目录
给你一个字符串数组,删除他们之间相同的元素,(保留一个重复值)
【方法一】使用迭代器进行区间删除
【方法二】原地删除
【方法三】使用计数跳过
1002. 查找共用字符
【解法一】我的第一个理解题意出错的解法
【解法二】初步使用哈希思想
【解法三】使用Hash
给你一个字符串数组,删除他们之间相同的元素,(保留一个重复值)
首先都进行sort排序(字符串也能进行排序!!!)
排序规则与strcmp比较函数类似
【方法一】使用迭代器进行区间删除
iterator erase (iterator first, iterator last);
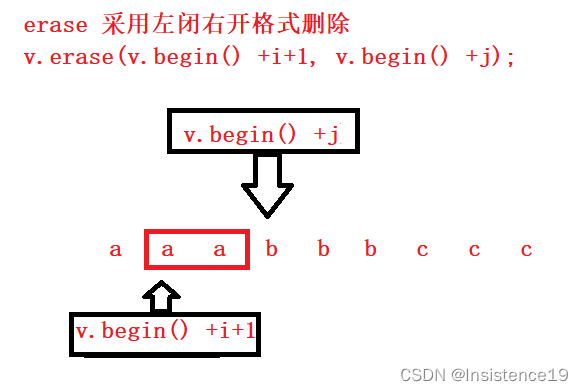
这里可以进行控制是否要保留这一个重复的元素,分辨出题目要求是否保留重复元素
下方代码就是进行对第一个重复值的保留
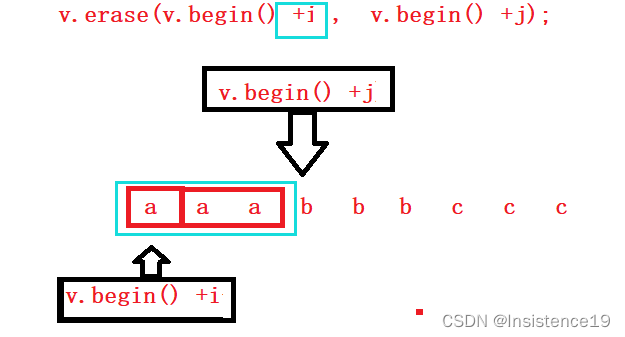
如果不想对第一个进行保留,即题目要求删除所以重复出现元素,那么在erase操作将i+1中+1去掉即可
vector<string> delete_repeat(vector<string> v)
{
sort(v.begin(), v.end());
for (int i = 0; i < v.size(); ++i)
{
string temp = v[i];
int j = i;
while (j < v.size() && temp == v[j])
{
j++;
}
v.erase(v.begin() + i + 1, v.begin() + j);
}
return v;
}【方法二】原地删除
注意erase删除后下标i仍然不动,所以不需要对i下标进行++操作
vector<string> delete_repeat(vector<string> v)
{
sort(v.begin(), v.end());
for(size_t i = 0; i < v.size();)
{
auto temp = v[i];
if(v[i+1] == temp)
{
while(i<v.size() && v[i]==temp)
{
auto it = v.begin()+i;
v.erase(it);
}
}
else
++i;
}
return v;
}【方法三】使用计数跳过
string compressString(string s) {
string res;
for(size_t i = 0; i < s.size();)
{
res+=s[i];
int count = 0;
if(i!=s.size()-1 && s[i+1]==s[i])
{
char ch = s[i];
int j = i;
while(ch == s[j])
{
count++;
j++;
}
res+=_to_string(count);
i += count;
}
else
{
res+=_to_string(1);
i++;
}
}1002. 查找共用字符
1002. 查找共用字符![]() https://leetcode.cn/problems/find-common-characters/
https://leetcode.cn/problems/find-common-characters/
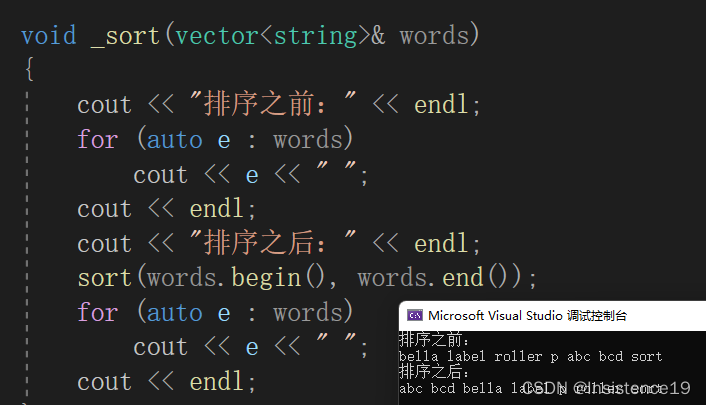
给你一个字符串数组 words ,请你找出所有在 words 的每个字符串中都出现的共用字符( 包括重复字符),并以数组形式返回。你可以按 任意顺序 返回答案。
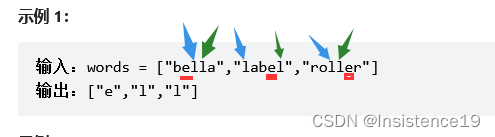
示例 1:
输入:words = ["bella","label","roller"]
输出:["e","l","l"]
示例 2:
输入:words = ["cool","lock","cook"]
输出:["c","o"]
提示:
1 <= words.length <= 100
1 <= words[i].length <= 100
words[i] 由小写英文字母组成
【解法一】我的第一个理解题意出错的解法
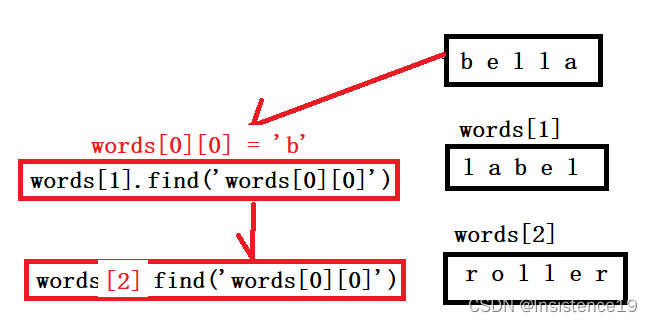
第一次没有注意题目意思,将每个单词中重复出现多次的单词直接当成一次进行输出
仅仅完成了蓝色 ‘l’的输出,将绿色的‘l’没有进行输出。
采用的思想是 首先初始化res,利用第一个单词中的每一个元素来进行其余单词的find查找
然后对res进行去重操作。
class Solution {
public:
vector<string> delete_repeat(vector<string> v)
{
sort(v.begin(), v.end());
for(int i = 0; i < v.size(); ++i)
{
string temp = v[i];
int j = i;
while(j < v.size() && temp == v[j])
{
j++;
}
v.erase(v.begin()+i+1, v.begin()+j);
}
return v;
}
vector<string> commonChars(vector<string>& words) {
vector<string> res;
for(int i = 0; i < words[0].size(); ++i)
{
char ch = words[0][i];
int flag = 1;
for(int j = 1; j < words.size(); ++j)
{
size_t pos = words[j].find(ch);
if(pos==-1)
{
flag = 0;
break;
}
}
if(flag)
res.push_back(string(1, ch));
}
return delete_repeat(res);
}
};【解法二】初步使用哈希思想
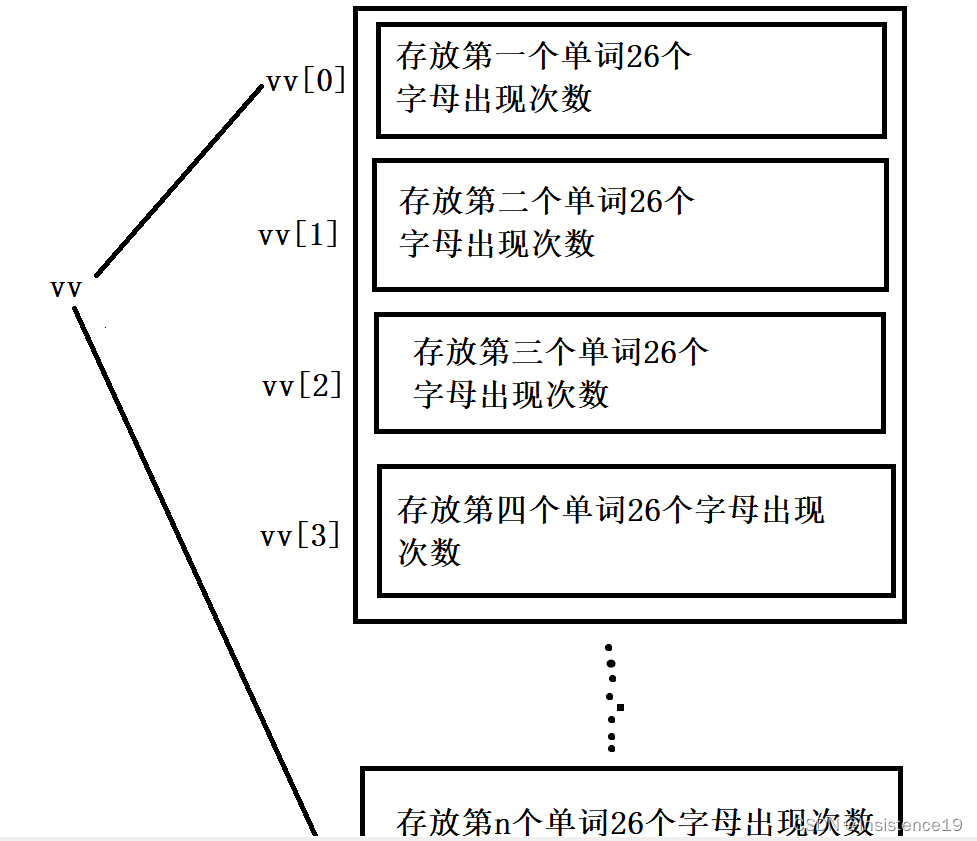
初始化一个vv数组进行对每个单词的的每个字符进行遍历,将单词字符出现次数进行统计
然后 分别每个字母在对应vv【字母下标】数组中值最小的次数,也就是公共出现次数
把这个字母往返回数组中存放入对应最小次数,如果没有出现那么就不存这个字母了。
class Solution {
public:
vector<string> commonChars(vector<string>& words) {
vector<string> res;
vector<vector<int>> vv(words.size(), vector<int>(26, 0));
for(int i = 0; i < words.size(); ++i)
{
for(int j = 0; j < words[i].size(); ++j)
{
vv[i][words[i][j]-'a']++;
}
}
for(int i = 0; i < 26; ++i)
{
int minsize = vv[0][i];
for (int j = 1; j < vv.size(); ++j)
{
minsize = min(vv[j][i], minsize);
}
if(minsize > 0)
{
for(int k = 0; k < minsize; k++)
{
char ch = 'a'+i;
string s(1, ch);
res.push_back(s);
}
}
}
return res;
}
};【解法三】使用Hash
其实我的解法二就是采用了hash映射的思想解法三就是与我的解法存在着相同的思想
① 用第一个单词初始化Hash【26】数组,Hash存放第一个单词每个字母出现次数
② 对剩余其他单词进行哈希映射
③ 定义一个otherHash数组(注意它的位置,应该是遍历每个单词之前进行初始化,我刚开始
与hash一起初始化导致错误)
④ 将每个单词出现次数映射到该otherHash数组中
⑤ 接着 对之前的Hash数组与otherHash数组进行更新处理,使Hash数组始终存放当前每个字
母出现的最小次数(即为公共次数)
⑥ 对Hash进行遍历 将公共出现次数大于0的元素进行多次插入到返回数组中
class Solution {
public:
vector<string> commonChars(vector<string>& words) {
int hash[26] = {0};
for(int i = 0; i < words[0].size(); ++i)
{
hash[words[0][i]-'a']++;
}
for(int i = 1; i < words.size(); ++i)
{
int otherhash[26] = {0};
for(int j = 0; j < words[i].size(); ++j)
{
otherhash[words[i][j]-'a']++;
}
for(int k = 0; k < 26; k++)
{
hash[k] = min(hash[k], otherhash[k]);
}
}
vector<string> res;
for(int i = 0; i < 26; i++)
{
if(hash[i]>0)
{
for(int j = 0; j < hash[i]; ++j)
{
char ch = 'a'+i;
res.push_back(string(1, ch));
}
}
}
return res;
}
};