是编译后的汇编代码
(注:我们不需要懂汇编代码,现在我们只需要知道有转汇编这个步骤)

⭐️汇编
汇编就是将汇编代码变成机器可以执行的指令的过程,最后输出一个目标文件(可重定位二进制文件),汇编有一个重要的步骤——形成符号表这个需要我们注意。
在命令行输入
gcc -c file.s -o file.o
(-c指令表示开始程序翻译,汇编步骤结束后停下来)
打开.o文件
 里面大部分都是乱码,但是我们可以看到ELF和.data这些符号,对。这个很重要。
里面大部分都是乱码,但是我们可以看到ELF和.data这些符号,对。这个很重要。
我们可以使用od指令打开它,但是并没有一点用,二进制我又看不懂。

与其说它是一个二进制文件,但实际上他是一个ELF文件。它有重要的段表和符号表,就是基于这个文件才能进行后续的链接步骤。ELF文件类型很多(例如动态库文件,可执行文件,可重定位二进制文件都是ELF文件)。
我们可以使用readelf工具读取ELF文件
命令行输入readelf -a file.o可以详细的查看ELF文件,包括ELF文件头,段表,符号表等等
文件头
 段表
段表
包含段的信息,有address(段虚拟地址),offset(段偏移),flags(段标志)等等等一系列信息。
 符号表
符号表
 细心的小伙伴可能发现符号表里面怎么有puts符号,懵逼了吧,其实这里是gcc搞的鬼,他把只打印一个字符串的printf自作聪明的换成了puts.
细心的小伙伴可能发现符号表里面怎么有puts符号,懵逼了吧,其实这里是gcc搞的鬼,他把只打印一个字符串的printf自作聪明的换成了puts.
num:符号表数组下标
value:符号值
size:符号大小
type:符号类型
bind:绑定信息
ndx:在语言中是否使用
name:符号名
⭐️链接
链接是重新翻译的最后一步,链接后就生成可执行程序。
链接步骤中至关重要的就是段表的合并符号表的合并与重定位工作
关于符号表
通过上面的学习我们知道在编译过程中有对符号的汇总,汇编步骤形成符号表,最后链接对符号表进行合并与重定位,他是怎么实现的。
我们有以下程序:

 我们就拿Add符号举一个例子。
我们就拿Add符号举一个例子。
在编译时两个文件都对符号进行汇总,两个文件都有一个相同符号Add
在汇编阶段形成符号表,对于Add.c文件形成的符号表会给Add符号一个实际地址,对于test.c文件形成的符号表编译器并不知道它的目标地址会把他的目标地址置为0.
最后链接器将他们链接起来的时候会将地址修正,也就是重定位。
分别查看三个文件的符号表


最后的可执行程序的符号表就不再展示,链接会链接库,最后的符号表有库文件的符号,使得可执行符号表很长,有兴趣的小伙伴可自行查看。
关于段表
我们可以使用objdump工具查看段
命令行输入objdump -h test.o
 其中size表示段长,file off表示段的位置
其中size表示段长,file off表示段的位置
这里介绍一下常见且易于理解的段
.text段(代码段):存放编译后的机器指令
.data段(数据段):初始化的全局变量以及静态局部变量(如果初始化为0则将其放在.bss段)
.bss段:未初始化的全局变量以及静态局部变量
.rodata(只读数据段):只读变量,例如const变量,以及字符串常量
.rel.text:重定位表,存储的重定位信息。
命令行输入objdump -x -s -d test.o
(-s表示把段内容以十六进制打印出来,-x表示反汇编)
 我们看.data和.rodata段
我们看.data和.rodata段
.data前四个从低到高是0x0a 0x00 0x00 0x00表示的就是global_init_var
同理后四个字节是static_var
.rodata的256400既是表示字符串常量%d
命令行输入objdump -r test.o可查看重定位表
以下是代码段重定位表
offset表示重定位入口的偏移。

💫动态链接与静态链接
⭐️ 动态库与静态库
| 动态库 | 静态库 | |
|---|---|---|
| Windows | .dll | .lib |
| Linux | .so | .a |
动态库用于动态链接,静态库用于静态链接
动静态库的本质其实是目标文件的集合。
在Linux中链接默认进行动态链接。
file查看文件类型,ldd查看库依赖

 框出的部分是C运行库
框出的部分是C运行库
⭐️ 静态链接
静态链接就是把我们的.o文件和使用到库中的文件链接形成可执行程序的过程,在我们使用某个库的时候,可能我们所使用到的这个库可能也依赖其他库,那么对他也需要链接,但是这个琐碎的步骤是由链接器完成的。
对于静态链接你可以把它理解成拷贝其他文件代码的过程,需要哪里就拷贝哪里,最后形成的可执行程序不再依赖其他库就能运行。
⭐️ 动态链接
动态链接的基本思想是把程序按照模块拆分成各个相对独立的部分,在运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行程序。
动态链接形成的可执行程序每次运行都需要链接,重定位是不是很慢,确实,它相较于静态链接形成的可执行程序会慢,但是它有自己的解决方法即是延迟绑定,延迟绑定的基本思想就是:当函数第一次使用到的时候才会进行绑定,对于未使用到函数不会进行绑定。
⭐️ 对比
动态链接节省资源但依赖库
静态链接浪费资源但不再依赖库
我们对一个相同的程序分别采用两种链接方式生成一个可执行程序看一看。
 file1和file2分别是动态链接和静态链接形成的可执行程序,我们通过上表可以明显看出他们在体积上的差别。
file1和file2分别是动态链接和静态链接形成的可执行程序,我们通过上表可以明显看出他们在体积上的差别。
对于静态库的安装
sudo yum install -y glibc-static
sudo yum install -y libstdc+±static



![[JS设计模式]Prototype Pattern](https://img-blog.csdnimg.cn/direct/e155de189cd04abf83712ce31c10236a.png)