参数估计目录
- 一、点估计
- 1. 估计量的概念
- 2. 估计量的求法
- 矩估计法
- 最大似然估计法
- 二、估计量的评选标准
- 1. 无偏性
- 2. 有效性
- 3. 相合性
- 总结
- 三、区间估计
- 1. 双侧区间估计
- 2. 单侧区间估计
- 四、正态总体参数的区间估计
- σ 2 \sigma^2 σ2已知,考察 μ \mu μ</font>
- σ 2 \sigma^2 σ2未知,考察 μ \mu μ</font>
- μ \mu μ已知,考察 σ 2 \sigma^2 σ2</font>
- μ \mu μ未知,考察 σ 2 \sigma^2 σ2</font>
- σ 1 2 , σ 2 2 \sigma_1^2,\sigma_2^2 σ12,σ22已知,考察 μ 1 − μ 2 \mu_1-\mu_2 μ1−μ2</font>
- σ 1 2 = σ 2 2 \sigma_1^2=\sigma_2^2 σ12=σ22未知,考察 μ 1 − μ 2 \mu_1-\mu_2 μ1−μ2</font>
- μ 1 , μ 2 \mu_1,\mu_2 μ1,μ2已知,考察 σ 1 2 σ 2 2 \frac{\sigma_1^2}{\sigma_2^2} σ22σ12</font>
- μ 1 , μ 2 \mu_1,\mu_2 μ1,μ2未知,考察 σ 1 2 σ 2 2 \frac{\sigma_1^2}{\sigma_2^2} σ22σ12</font>
一、点估计
1. 估计量的概念
点估计:设总体
X
X
X的分布函数为
F
(
x
;
θ
1
,
θ
2
,
⋯
,
θ
l
)
F(x;\theta_1,\theta_2,\cdots,\theta_l)
F(x;θ1,θ2,⋯,θl),其中
θ
1
,
θ
2
,
⋯
,
θ
l
\theta_1,\theta_2,\cdots,\theta_l
θ1,θ2,⋯,θl是待估计的未知参数,
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
(X1,X2,⋯,Xn)是来自总体
X
X
X的样本,
(
x
1
,
x
2
,
⋯
,
x
n
)
(x_1,x_2,\cdots,x_n)
(x1,x2,⋯,xn)是相应的样本值,点估计问题就是要构造
l
l
l个适当的统计量
θ
^
i
(
X
1
,
X
2
,
⋯
,
X
n
)
(
i
=
1
,
2
,
⋯
,
l
)
\hat{\theta}_i(X_1,X_2,\cdots,X_n)\,(i=1,2,\cdots,l)
θ^i(X1,X2,⋯,Xn)(i=1,2,⋯,l),分别用观测值
θ
^
i
(
x
1
,
x
2
,
⋯
,
x
n
)
\hat{\theta}_i(x_1,x_2,\cdots,x_n)
θ^i(x1,x2,⋯,xn)作为未知参数
θ
i
\theta_i
θi的估计值。
估计量:估计用的统计量
θ
^
i
(
X
1
,
X
2
,
⋯
,
X
n
)
\hat{\theta}_i(X_1,X_2,\cdots,X_n)
θ^i(X1,X2,⋯,Xn)
估计值:估计量的观测值
θ
^
i
(
x
1
,
x
2
,
⋯
,
x
n
)
\hat{\theta}_i(x_1,x_2,\cdots,x_n)
θ^i(x1,x2,⋯,xn)
在不致混淆的情况下统称估计量和估计值为估计,并都简记为
θ
^
i
\hat{\theta}_i
θ^i。
估计量是样本的函数,是随机变量,不同的样本值得到的估计值往往是不同的。
2. 估计量的求法
矩估计法
设总体 X X X的前 l l l阶原点矩 α k = E ( X k ) ( k = 1 , 2 , ⋯ , l ) \alpha_k=E\left(X^k\right)\,(k=1,2,\cdots,l) αk=E(Xk)(k=1,2,⋯,l)存在,且都是 θ 1 , θ 2 , ⋯ , θ l \theta_1,\theta_2,\cdots,\theta_l θ1,θ2,⋯,θl的函数,即 α k = α k ( θ 1 , θ 2 , ⋯ , θ l ) \alpha_k=\alpha_k(\theta_1,\theta_2,\cdots,\theta_l) αk=αk(θ1,θ2,⋯,θl)。把总体原点矩用样本原点矩代替( α k → A k \alpha_k\to A_k αk→Ak),未知参数用其估计量代替( θ i → θ ^ i \theta_i\to\hat{\theta}_i θi→θ^i),得 { α 1 ( θ ^ 1 , θ ^ 2 , ⋯ , θ ^ l ) = A 1 α 2 ( θ ^ 1 , θ ^ 2 , ⋯ , θ ^ l ) = A 2 ⋯ α l ( θ ^ 1 , θ ^ 2 , ⋯ , θ ^ l ) = A l \begin{cases} \alpha_1\left(\hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_l\right)=A_1\\ \alpha_2\left(\hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_l\right)=A_2\\ \cdots\\ \alpha_l\left(\hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_l\right)=A_l \end{cases} ⎩ ⎨ ⎧α1(θ^1,θ^2,⋯,θ^l)=A1α2(θ^1,θ^2,⋯,θ^l)=A2⋯αl(θ^1,θ^2,⋯,θ^l)=Al解此方程组可得 θ ^ 1 , θ ^ 2 , ⋯ , θ ^ l \hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_l θ^1,θ^2,⋯,θ^l(是 A 1 , A 2 , ⋯ , A k A_1,A_2,\cdots,A_k A1,A2,⋯,Ak的函数),并将它们分别作为 θ 1 , θ 2 , ⋯ , θ l \theta_1,\theta_2,\cdots,\theta_l θ1,θ2,⋯,θl的估计量。 A 1 A_1 A1一般写作 X ‾ \overline{X} X。
矩估计法的理论依据是大数定律,当 n n n充分大时,样本矩 A k A_k Ak以很大的概率落在总体矩 α k \alpha_k αk的附近,因此可用 A k A_k Ak作为 α k \alpha_k αk的矩估计量。
例
X
~
U
(
0
,
θ
)
\newcommand{\td}{\,\text{\large\textasciitilde}\,}X\td U(0,\theta)
X~U(0,θ),求
θ
\theta
θ的矩估计量。
解:我们知道
α
1
=
E
(
X
)
=
θ
2
\alpha_1=E(X)=\frac{\theta}{2}
α1=E(X)=2θ把
α
1
\alpha_1
α1换成
A
1
A_1
A1(
X
‾
\overline{X}
X),
θ
\theta
θ换成
θ
^
\hat{\theta}
θ^得
X
‾
=
θ
^
2
\overline{X}=\frac{\hat{\theta}}{2}
X=2θ^因此
θ
\theta
θ的矩估计量为
θ
^
=
2
X
‾
\hat{\theta}=2\overline{X}
θ^=2X。
矩估计法不必知道总体的分布,优点是简单直接,但缺点是只利用了总体的局部特性而没有充分利用总体的信息。
最大似然估计法
思想:若存在某一分布,使得在此分布下抽中 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn)的概率最大,则认为 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn)来自这一分布。
似然函数:若总体
X
X
X是离散型或连续型随机变量,其分布律为
P
{
X
=
x
}
=
p
(
x
;
θ
1
,
θ
2
,
⋯
,
θ
l
)
P\{X=x\}=p(x;\theta_1,\theta_2,\cdots,\theta_l)
P{X=x}=p(x;θ1,θ2,⋯,θl),或其概率密度为
f
(
x
;
θ
1
,
θ
2
,
⋯
,
θ
l
)
f(x;\theta_1,\theta_2,\cdots,\theta_l)
f(x;θ1,θ2,⋯,θl),其中
θ
1
,
θ
2
,
⋯
,
θ
l
\theta_1,\theta_2,\cdots,\theta_l
θ1,θ2,⋯,θl为未知参数,在参数空间
Θ
\Theta
Θ内取值,变量
x
x
x在随机变量
X
X
X的可能取值范围内取值。设
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
(X1,X2,⋯,Xn)是来自总体
X
X
X的样本,则
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
(X1,X2,⋯,Xn)的分布律为
L
(
x
1
,
x
2
,
⋯
,
x
n
;
θ
1
,
θ
2
,
⋯
,
θ
l
)
=
P
{
X
1
=
x
1
,
X
2
=
x
2
,
⋯
,
X
n
=
x
n
}
=
∏
i
=
1
n
p
(
x
i
;
θ
1
,
θ
2
,
⋯
,
θ
l
)
\begin{aligned} L(x_1,x_2,\cdots,x_n;\theta_1,\theta_2,\cdots,\theta_l)&=P\{X_1=x_1,X_2=x_2,\cdots,X_n=x_n\}\\ &=\prod\limits_{i=1}^n p(x_i;\theta_1,\theta_2,\cdots,\theta_l) \end{aligned}
L(x1,x2,⋯,xn;θ1,θ2,⋯,θl)=P{X1=x1,X2=x2,⋯,Xn=xn}=i=1∏np(xi;θ1,θ2,⋯,θl)或概率密度为
L
(
x
1
,
x
2
,
⋯
,
x
n
;
θ
1
,
θ
2
,
⋯
,
θ
l
)
=
∏
i
=
1
n
f
(
x
i
;
θ
1
,
θ
2
,
⋯
,
θ
l
)
L(x_1,x_2,\cdots,x_n;\theta_1,\theta_2,\cdots,\theta_l)=\prod\limits_{i=1}^n f(x_i;\theta_1,\theta_2,\cdots,\theta_l)
L(x1,x2,⋯,xn;θ1,θ2,⋯,θl)=i=1∏nf(xi;θ1,θ2,⋯,θl)当固定
(
x
1
,
x
2
,
⋯
,
x
n
)
(x_1,x_2,\cdots,x_n)
(x1,x2,⋯,xn),把
L
L
L看成是
θ
1
,
θ
2
,
⋯
,
θ
l
\theta_1,\theta_2,\cdots,\theta_l
θ1,θ2,⋯,θl的定义于
Θ
\Theta
Θ上的函数时,它称为参数
θ
1
,
θ
2
,
⋯
,
θ
l
\theta_1,\theta_2,\cdots,\theta_l
θ1,θ2,⋯,θl的似然函数,并简记为
L
(
θ
1
,
θ
2
,
⋯
,
θ
l
)
L(\theta_1,\theta_2,\cdots,\theta_l)
L(θ1,θ2,⋯,θl)。即:似然函数就是样本的分布律/概率密度,然后看成参数的函数。
对数似然函数:似然函数的对数
ln
L
(
θ
1
,
θ
2
,
⋯
,
θ
l
)
\ln L(\theta_1,\theta_2,\cdots,\theta_l)
lnL(θ1,θ2,⋯,θl)称为对数似然函数。
最大似然估计法:得到样本值 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn)后,取 θ ^ 1 , θ ^ 2 , ⋯ , θ ^ n \hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_n θ^1,θ^2,⋯,θ^n使得 L ( θ ^ 1 , θ ^ 2 , ⋯ , θ ^ n ) = max ( θ 1 , θ 2 , ⋯ , θ l ) ∈ Θ L ( θ 1 , θ 2 , ⋯ , θ l ) L(\hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_n)=\max\limits_{(\theta_1,\theta_2,\cdots,\theta_l)\in\Theta}L(\theta_1,\theta_2,\cdots,\theta_l) L(θ^1,θ^2,⋯,θ^n)=(θ1,θ2,⋯,θl)∈ΘmaxL(θ1,θ2,⋯,θl)这样得到的 θ ^ 1 , θ ^ 2 , ⋯ , θ ^ n \hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_n θ^1,θ^2,⋯,θ^n与样本值 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn)有关,记为 θ ^ i = θ ^ i ( x 1 , x 2 , ⋯ , x n ) \hat{\theta}_i=\hat{\theta}_i(x_1,x_2,\cdots,x_n) θ^i=θ^i(x1,x2,⋯,xn),并称为参数 θ i ( i = 1 , 2 , ⋯ , l ) \theta_i\,(i=1,2,\cdots,l) θi(i=1,2,⋯,l)的最大似然估计值,而相应的统计量 θ ^ i = θ ^ i ( X 1 , X 2 , ⋯ , X n ) ( i = 1 , 2 , ⋯ , l ) \hat{\theta}_i=\hat{\theta}_i(X_1,X_2,\cdots,X_n)\,(i=1,2,\cdots,l) θ^i=θ^i(X1,X2,⋯,Xn)(i=1,2,⋯,l)称为参数 θ i \theta_i θi的最大似然估计量。
由于 ln x \ln x lnx是 x x x的单调增函数,所以 L L L取最大的时候 ln L \ln L lnL也取最大,我们也可以考察 ln L \ln L lnL的最大值。
在很多时候, L L L和 ln L \ln L lnL关于参数 θ 1 , θ 2 , ⋯ , θ l \theta_1,\theta_2,\cdots,\theta_l θ1,θ2,⋯,θl的偏导数存在,此时 θ ^ 1 , θ ^ 2 , ⋯ , θ ^ n \hat{\theta}_1,\hat{\theta}_2,\cdots,\hat{\theta}_n θ^1,θ^2,⋯,θ^n可从似然方程 { ∂ L ( θ 1 , θ 2 , ⋯ , θ l ) ∂ θ 1 = 0 ∂ L ( θ 1 , θ 2 , ⋯ , θ l ) ∂ θ 2 = 0 ⋯ ∂ L ( θ 1 , θ 2 , ⋯ , θ l ) ∂ θ l = 0 \begin{cases} \cfrac{\partial L(\theta_1,\theta_2,\cdots,\theta_l)}{\partial\theta_1}=0\\ \cfrac{\partial L(\theta_1,\theta_2,\cdots,\theta_l)}{\partial\theta_2}=0\\ \cdots\\ \cfrac{\partial L(\theta_1,\theta_2,\cdots,\theta_l)}{\partial\theta_l}=0 \end{cases} ⎩ ⎨ ⎧∂θ1∂L(θ1,θ2,⋯,θl)=0∂θ2∂L(θ1,θ2,⋯,θl)=0⋯∂θl∂L(θ1,θ2,⋯,θl)=0或对数似然方程 { ∂ ln L ( θ 1 , θ 2 , ⋯ , θ l ) ∂ θ 1 = 0 ∂ ln L ( θ 1 , θ 2 , ⋯ , θ l ) ∂ θ 2 = 0 ⋯ ∂ ln L ( θ 1 , θ 2 , ⋯ , θ l ) ∂ θ l = 0 \begin{cases} \cfrac{\partial\ln L(\theta_1,\theta_2,\cdots,\theta_l)}{\partial\theta_1}=0\\ \cfrac{\partial\ln L(\theta_1,\theta_2,\cdots,\theta_l)}{\partial\theta_2}=0\\ \cdots\\ \cfrac{\partial\ln L(\theta_1,\theta_2,\cdots,\theta_l)}{\partial\theta_l}=0 \end{cases} ⎩ ⎨ ⎧∂θ1∂lnL(θ1,θ2,⋯,θl)=0∂θ2∂lnL(θ1,θ2,⋯,θl)=0⋯∂θl∂lnL(θ1,θ2,⋯,θl)=0中解出。
例 设
X
~
U
(
0
,
θ
)
\newcommand{\td}{\,\text{\large\textasciitilde}\,}X\td U(0,\theta)
X~U(0,θ),求
θ
\theta
θ的最大似然估计量。
解:
X
X
X的概率密度为
f
(
x
;
θ
)
=
{
1
θ
,
0
≤
x
≤
θ
0
,
其他
f(x;\theta)=\begin{cases}\frac{1}{\theta},&0\le x\le\theta\\0,&\text{其他}\end{cases}
f(x;θ)={θ1,0,0≤x≤θ其他则样本
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
(X1,X2,⋯,Xn)的联合概率密度为
f
(
x
1
,
x
2
,
⋯
,
x
n
;
θ
)
=
∏
i
=
1
n
f
(
x
i
;
θ
)
=
{
1
θ
n
,
0
≤
x
1
,
x
2
,
⋯
,
x
n
≤
θ
0
,
其他
f(x_1,x_2,\cdots,x_n;\theta)=\prod\limits_{i=1}^n f(x_i;\theta)=\begin{cases} \frac{1}{\theta^n},&0\le x_1,x_2,\cdots,x_n\le\theta\\ 0,&\text{其他} \end{cases}
f(x1,x2,⋯,xn;θ)=i=1∏nf(xi;θ)={θn1,0,0≤x1,x2,⋯,xn≤θ其他把它看作
θ
\theta
θ的函数(
x
1
,
x
2
,
⋯
,
x
n
x_1,x_2,\cdots,x_n
x1,x2,⋯,xn为已知),那么
θ
\theta
θ的似然函数为
L
(
θ
)
=
{
1
θ
n
,
θ
≥
max
{
x
1
,
x
2
,
⋯
,
x
n
}
0
,
其他
L(\theta)=\begin{cases} \frac{1}{\theta^n},&\theta\ge\max\{x_1,x_2,\cdots,x_n\}\\ 0,&\text{其他} \end{cases}
L(θ)={θn1,0,θ≥max{x1,x2,⋯,xn}其他这个函数我们不用求导就能求出最大值。首先,它在
θ
≥
max
{
x
1
,
x
2
,
⋯
,
x
n
}
\theta\ge\max\{x_1,x_2,\cdots,x_n\}
θ≥max{x1,x2,⋯,xn}时才是正数;其次,在
θ
\theta
θ满足这个条件的情况下,因为
θ
n
\theta^n
θn在分母,所以我们希望
θ
\theta
θ尽量小。因此当
θ
=
max
{
x
1
,
x
2
,
⋯
,
x
n
}
\theta=\max\{x_1,x_2,\cdots,x_n\}
θ=max{x1,x2,⋯,xn}时
L
(
θ
)
L(\theta)
L(θ)取最大值。
θ
\theta
θ的最大似然估计量为
θ
^
=
X
(
n
)
\hat{\theta}=X_{(n)}
θ^=X(n)。这与矩估计法求得的估计量不同。
二、估计量的评选标准
1. 无偏性
无偏估计量:设
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
(X1,X2,⋯,Xn)是来自总体
X
X
X的一个样本,
θ
\theta
θ是包含在
X
X
X的分布中的未知参数,
θ
\theta
θ的取值范围为
Θ
\Theta
Θ,
θ
^
=
θ
^
(
X
1
,
X
2
,
⋯
,
X
n
)
\hat{\theta}=\hat{\theta}(X_1,X_2,\cdots,X_n)
θ^=θ^(X1,X2,⋯,Xn)是
θ
\theta
θ的一个估计量。若
∀
θ
∈
Θ
\forall\theta\in\Theta
∀θ∈Θ,
E
(
θ
^
)
=
θ
E\left(\hat{\theta}\right)=\theta
E(θ^)=θ,则称
θ
^
\hat{\theta}
θ^是
θ
\theta
θ的一个无偏估计量。
有偏估计量:有偏差的估计量,其中偏差(简称偏)等于
E
(
θ
^
)
−
θ
E\left(\hat{\theta}\right)-\theta
E(θ^)−θ。
渐进无偏估计量:若
E
(
θ
^
)
−
θ
≠
0
E\left(\hat{\theta}\right)-\theta\ne0
E(θ^)−θ=0,但当样本容量
n
→
∞
n\to\infty
n→∞时,有
lim
n
→
∞
[
E
(
θ
^
)
−
θ
]
=
0
\lim\limits_{n\to\infty}\left[E\left(\hat{\theta}\right)-\theta\right]=0
n→∞lim[E(θ^)−θ]=0,则称
θ
^
\hat{\theta}
θ^是
θ
\theta
θ的渐近无偏估计量。
设
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
(X1,X2,⋯,Xn)是来自总体
X
X
X的样本,无论
X
X
X服从什么分布,都有
(1) 若
E
(
X
)
=
μ
E(X)=\mu
E(X)=μ存在,则样本均值
X
‾
\overline{X}
X是
E
(
X
)
E(X)
E(X)的无偏估计量;
(2) 若
D
(
X
)
=
σ
2
D(X)=\sigma^2
D(X)=σ2存在,则样本方差
S
2
S^2
S2是
σ
2
\sigma^2
σ2的无偏估计量;
(3) 若总体
k
k
k阶矩
E
(
X
k
)
=
α
k
E\left(X^k\right)=\alpha_k
E(Xk)=αk存在,则
k
k
k阶样本原点矩
A
k
=
1
k
∑
i
=
1
n
X
i
k
A_k=\frac{1}{k}\sum\limits_{i=1}^n X_i^k
Ak=k1i=1∑nXik是
k
k
k阶总体原点矩
α
k
\alpha_k
αk的无偏估计量。
例 可以证明,设总体 X ~ U ( 0 , θ ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}X\td U(0,\theta) X~U(0,θ),参数 θ > 0 \theta>0 θ>0,则 2 X ‾ 2\overline{X} 2X和 n + 1 n X ( n ) \frac{n+1}{n}X_{(n)} nn+1X(n)都是 θ \theta θ的无偏估计量。
虽然 S 2 S^2 S2是 σ 2 \sigma^2 σ2的无偏估计量,但 S S S不是 σ \sigma σ的无偏估计量, n − 1 2 Γ ( n − 1 2 ) Γ ( n 2 ) S \sqrt{\frac{n-1}{2}}\frac{\Gamma\left(\frac{n-1}{2}\right)}{\Gamma\left(\frac{n}{2}\right)}S 2n−1Γ(2n)Γ(2n−1)S才是 σ \sigma σ的无偏估计量。这说明,若 θ ^ \hat{\theta} θ^是 θ \theta θ的无偏估计量,一般情况下, g ( θ ^ ) g\left(\hat{\theta}\right) g(θ^)不是 θ \theta θ的无偏估计量,除非 g g g是线性函数。
2. 有效性
无偏估计量不一定是唯一的,所以我们需要选取其中取值最集中的,即方差最小的作为最好的估计量。
有效性:设 θ ^ 1 \hat{\theta}_1 θ^1和 θ ^ 2 \hat{\theta}_2 θ^2都是 θ \theta θ的无偏估计量,若 D ( θ ^ 1 ) ≤ D ( θ ^ 2 ) D\left(\hat{\theta}_1\right)\le D\left(\hat{\theta}_2\right) D(θ^1)≤D(θ^2),则称 θ ^ 1 \hat{\theta}_1 θ^1较 θ ^ 2 \hat{\theta}_2 θ^2有效。
例 设 X ~ U ( 0 , θ ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}X\td U(0,\theta) X~U(0,θ),则 θ ^ 2 = n + 1 n X ( n ) \hat{\theta}_2=\frac{n+1}{n}X_{(n)} θ^2=nn+1X(n)比 θ ^ 1 = 2 X ‾ \hat{\theta}_1=2\overline{X} θ^1=2X有效( D ( θ ^ 1 ) = θ 2 3 n > D ( θ ^ 2 ) = θ 2 n ( n + 2 ) D\left(\hat{\theta}_1\right)=\frac{\theta^2}{3n}>D\left(\hat{\theta}_2\right)=\frac{\theta^2}{n(n+2)} D(θ^1)=3nθ2>D(θ^2)=n(n+2)θ2)。
最小方差无偏估计量:在所有估计量中方差最小的无偏估计量
3. 相合性
相合估计量/一致估计量:设
θ
^
=
θ
^
(
X
1
,
X
2
,
⋯
,
X
n
)
\hat{\theta}=\hat{\theta}(X_1,X_2,\cdots,X_n)
θ^=θ^(X1,X2,⋯,Xn)是参数
θ
\theta
θ的估计量,如果当
n
→
∞
n\to\infty
n→∞时,
θ
^
\hat{\theta}
θ^依概率收敛于
θ
\theta
θ,即
∀
ε
>
0
,
lim
n
→
∞
P
{
∣
θ
^
−
θ
∣
<
ε
}
=
1
\forall\varepsilon>0,\,\lim\limits_{n\to\infty}P\left\{\left|\hat{\theta}-\theta\right|<\varepsilon\right\}=1
∀ε>0,n→∞limP{
θ^−θ
<ε}=1则称
θ
^
\hat{\theta}
θ^为
θ
\theta
θ的相合估计量/一致估计量,并记
(
p
)
lim
n
→
∞
θ
^
=
θ
(p)\lim\limits_{n\to\infty}\hat{\theta}=\theta
(p)n→∞limθ^=θ或
θ
^
⟶
P
θ
(
n
→
∞
)
\hat{\theta}\overset{P}{\longrightarrow}\theta(n\to\infty)
θ^⟶Pθ(n→∞)。
均方相合估计量:如果当
n
→
∞
n\to\infty
n→∞时,
θ
^
\hat{\theta}
θ^均方收敛于
θ
\theta
θ,即
lim
n
→
∞
E
[
(
θ
^
−
θ
)
2
]
=
0
\lim\limits_{n\to\infty}E\left[{\left(\hat{\theta}-\theta\right)}^2\right]=0
n→∞limE[(θ^−θ)2]=0则称
θ
^
\hat{\theta}
θ^为
θ
\theta
θ的均方相合估计量,并记
(
m. s.
)
lim
n
→
∞
θ
^
=
θ
\newcommand{\ms}{(\text{m. s. })}\ms\lim\limits_{n\to\infty}\hat{\theta}=\theta
(m. s. )n→∞limθ^=θ或
θ
^
⟶
L
2
θ
(
n
→
∞
)
\hat{\theta}\overset{L^2}{\longrightarrow}\theta(n\to\infty)
θ^⟶L2θ(n→∞)。
相合性是对估计量的最基本的要求,它要求当样本容量无限增加时,用估计量估计参数可以达到任意小的精度。
可以证明,常见的矩估计量都是相合估计量(例如 A k → α k A_k\to\alpha_k Ak→αk、 X ‾ → E ( X ) \overline{X}\to E(X) X→E(X)、 S 2 → σ 2 S^2\to\sigma^2 S2→σ2、 S → σ S\to\sigma S→σ)。均方相合估计量一定是相合估计量,但反之不一定成立。
总结
无偏性:
E
(
θ
^
)
=
θ
E\left(\hat{\theta}\right)=\theta
E(θ^)=θ
有效性:方差越小越好
相合性:依概率收敛(样本容量足够大时估计值与真实值之间的差距可以任意小)
三、区间估计
1. 双侧区间估计
P
{
θ
^
1
(
X
1
,
X
2
,
⋯
,
X
n
)
<
θ
<
θ
^
2
(
X
1
,
X
2
,
⋯
,
X
n
)
}
=
1
−
α
⇓
\underset{\large\Downarrow}{P\left\{ \hat{\theta}_1(X_1,X_2,\cdots,X_n)<\theta<\hat{\theta}_2(X_1,X_2,\cdots,X_n) \right\}=1-\alpha}
⇓P{θ^1(X1,X2,⋯,Xn)<θ<θ^2(X1,X2,⋯,Xn)}=1−α随机区间
(
θ
^
1
,
θ
^
2
)
\left(\hat{\theta}_1,\hat{\theta}_2\right)
(θ^1,θ^2)为参数
θ
\theta
θ的置信度为
1
−
α
1-\alpha
1−α的双侧置信区间。
θ
^
1
\hat{\theta}_1
θ^1:置信下限
θ
^
2
\hat{\theta}_2
θ^2:置信上限
1
−
α
1-\alpha
1−α:置信度
α
\alpha
α:区间
(
θ
^
1
,
θ
^
2
)
\left(\hat{\theta}_1,\hat{\theta}_2\right)
(θ^1,θ^2)不包含
θ
\theta
θ的概率(一般很小)
在置信度 1 − α 1-\alpha 1−α给定的情况下,置信区间的长度 E ( θ ^ 2 − θ ^ 1 ) E\left(\hat{\theta}_2-\hat{\theta}_1\right) E(θ^2−θ^1)越小越好。
求未知参数 θ \theta θ的双侧置信区间的具体做法:
(1) 寻求枢轴量
Z
=
Z
(
X
1
,
X
2
,
⋯
,
X
n
,
θ
)
Z=Z\left(X_1,X_2,\cdots,X_n,\theta\right)
Z=Z(X1,X2,⋯,Xn,θ),我们需要知道
Z
Z
Z的分布,并且此分布不依赖于任何未知参数,也不依赖于
θ
\theta
θ。
(2) 对于给定的置信度
1
−
α
1-\alpha
1−α,求出两个常数
k
1
,
k
2
k_1,k_2
k1,k2使得
P
{
k
1
<
Z
<
k
2
}
=
1
−
α
P\{k_1<Z<k_2\}=1-\alpha
P{k1<Z<k2}=1−α。
(3)
k
1
<
Z
<
k
2
⟶
改写
θ
^
1
<
θ
<
θ
^
2
k_1<Z<k_2\overset{\text{改写}}{\Large{\longrightarrow}}\hat{\theta}_1<\theta<\hat{\theta}_2
k1<Z<k2⟶改写θ^1<θ<θ^2:
(
θ
^
1
,
θ
^
2
)
\left(\hat{\theta}_1,\hat{\theta}_2\right)
(θ^1,θ^2)是置信度为
1
−
α
1-\alpha
1−α的置信区间。
(4) 根据样本值计算
θ
^
1
,
θ
^
2
\hat{\theta}_1,\hat{\theta}_2
θ^1,θ^2的具体值。
例 设
X
~
N
(
μ
,
σ
2
)
\newcommand{\td}{\,\text{\large\textasciitilde}\,}X\td N(\mu,\sigma^2)
X~N(μ,σ2),
σ
2
\sigma^2
σ2已知,
μ
\mu
μ未知,求参数
μ
\mu
μ的置信度为
1
−
α
1-\alpha
1−α的置信区间。
解:取枢轴量
U
=
X
‾
−
μ
σ
/
n
~
N
(
0
,
1
)
\newcommand{\td}{\,\text{\large\textasciitilde}\,}U=\cfrac{\overline{X}-\mu}{\sigma/\sqrt{n}}\td N(0,1)
U=σ/nX−μ~N(0,1),可以看出
N
(
0
,
1
)
N(0,1)
N(0,1)不依赖任何参数。
现在要找到
k
1
,
k
2
k_1,k_2
k1,k2使得
P
{
k
1
<
U
<
k
2
}
=
1
−
α
P\left\{k_1<U<k_2\right\}=1-\alpha
P{k1<U<k2}=1−α,一般取
k
1
=
−
u
α
/
2
k_1=-u_{\alpha/2}
k1=−uα/2,
k
2
=
u
α
/
2
k_2=u_{\alpha/2}
k2=uα/2。注意到
−
u
α
/
2
=
u
1
−
α
/
2
-u_{\alpha/2}=u_{1-\alpha/2}
−uα/2=u1−α/2,我们有
P
{
k
1
<
U
<
k
2
}
=
1
−
P
{
U
≥
k
2
}
−
P
{
U
≤
k
1
}
=
1
−
α
2
−
(
1
−
P
{
U
>
k
1
}
)
=
1
−
α
2
−
[
1
−
(
1
−
α
2
)
]
=
α
\begin{aligned} P\{k_1<U<k_2\}&=1-P\{U\ge k_2\}-P\{U\le k_1\}\\ &=1-\frac{\alpha}{2}-\left(1-P\left\{U>k_1\right\}\right)\\ &=1-\frac{\alpha}{2}-\left[1-\left(1-\frac{\alpha}{2}\right)\right]\\ &=\alpha \end{aligned}
P{k1<U<k2}=1−P{U≥k2}−P{U≤k1}=1−2α−(1−P{U>k1})=1−2α−[1−(1−2α)]=α

既然 P { − u α / 2 < X ‾ − μ σ / n < u α / 2 } = 1 − α P\left\{-u_{\alpha/2}<\cfrac{\overline{X}-\mu}{\sigma/\sqrt{n}}<u_{\alpha/2}\right\}=1-\alpha P{−uα/2<σ/nX−μ<uα/2}=1−α,那么 P { − n σ u α / 2 < X ‾ − μ < n σ u α / 2 } = 1 − α P { X ‾ − n σ u α / 2 < μ < X ‾ + n σ u α / 2 } = 1 − α \begin{aligned} P\left\{-\frac{\sqrt{n}}{\sigma}u_{\alpha/2}<\overline{X}-\mu<\frac{\sqrt{n}}{\sigma}u_{\alpha/2}\right\}&=1-\alpha\\ P\left\{\overline{X}-\frac{\sqrt{n}}{\sigma}u_{\alpha/2}<\mu<\overline{X}+\frac{\sqrt{n}}{\sigma}u_{\alpha/2}\right\}&=1-\alpha \end{aligned} P{−σnuα/2<X−μ<σnuα/2}P{X−σnuα/2<μ<X+σnuα/2}=1−α=1−α于是得 μ \mu μ的置信度为 1 − α 1-\alpha 1−α的置信区间为 ( X ‾ − n σ u α / 2 , X ‾ + n σ u α / 2 ) \left(\overline{X}-\frac{\sqrt{n}}{\sigma}u_{\alpha/2},\overline{X}+\frac{\sqrt{n}}{\sigma}u_{\alpha/2}\right) (X−σnuα/2,X+σnuα/2)。
其实,选取枢轴量的过程就是从 X X X的分布中剔除参数 θ \theta θ的影响的过程。 X X X的分布受 θ \theta θ影响,我们就需要消除这种影响,所以我们提出统计量 Z Z Z,它的分布是完全确定的,只有这样我们才能确定参数 k 1 , k 2 k_1,k_2 k1,k2。如果 X X X的分布不是确定的,那么我们很难求出置信区间。
2. 单侧区间估计
P
{
θ
‾
(
X
1
,
X
2
,
⋯
,
X
n
)
<
θ
}
=
1
−
α
⟹
(
θ
‾
,
+
∞
)
P\left\{\underline{\theta}(X_1,X_2,\cdots,X_n)<\theta\right\}=1-\alpha\implies\left(\underline{\theta},+\infty\right)
P{θ(X1,X2,⋯,Xn)<θ}=1−α⟹(θ,+∞)是
θ
\theta
θ的置信度为
1
−
α
1-\alpha
1−α的单侧置信区间,
θ
‾
\underline{\theta}
θ为置信下界;
P
{
θ
<
θ
‾
(
X
1
,
X
2
,
⋯
,
X
n
)
}
=
1
−
α
⟹
(
−
∞
,
θ
‾
)
P\left\{\theta<\overline{\theta}(X_1,X_2,\cdots,X_n)\right\}=1-\alpha\implies\left(-\infty,\overline{\theta}\right)
P{θ<θ(X1,X2,⋯,Xn)}=1−α⟹(−∞,θ)是
θ
\theta
θ的置信度为
1
−
α
1-\alpha
1−α的单侧置信区间,
θ
‾
\overline{\theta}
θ为置信上界。
即: ( θ ‾ , + ∞ ) \left(\underline{\theta},+\infty\right) (θ,+∞)包含 θ \theta θ的概率为 1 − α 1-\alpha 1−α, ( − ∞ , θ ‾ ) \left(-\infty,\overline{\theta}\right) (−∞,θ)包含 θ \theta θ的概率为 1 − α 1-\alpha 1−α。
在置信度 1 − α 1-\alpha 1−α给定的情况下,置信下界越大越好,置信上界越小越好。
四、正态总体参数的区间估计
对于单个总体的情形,我们设 X ~ N ( μ , σ 2 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}X\td N(\mu,\sigma^2) X~N(μ,σ2);对于两个总体的情形,我们设 X ~ N ( μ 1 , σ 1 2 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}X\td N(\mu_1,\sigma_1^2) X~N(μ1,σ12), Y ~ N ( μ 2 , σ 2 2 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}Y\td N(\mu_2,\sigma_2^2) Y~N(μ2,σ22)。 X X X的样本容量为 n n n,样本方差为 S X 2 S_X^2 SX2; Y Y Y的样本容量为 m m m,样本方差为 S Y 2 S_Y^2 SY2。
σ 2 \sigma^2 σ2已知,考察 μ \mu μ
枢轴量 U = n ( X ‾ − μ ) σ ~ N ( 0 , 1 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}U=\cfrac{\sqrt{n}\left(\overline{X}-\mu\right)}{\sigma}\td N(0,1) U=σn(X−μ)~N(0,1)
注意
P
{
−
u
α
/
2
<
U
<
u
α
/
2
}
=
1
−
α
P\left\{-u_{\alpha/2}<U<u_{\alpha/2}\right\}=1-\alpha
P{−uα/2<U<uα/2}=1−α
P
{
U
<
u
α
}
=
1
−
α
P\left\{U<u_\alpha\right\}=1-\alpha
P{U<uα}=1−α
P
{
U
>
−
u
α
}
=
1
−
α
P\left\{U>-u_\alpha\right\}=1-\alpha
P{U>−uα}=1−α
σ 2 \sigma^2 σ2未知,考察 μ \mu μ
枢轴量 T = n ( X ‾ − μ ) S ~ t ( n − 1 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}T=\cfrac{\sqrt{n}\left(\overline{X}-\mu\right)}{S}\td t(n-1) T=Sn(X−μ)~t(n−1)
注意
P
{
−
t
α
/
2
<
T
<
t
α
/
2
}
=
1
−
α
P\left\{-t_{\alpha/2}<T<t_{\alpha/2}\right\}=1-\alpha
P{−tα/2<T<tα/2}=1−α
P
{
T
<
t
α
}
=
1
−
α
P\left\{T<t_\alpha\right\}=1-\alpha
P{T<tα}=1−α
P
{
T
>
−
t
α
}
=
1
−
α
P\left\{T>-t_\alpha\right\}=1-\alpha
P{T>−tα}=1−α
μ \mu μ已知,考察 σ 2 \sigma^2 σ2
枢轴量 χ 2 = ∑ i = 1 n ( X i − μ ) 2 σ 2 ~ χ 2 ( n ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}\chi^2=\cfrac{\sum\limits_{i=1}^n{\left(X_i-\mu\right)}^2}{\sigma^2}\td\chi^2(n) χ2=σ2i=1∑n(Xi−μ)2~χ2(n)
μ \mu μ未知,考察 σ 2 \sigma^2 σ2
枢轴量
χ
2
=
∑
i
=
1
n
(
X
i
−
X
‾
)
2
σ
2
=
(
n
−
1
)
S
2
σ
2
~
χ
2
(
n
−
1
)
\newcommand{\td}{\,\text{\large\textasciitilde}\,}\chi^2=\cfrac{\sum\limits_{i=1}^n{\left(X_i-\overline{X}\right)}^2}{\sigma^2}=\cfrac{(n-1)S^2}{\sigma^2}\td\chi^2(n-1)
χ2=σ2i=1∑n(Xi−X)2=σ2(n−1)S2~χ2(n−1)
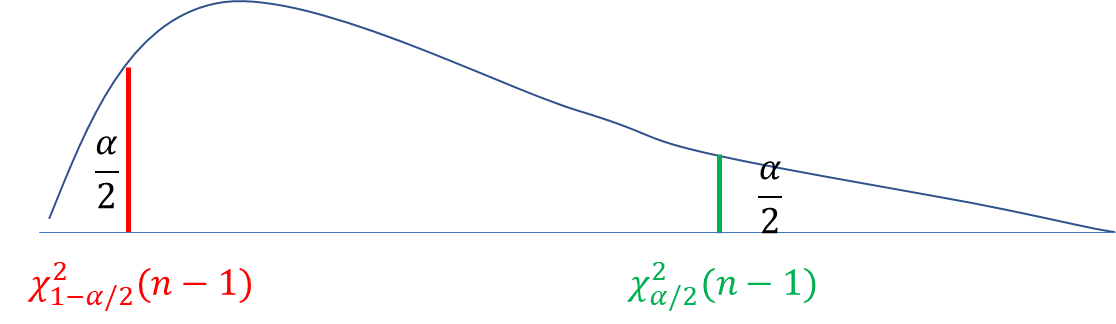
注意
P
{
χ
2
>
χ
α
/
2
2
(
n
−
1
)
}
=
α
2
P\left\{\chi^2>\chi^2_{\alpha/2}(n-1)\right\}=\frac{\alpha}{2}
P{χ2>χα/22(n−1)}=2α,
P
{
χ
2
>
χ
1
−
α
/
2
2
(
n
−
1
)
}
=
1
−
α
2
P\left\{\chi^2>\chi^2_{1-\alpha/2}(n-1)\right\}=1-\frac{\alpha}{2}
P{χ2>χ1−α/22(n−1)}=1−2α,故
P
{
χ
1
−
α
/
2
2
(
n
−
1
)
<
χ
2
<
χ
α
/
2
2
(
n
−
1
)
}
=
1
−
α
P\{\chi^2_{1-\alpha/2}(n-1)<\chi^2<\chi^2_{\alpha/2}(n-1)\}=1-\alpha
P{χ1−α/22(n−1)<χ2<χα/22(n−1)}=1−α。
P
{
χ
2
<
χ
α
2
(
n
−
1
)
}
=
1
−
α
P\left\{\chi^2<\chi^2_{\alpha}(n-1)\right\}=1-\alpha
P{χ2<χα2(n−1)}=1−α
P
{
χ
2
>
χ
1
−
α
2
(
n
−
1
)
}
=
1
−
α
P\left\{\chi^2>\chi^2_{1-\alpha}(n-1)\right\}=1-\alpha
P{χ2>χ1−α2(n−1)}=1−α
σ 1 2 , σ 2 2 \sigma_1^2,\sigma_2^2 σ12,σ22已知,考察 μ 1 − μ 2 \mu_1-\mu_2 μ1−μ2
枢轴量 U = ( X ‾ − Y ‾ ) − ( μ 1 − μ 2 ) σ 1 2 n + σ 2 2 m ~ N ( 0 , 1 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}U=\cfrac{\left(\overline{X}-\overline{Y}\right)-(\mu_1-\mu_2)}{\sqrt{\frac{\sigma_1^2}{n}+\frac{\sigma_2^2}{m}}}\td N(0,1) U=nσ12+mσ22(X−Y)−(μ1−μ2)~N(0,1)
注意 D ( X ‾ − Y ‾ ) = σ 1 2 n + σ 2 2 m D\left(\overline{X}-\overline{Y}\right)=\frac{\sigma_1^2}{n}+\frac{\sigma_2^2}{m} D(X−Y)=nσ12+mσ22。
σ 1 2 = σ 2 2 \sigma_1^2=\sigma_2^2 σ12=σ22未知,考察 μ 1 − μ 2 \mu_1-\mu_2 μ1−μ2
枢轴量 T = ( X ‾ − Y ‾ ) − ( μ 1 − μ 2 ) S W 1 n + 1 m ~ t ( n + m − 2 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}T=\cfrac{\left(\overline{X}-\overline{Y}\right)-(\mu_1-\mu_2)}{S_W\sqrt{\frac{1}{n}+\frac{1}{m}}}\td t(n+m-2) T=SWn1+m1(X−Y)−(μ1−μ2)~t(n+m−2),其中 S W = ( n − 1 ) S X 2 + ( m − 1 ) S Y 2 n + m − 2 S_W=\sqrt{\cfrac{(n-1)S_X^2+(m-1)S_Y^2}{n+m-2}} SW=n+m−2(n−1)SX2+(m−1)SY2
注意 U = ( X ‾ − Y ‾ ) − ( μ 1 − μ 2 ) σ 1 n + 1 m ~ N ( 0 , 1 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}U=\frac{\left(\overline{X}-\overline{Y}\right)-(\mu_1-\mu_2)}{\sigma\sqrt{\frac{1}{n}+\frac{1}{m}}}\td N(0,1) U=σn1+m1(X−Y)−(μ1−μ2)~N(0,1), V = ( n − 1 ) S X 2 + ( m − 1 ) S Y 2 σ 2 ~ χ 2 ( n + m − 2 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}V=\frac{(n-1)S_X^2+(m-1)S_Y^2}{\sigma^2}\td\chi^2(n+m-2) V=σ2(n−1)SX2+(m−1)SY2~χ2(n+m−2)。
μ 1 , μ 2 \mu_1,\mu_2 μ1,μ2已知,考察 σ 1 2 σ 2 2 \frac{\sigma_1^2}{\sigma_2^2} σ22σ12
枢轴量 F = ∑ i = 1 n ( X i − μ 1 ) 2 σ 1 2 / n ∑ j = 1 m ( Y j − μ 2 ) 2 σ 2 2 / m = σ 2 2 σ 1 2 m ∑ i = 1 n ( X i − μ 1 ) 2 n ∑ j = 1 m ( Y j − μ 2 ) 2 ~ F ( n , m ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}F=\cfrac{\left.\sum\limits_{i=1}^n\cfrac{{(X_i-\mu_1)}^2}{\sigma_1^2}\right/n}{\left.\sum\limits_{j=1}^m\cfrac{{(Y_j-\mu_2)}^2}{\sigma_2^2}\right/m}=\cfrac{\sigma_2^2}{\sigma_1^2}\cfrac{m\sum\limits_{i=1}^n{(X_i-\mu_1)}^2}{n\sum\limits_{j=1}^m{(Y_j-\mu_2)}^2}\td F(n,m) F=j=1∑mσ22(Yj−μ2)2/mi=1∑nσ12(Xi−μ1)2/n=σ12σ22nj=1∑m(Yj−μ2)2mi=1∑n(Xi−μ1)2~F(n,m)
μ 1 , μ 2 \mu_1,\mu_2 μ1,μ2未知,考察 σ 1 2 σ 2 2 \frac{\sigma_1^2}{\sigma_2^2} σ22σ12
枢轴量 F = σ 2 2 σ 1 2 S 1 2 S 2 2 ~ F ( n − 1 , m − 1 ) \newcommand{\td}{\,\text{\large\textasciitilde}\,}F=\cfrac{\sigma_2^2}{\sigma_1^2}\cfrac{S_1^2}{S_2^2}\td F(n-1,m-1) F=σ12σ22S22S12~F(n−1,m−1)
注意
P
{
F
>
F
α
/
2
(
n
−
1
,
m
−
1
)
}
=
α
2
P\left\{F>F_{\alpha/2}(n-1,m-1)\right\}=\frac{\alpha}{2}
P{F>Fα/2(n−1,m−1)}=2α,
P
{
F
>
F
1
−
α
/
2
(
n
−
1
,
m
−
1
)
}
=
1
−
α
2
P\left\{F>F_{1-\alpha/2}(n-1,m-1)\right\}=1-\frac{\alpha}{2}
P{F>F1−α/2(n−1,m−1)}=1−2α,故
P
{
F
1
−
α
/
2
(
n
−
1
,
m
−
1
)
<
F
<
F
α
/
2
(
n
−
1
,
m
−
1
)
}
=
1
−
α
P\{F_{1-\alpha/2}(n-1,m-1)<F<F_{\alpha/2}(n-1,m-1)\}=1-\alpha
P{F1−α/2(n−1,m−1)<F<Fα/2(n−1,m−1)}=1−α。
P
{
F
<
F
α
(
n
−
1
,
m
−
1
)
}
=
1
−
α
P\left\{F<F_{\alpha}(n-1,m-1)\right\}=1-\alpha
P{F<Fα(n−1,m−1)}=1−α
P
{
F
>
F
1
−
α
(
n
−
1
,
m
−
1
)
}
=
1
−
α
P\left\{F>F_{1-\alpha}(n-1,m-1)\right\}=1-\alpha
P{F>F1−α(n−1,m−1)}=1−α
t
t
t分布和标准正态分布
N
(
0
,
1
)
N(0,1)
N(0,1)类似,概率密度曲线都是关于
x
=
0
x=0
x=0对称的,
u
1
−
α
=
−
u
α
u_{1-\alpha}=-u_\alpha
u1−α=−uα,
t
1
−
α
(
n
)
=
−
t
α
(
n
)
t_{1-\alpha}(n)=-t_\alpha(n)
t1−α(n)=−tα(n);
F
F
F分布和
χ
2
\chi^2
χ2分布类似,概率密度都只在
x
>
0
x>0
x>0时为正。
不论 X X X服从何分布,都满足 P { q 1 − α / 2 < X < q α / 2 } = 1 − α P\{q_{1-\alpha/2}<X<q_{\alpha/2}\}=1-\alpha P{q1−α/2<X<qα/2}=1−α,其中 q α q_{\alpha} qα表示 X X X服从的分布的上侧 α \alpha α分位数。
关于自由度是多少,可以这么考虑:如果总体均值 μ \mu μ已知,那么自由度就是样本容量;如果总体均值 μ \mu μ未知,而用样本均值 X ‾ \overline{X} X代替的话,就要损失一个自由度。对于检验样本均值差时所用的 t t t分布,它的自由度是二者的自由度之和。









![[go学习笔记.第十八章.数据结构] 2.约瑟夫问题,排序,栈,递归,哈希表,二叉树的三种遍历方式](https://img-blog.csdnimg.cn/c059abcbe7cc4f848b6fa547111fab07.png)