1、图像分割任务概述
1.1 图像分割
分割任务就是在原始图像中逐像素的找到你需要的轮廓

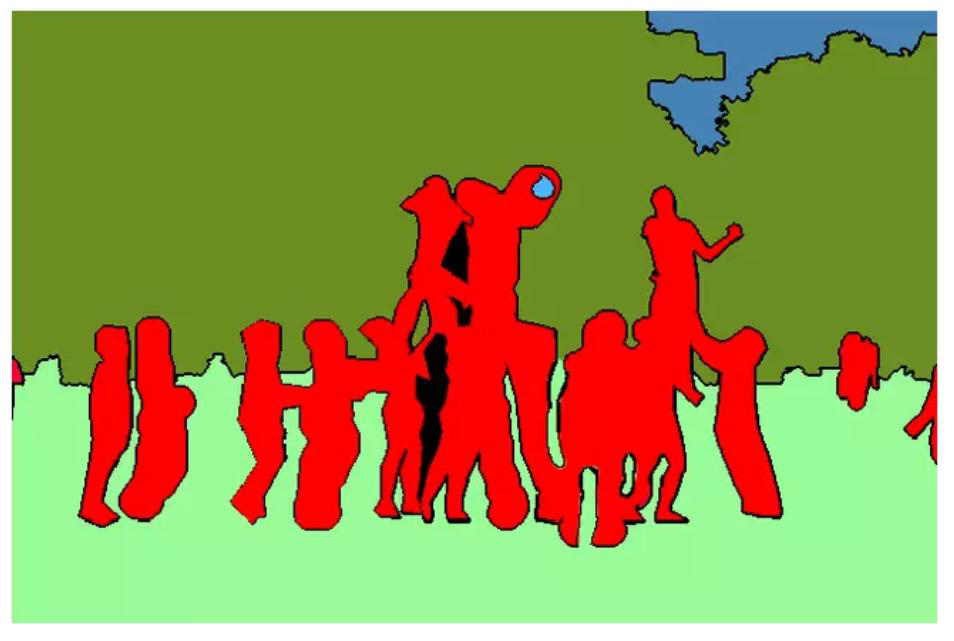
1.2 语义分割
- 语义分割就是把每个像素都打上标签(这个像素点是人,树,背景等)
- 语义分割只区分类别,不区分类别中具体单位

1.3 实例分割
在右图中将五个人的轮廓都描绘出来了,但是没有把5个人区分出来,这就是一个基本的语义分割


往基本的要求做,就是可以做语义分割,往高级的做就是实例分割
和物体检测的任务对比呢,比如YOLO是将分类任务变成回归,找一些坐标点分别是什么。那分割任务呢?
2 语义分割损失函数解析
2.1 损失函数
- 逐像素的交叉熵
- 还经常需要考虑样本均衡问题
- 交叉熵损失函数公式如下:
p
o
s
w
e
i
g
h
t
=
n
u
m
n
e
g
n
u
m
p
o
s
pos_{weight} = \frac{num_{neg}}{num_{pos}}
posweight=numposnumneg
这里的
p
o
s
w
e
i
g
h
t
pos_{weight}
posweight是一个额外权重,是前景像素点和背景像素点的数量的比例值。
l
o
s
s
=
−
p
o
s
w
e
i
g
h
t
∗
y
t
r
u
e
l
o
g
(
y
p
r
e
d
)
−
(
1
−
y
t
r
u
e
)
l
o
g
(
y
p
r
e
d
)
loss = -pos_{weight}*y_{true}log(y_{pred})-(1-y_{true})log(y_{pred})
loss=−posweight∗ytruelog(ypred)−(1−ytrue)log(ypred)
首先一张图像有几万几十万甚至更多个像素点,需要对每一个像素点都进行多分类任务,也就是逐像素进行交叉熵的过程。上式就是一个2分类交叉熵的公式再加上前面提到的额外权重
2.2 Focal loss
样本也由难易之分,就跟玩游戏一样,难度越高的BOSS奖励越高
−
(
1
−
y
p
r
e
d
)
γ
∗
y
t
r
u
e
l
o
g
(
y
p
r
e
d
)
−
y
p
r
e
d
γ
∗
(
1
−
y
t
r
u
e
l
o
g
(
1
−
y
p
r
e
d
)
)
-(1-y_{pred})^γ*y_{true}log(y_{pred})-y^γ_{pred}*(1-y_{true}log(1-y_{pred}))
−(1−ypred)γ∗ytruelog(ypred)−ypredγ∗(1−ytruelog(1−ypred))
正负样本的比例完全就是由数量决定的,每一个像素点都会去做交叉熵,都会产生一个损失值,像素点是不应该相同对待的,有些像素比较好处理,很明显是背景和前景的,难处理的就是轮廓上的,一个人去描边,边里面的好处理外面的也好处理,但是边上的不好处理。但是这些难处理的像素点应该要体现出比较高的重要性
在上面的公式中,Gamma通常设置为2,例如预测正样本概率0.95,那预测效果就非常好,也就是说这个像素处理的比较简单, ( 1 − 0.25 ) 2 = 0.0025 (1-0.25)^2=0.0025 (1−0.25)2=0.0025,0.0025也就意味着当前这个样本提供的损失值比较低,如果是0.5, ( 1 − 0.5 ) 2 = 0.25 (1-0.5)^2=0.25 (1−0.5)2=0.25,这个难度高一点,权重也就大一些。可以类似理解为错题本,想要学的更好得高分,错的题比较重要。这里就是对γ值的解释
再结合样本数量的权值就是Focal Loss:
−
α
(
1
−
y
p
r
e
d
)
γ
∗
y
t
r
u
e
l
o
g
(
y
p
r
e
d
)
−
(
1
−
α
)
∗
y
p
r
e
d
γ
∗
(
1
−
y
t
r
u
e
l
o
g
(
1
−
y
p
r
e
d
)
)
-α(1-y_{pred})^γ*y_{true}log(y_{pred})-(1-α)*y^γ_{pred}*(1-y_{true}log(1-y_{pred}))
−α(1−ypred)γ∗ytruelog(ypred)−(1−α)∗ypredγ∗(1−ytruelog(1−ypred))
3 IOU计算
3.1 IOU计算
多分类任务时:iou_dog = 801 /( true_dog + predict_dog - 801)

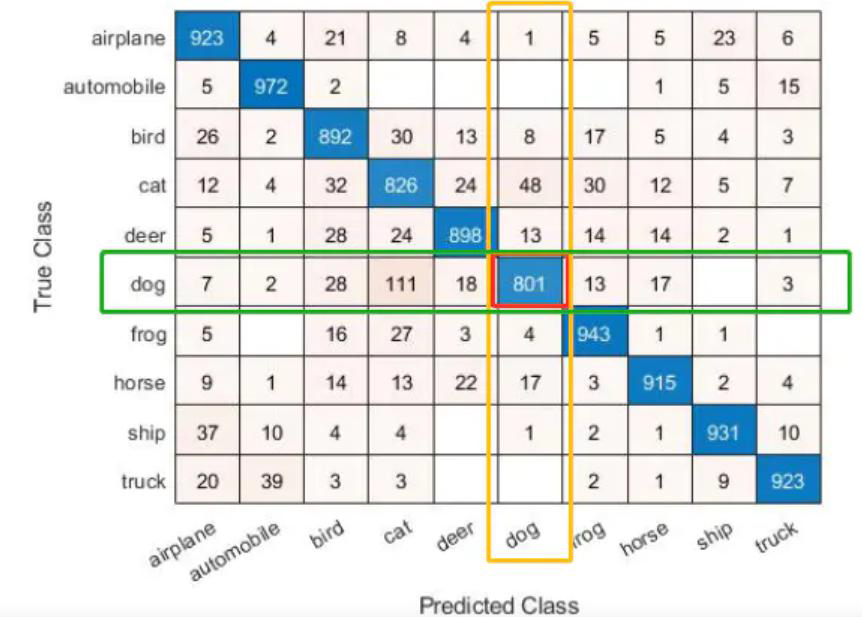
如图的混淆矩阵,左图中,横轴和纵轴分别为预测值和真实值,单独求某一个类别:真实值为狗的预测值也为狗就是做对的,为801个除以(实际总共有多少个狗的,再加上预测为狗的,再减去801)
看右图,交集就是801,并集就是绿色加上黄色的,上面的公式就是由于加了两次801所以要减去801
3.2 MIOU计算
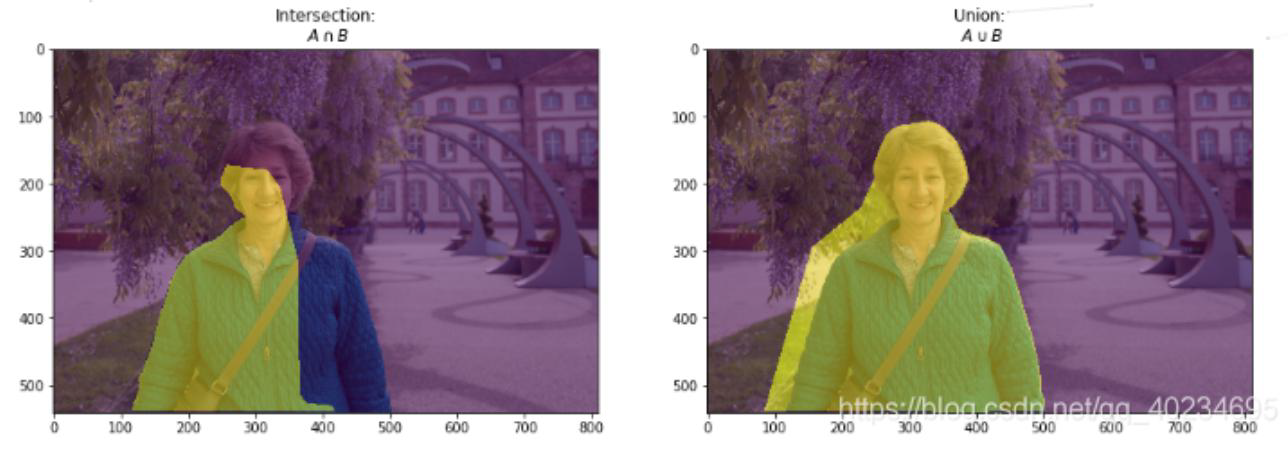
IoU(Intersection over Union,交并比),下图中,左边是标签值,右边是预测值
Intersection 就是真实值和预测值的交集,Union就是真实值和预测值的并集,这两个值的比例
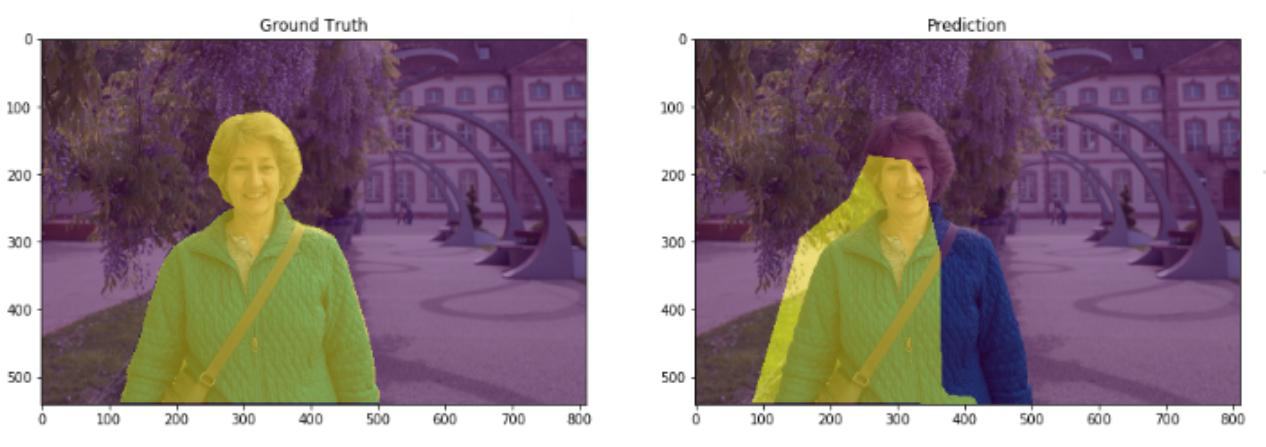
MIOU就是计算所有类别的平均值,一般当作分割任务评估指标