爬了两天大大小小的一堆坑,今天把一个简单的单机环境的流程走通了,记录一笔。
先来个完工环境照:
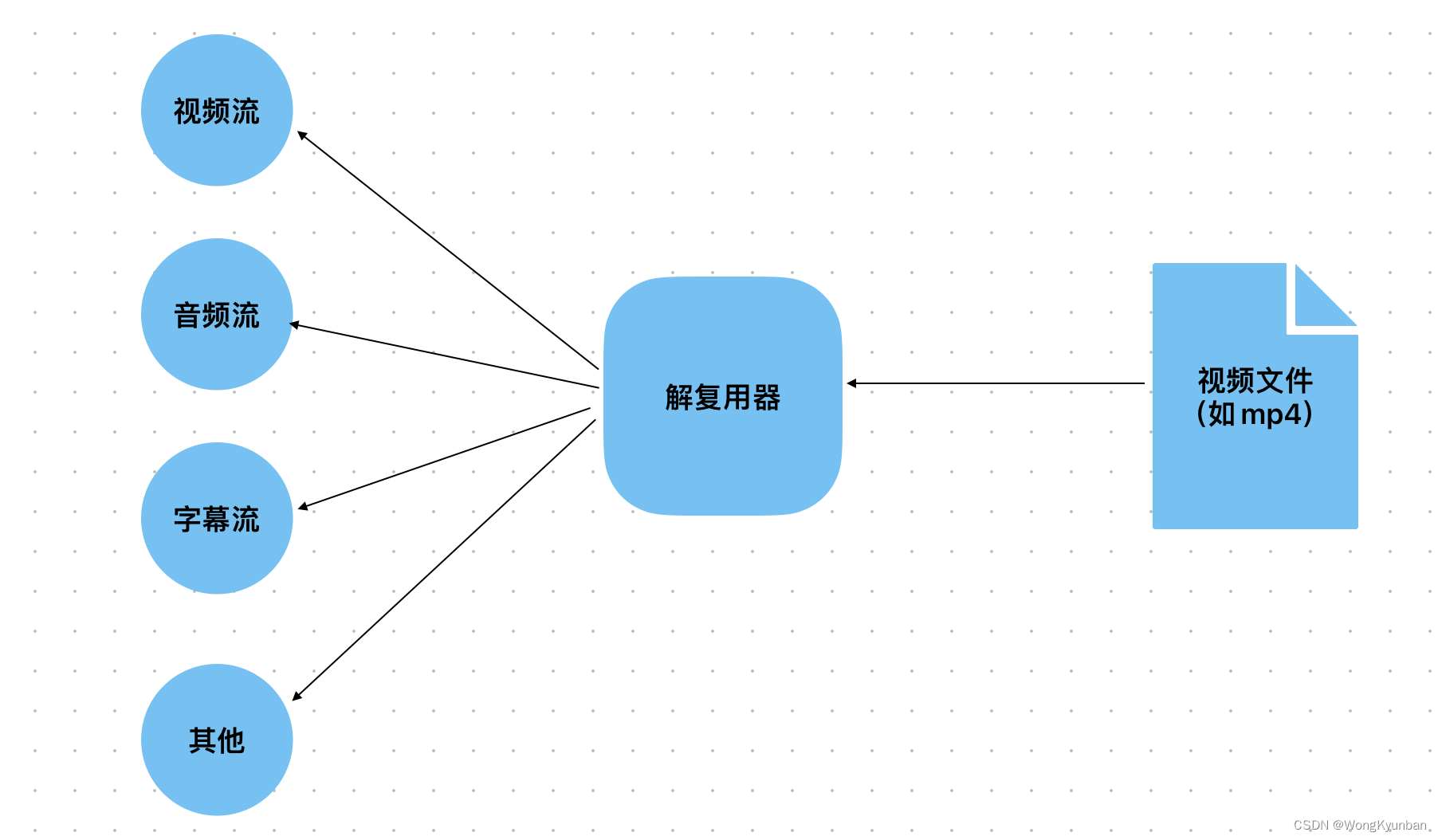
mysql+hadoop+hive+flink+iceberg+trino
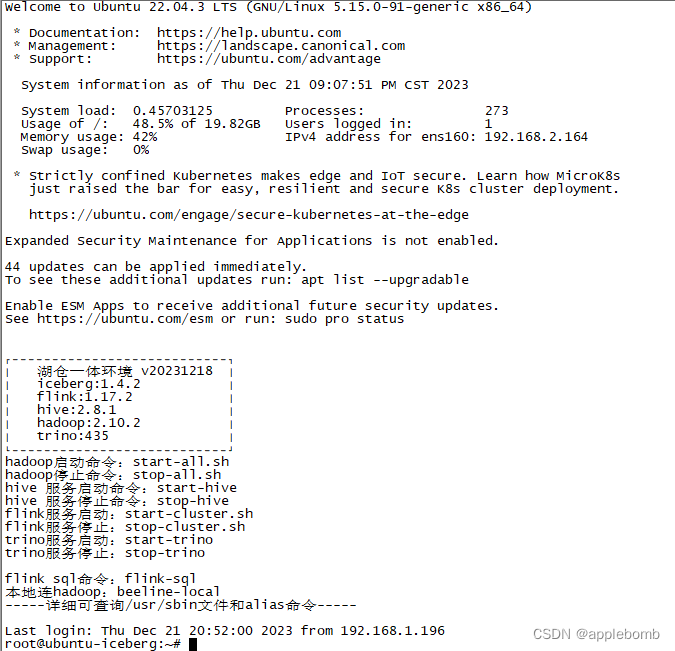
得益于IBM OPENJ9的优化,完全启动后的内存占用:
1)执行联合查询后的
2)其中trino由于必须使用ORACLE或OPENJDK,只能再安装多一个JDK21的环境

HIVE里ICEBERG的表和数据:
-- iceberg.test.my_tbl definition
CREATE TABLE iceberg.test.my_tbl (
user_id integer,
user_name varchar,
country varchar,
birthday date
)
WITH (
format = 'PARQUET',
format_version = 2,
location = 'hdfs://localhost:9000/user/hive/warehouse/test.db/my_tbl',
partitioning = ARRAY['country']
);

MYSQL里的表和数据:
-- dict.dict.country definition
CREATE TABLE dict.dict.country (
country_name varchar(2) NOT NULL,
country_cn varchar(20) NOT NULL
);

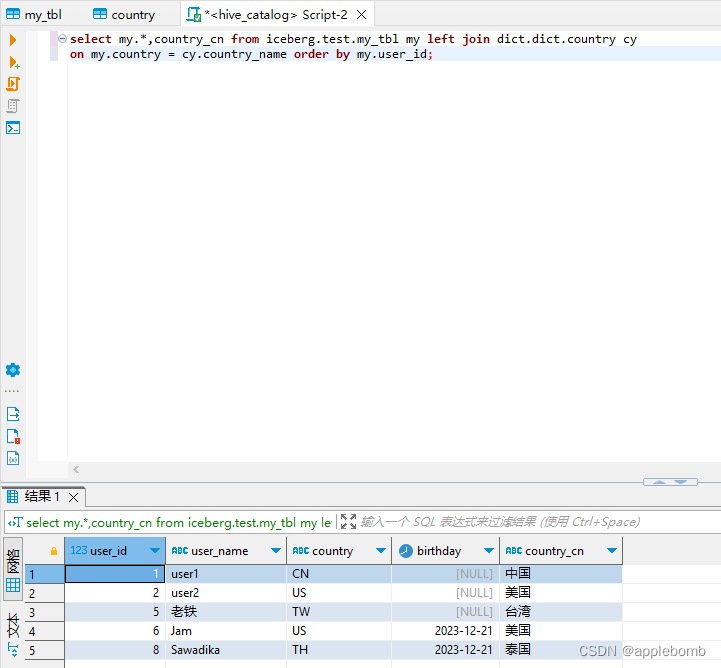
联合查询的执行结果:









![助力智能车辆检测计数,基于官方YOLOv8全系列[n/s/m/l/x]开发构建道路交通场景下不同参数量级车流检测计数系统](https://img-blog.csdnimg.cn/direct/7a03b9a4ba1a4526b4119797ac1a5f08.jpeg)
![[Unity]接入Firebase 并且关联支付埋点](https://img-blog.csdnimg.cn/direct/f61583aa46db4b9bba06a73467242933.png)