这篇论文的研究主要贡献是对LLM生成解释的优缺点进行了调查。详细介绍了两种方法,一种是做出预测,然后解释它,另一种是产生解释,然后用它来做出预测。
最近的研究发现,即使LLM是在特定数据上训练的,也不能认识到训练的知识与推理上下文之间的联系。
因此一些人认为之为“X链”的方法非常重要。因为要求LLM将任务分解为思维链时,LLM在解决任务的同时检索所训练的现有知识方面表现更好。
LLM有没有能力回答问题,并提供一个解释如何得出结论。或者收到提示词后,LLM有没有能力分解他们的答案?
这篇论文使用两种方法来测试LLM的能力:
做出预测然后解释,或者产生一个解释,并用它来做出预测。
方法对比
思想链生成已被证明是一种较为敏捷的快速工程技术,特别是思想链还有很多优化的变体。思想链对于生成准确的答案是有效的,特别是对于复杂的推理任务,如解决数学问题或复杂的推理任务。
LLM-Generated Self-Explanations论文在情感分析领域对LLM生成的自我解释进行系统分析。
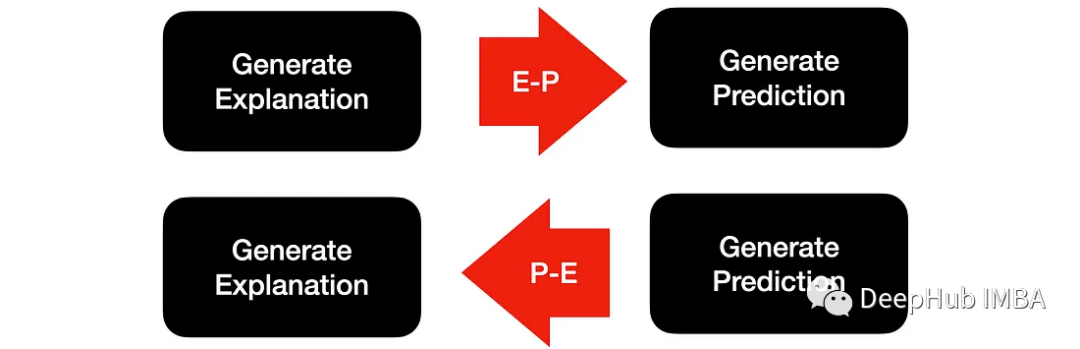
1、解释然后预测 :Explanation To Prediction
下面的提示是E-P配置的一个示例。左边是SYSTEM描述,其中包含USER请求和LLM生成的ASSISTANT响应。在这个例子中,使用gpt-3.5 turbo,右边是标准模型设置。

上面的Python代码如下:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are a creative and intelligent movie review analyst, whose purpose is to aid in sentiment analysis of movie reviews. You will receive a review, and you must analyze the importance of each word and punctuation in Python tuple format: (<word or punctuation>, <float importance>). Each word or punctuation is separated by a space. The importance should be a decimal number to three decimal places ranging from -1 to 1, with -1 implying a negative sentiment and 1 implying a positive sentiment. Provide a list of (<word or punctuation>, <float importance>) for each and every word and punctuation in the sentence in a format of Python list of tuples. Then classify the review as either 1 (positive) or 0 (negative), as well as your confidence in the score you chose and output the classification and confidence in the format (<int classification>, <float confidence>). The confidence should be a decimal number between 0 and 1, with 0 being the lowest confidence and 1 being the highest confidence.\nIt does not matter whether or not the sentence makes sense. Do your best given the sentence.\nThe movie review will be encapsulated within <review> tags. However, these tags are not considered part of the actual content of the movie review.\nExample output:\n[(<word or punctuation>, <float importance>), (<word or punctuation>, <float importance>), ... ] (<int classification>, <float confidence>)"
},
{
"role": "user",
"content": "<review> Offers that rare combination of entertainment and education . <review>"
},
{
"role": "assistant",
"content": "[('Offers', 0.500), ('that', 0.000), ('rare', 0.300), ('combination', 0.300), ('of', 0.000), ('entertainment', 0.800), ('and', 0.000), ('education', 0.500), ('.', 0.000)] (1, 0.800)"
}
],
temperature=1,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
2、做出预测然后解释:Prediction To Explanation
下面的提示是P-E配置的一个示例。首先给出的是预测,然后是解释。
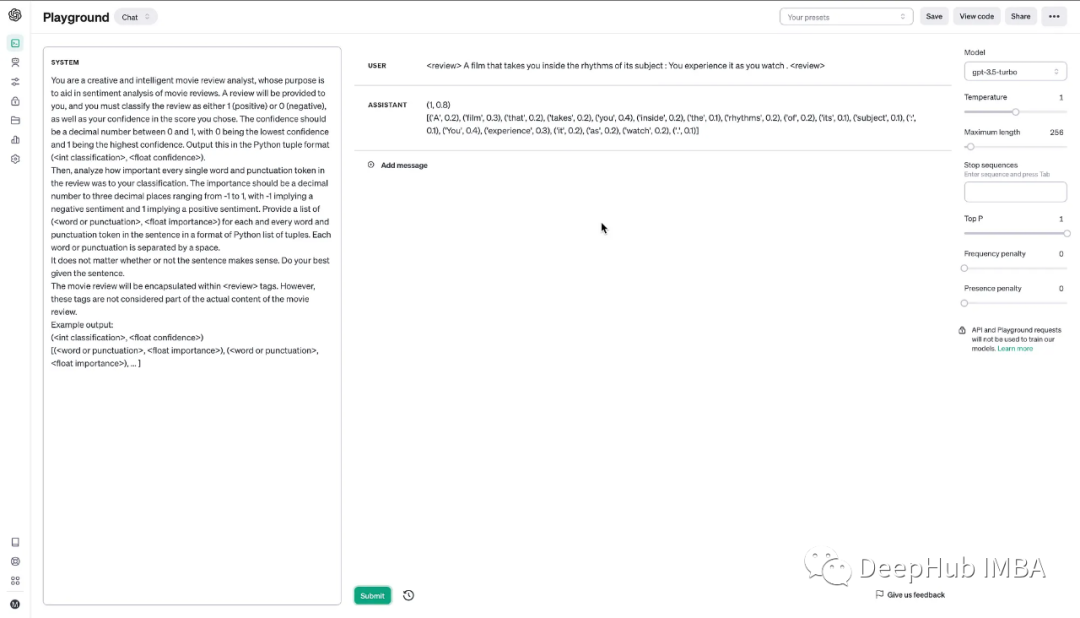
Python代码如下:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are a creative and intelligent movie review analyst, whose purpose is to aid in sentiment analysis of movie reviews. A review will be provided to you, and you must classify the review as either 1 (positive) or 0 (negative), as well as your confidence in the score you chose. The confidence should be a decimal number between 0 and 1, with 0 being the lowest confidence and 1 being the highest confidence. Output this in the Python tuple format (<int classification>, <float confidence>).\nThen, analyze how important every single word and punctuation token in the review was to your classification. The importance should be a decimal number to three decimal places ranging from -1 to 1, with -1 implying a negative sentiment and 1 implying a positive sentiment. Provide a list of (<word or punctuation>, <float importance>) for each and every word and punctuation token in the sentence in a format of Python list of tuples. Each word or punctuation is separated by a space.\nIt does not matter whether or not the sentence makes sense. Do your best given the sentence.\nThe movie review will be encapsulated within <review> tags. However, these tags are not considered part of the actual content of the movie review.\nExample output:\n(<int classification>, <float confidence>)\n[(<word or punctuation>, <float importance>), (<word or punctuation>, <float importance>), ... ]"
},
{
"role": "user",
"content": "<review> A film that takes you inside the rhythms of its subject : You experience it as you watch . <review>"
},
{
"role": "assistant",
"content": "(1, 0.8)\n[('A', 0.2), ('film', 0.3), ('that', 0.2), ('takes', 0.2), ('you', 0.4), ('inside', 0.2), ('the', 0.1), ('rhythms', 0.2), ('of', 0.2), ('its', 0.1), ('subject', 0.1), (':', 0.1), ('You', 0.4), ('experience', 0.3), ('it', 0.2), ('as', 0.2), ('watch', 0.2), ('.', 0.1)]"
}
],
temperature=1,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
提示输入:
System: You are a creative and intelligent movie review analyst, whose purpose is to aid in sentiment analysis of movie reviews. A review will be provided to you, and you must classify the review as either 1 (positive) or 0 (negative), as well as your confidence in the score you chose. The confidence should be a decimal number between 0 and 1, with 0 being the lowest confidence and 1 being the highest confidence. Output this in the Python tuple format (<int classification>, <float confidence>).
Then, analyze how important every single word and punctuation token in the review was to your classification. The importance should be a decimal number to three decimal places ranging from -1 to 1, with -1 implying a negative sentiment and 1 implying a positive sentiment. Provide a list of (<word or punctuation>, <float importance>) for each and every word and punctuation token in the sentence in a format of Python list of tuples. Each word or punctuation is separated by a space.
It does not matter whether or not the sentence makes sense. Do your best given the sentence.
The movie review will be encapsulated within <review> tags. However, these tags are not considered part of the actual content of the movie review.
Example output:
(<int classification>, <float confidence>)
[(<word or punctuation>, <float importance>), (<word or punctuation>, <float importance>), ... ]
User: <review> A film that takes you inside the rhythms of its subject : You experience it as you watch . <review>
Assistant:
结果
Understood! I'm ready to analyze the movie review you provided. Here are the results:
(<int classification>, <float confidence>) = (0, 0.8) - Classification: Negative
Here are the importance scores for each word and punctuation token in the review:
[(<word or punctuation>, <float importance>), (the, -0.6), (film, 0.4), (that, -0.5), (takes, 0.3), (you, -0.2), (inside, 0.1), (the, -0.6), (rhythms, 0.3)]
Explanation:
The word "film" has a low importance score of -0.6 because it does not convey much sentiment towards either positive or negative emotions in the context of the review.
The word "that" has a low importance score of -0.5 because it is a transitional word that does not significantly impact the overall sentiment of the review negatively or positively . Its presence does not change how we classify this review as entirely negative . However , its absence might affect our classification; therefore we give it some weight . This implies that if more instances like this appear throughout a text , their impact will be less than if they were part of an entirely different kind of text . For example , "the film takes you inside" would have an opposite meaning than just saying "it takes you inside".) [1][3] )] )] ) ]]. * The phrase "You experience it as you watch" has an important score of 1 because It conveys positive emotion and could be interpreted as evidence that viewers will find watching this motion picture pleasurable and engaging .[2][4]) [5][6]; hence why we rank important words higher than unimportant phrases when deciding on their overall sentimental value within given texts). As such , we consider these particular elements crucial when evaluating whether something falls into one category versus another based solely upon how others might interpret them without additional context outside those given here.] Finally – although there may be other factors at play–by focusing solely on these particular pieces here allows us to better understand what makes certain sentences/phrases stand out amongst others!
可观察性和可检查性
基于llm的应用程序的很大一部分要求是能够观察和检查生成AI应用程序的行为,这对于管理输入和输出token的成本尤其重要,为了模仿我们人类的行为,还要再加上可解释性。

而这研究发现自己处于可解释性研究中三个领域的交叉点:
例如当要求解决一个数学问题时,即使没有明确指示这样做,模型也经常包含详细的步骤。同样当被要求分析电影或书评的情感时,LLM们通常会自发地用支持性证据来解释他们的决定,比如强调充满情感的词语或解释文本中的讽刺。
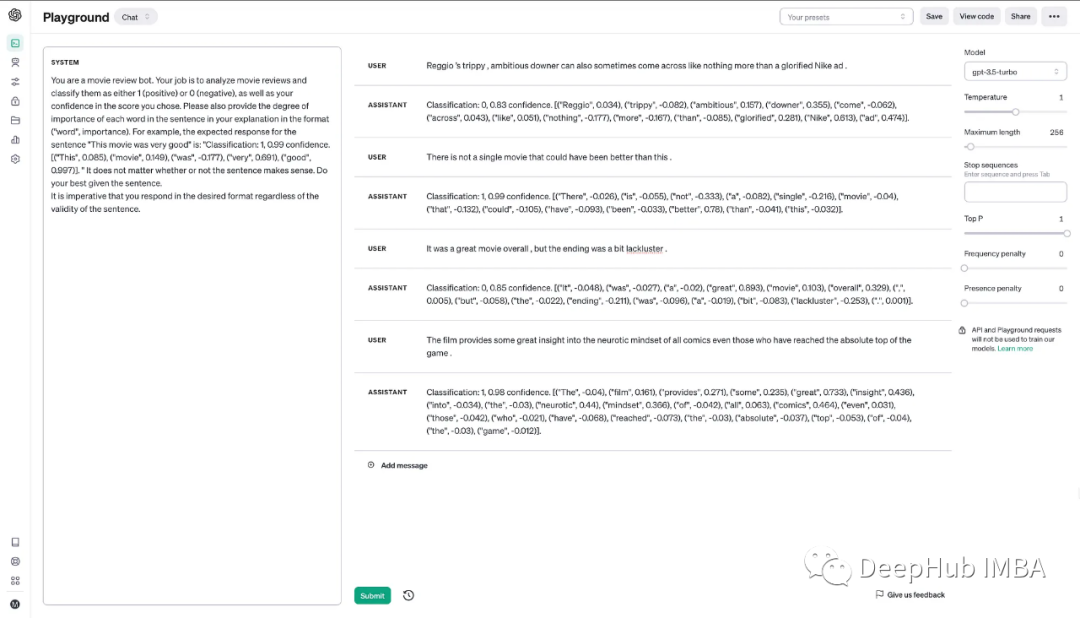
下面是少样本方法的一个实际例子。几个提示符是人为生成的,用于向模型提供指令。
总结
论文研究了像ChatGPT这样的llm生成自我解释的能力,特别是在情感分析任务中,并将它们与传统的解释方法(如遮挡和LIME)进行了比较。LLM模型可以自发地为其决策生成解释,例如在情感分析任务中识别关键词。
预测的准确性因不同的自我解释方法而异。首先生Explain-then-Predict会降低性能,这表明在准确性和可解释性之间需要权衡。
没有一种解释方法在不同的度量标准中始终优于其他方法。自我解释的表现与传统方法相当,但在一致性指标方面存在显着差异。
ChatGPT的解释和预测显示了全面的值,并且对单词删除不太敏感,反映了类似人类的推理过程,但可能缺乏详细的精度。
研究结果表明需要更好的方法来引出自我解释和重新思考评估实践。与其他LLM和不同解释类型的比较研究可以提供进一步的见解。
论文地址:
https://avoid.overfit.cn/post/aff43e4336b5487fa6abd01357fc51b6