文章目录
- MySQL表的基本操作介绍
- 插入结果查询(表去重)
- 建表
- 插入数据
- 操作
- 聚合函数
- 建表
- 插入数据
- 操作
- group by(分组)
- 建表
- 插入数据
- 操作
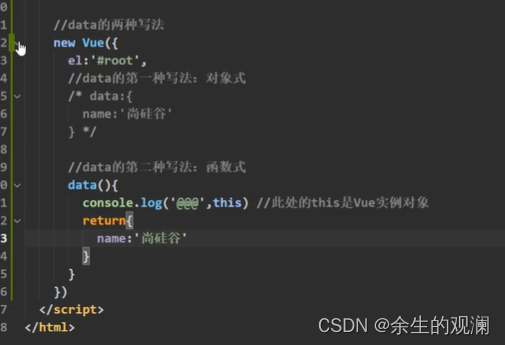
MySQL表的基本操作介绍
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
插入结果查询(表去重)
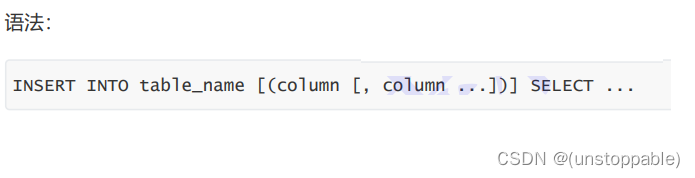
建表
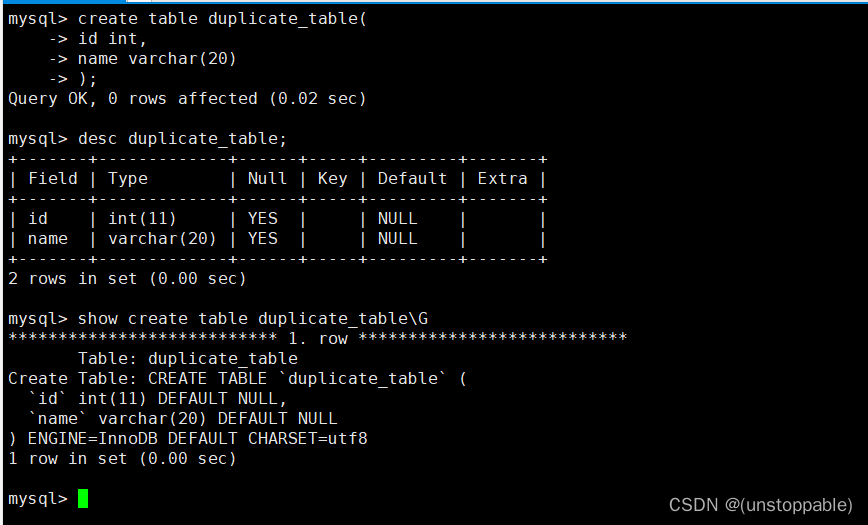
插入数据
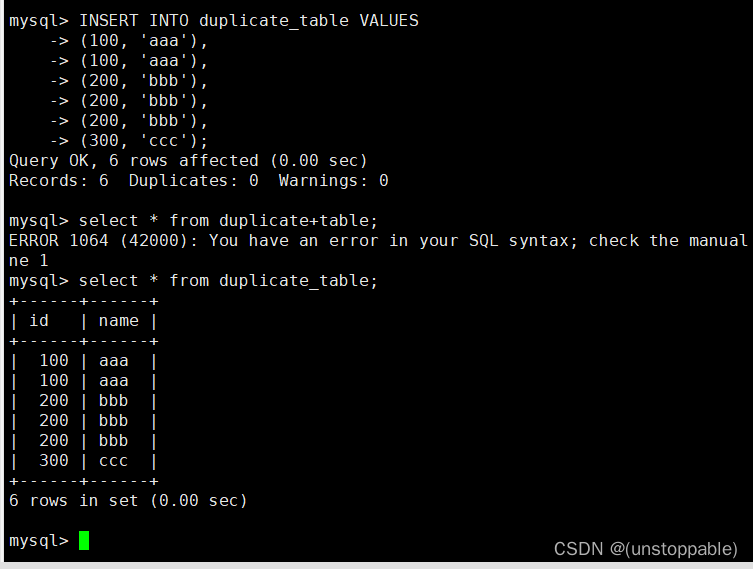
操作
删除表中的的重复复记录,重复的数据只能有一份
1.去重(不影响原表)
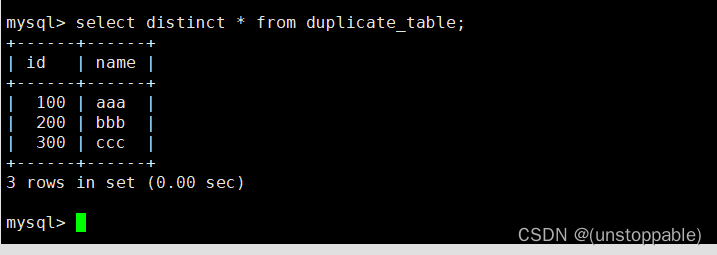
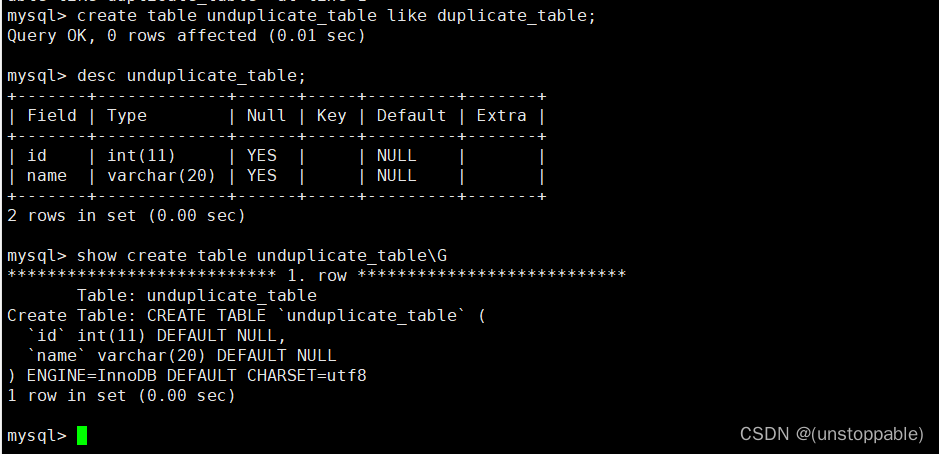
2.创建一个新的表,表的结构和duplicate_table表一样
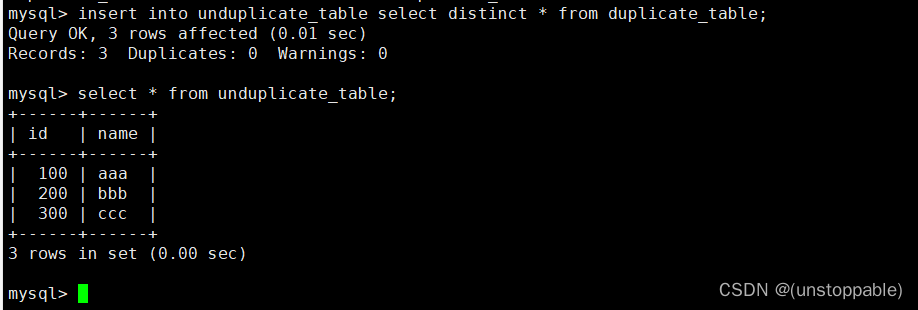
3.将 duplicate_table 的去重数据插入到 no_duplicate_table
4.通过重命名表,实现原子的去重操作+查看duplicate_table
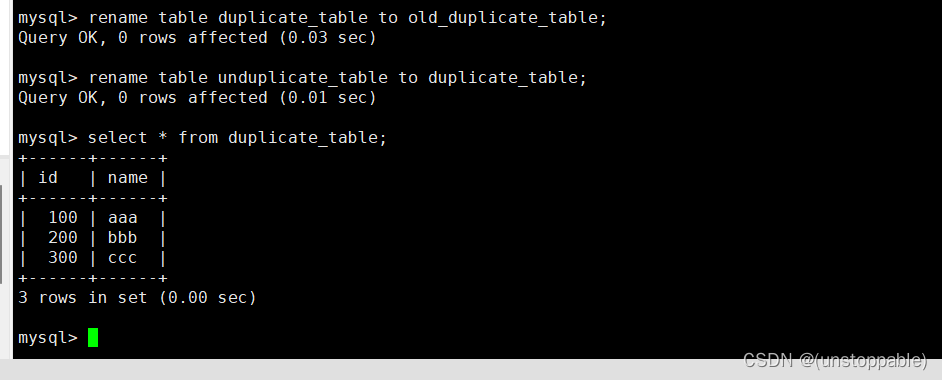
为什么最后是通过rename的方式进行的呢?
就是单纯的想等一切都就绪了,然后统一对数据进行放入、更新和生效等。
聚合函数
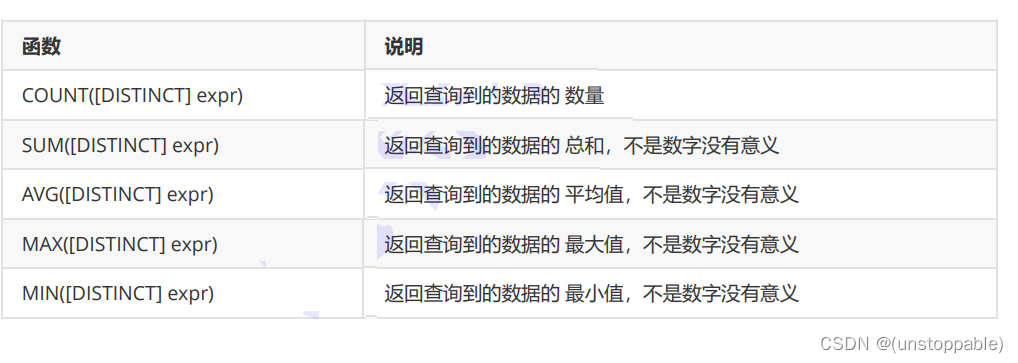
建表
这里就不建立,之前就已经建过了,大家可以根据表信息自己去建立表
插入数据
因为之前就已经插入过了,这里就给大家看一下数据表,要操作的大家可以自行插入数据。
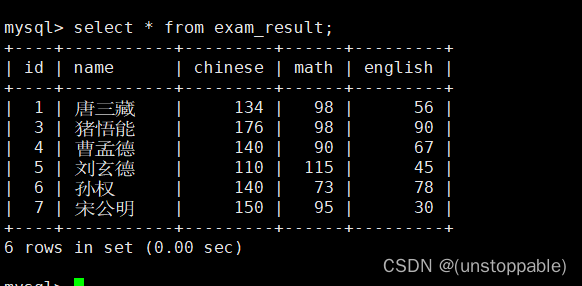
操作
统计班级共有多少同学
原表:
统计: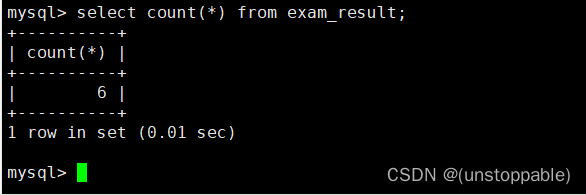
统计本次考试的数学成绩分数个数
原表:
统计:
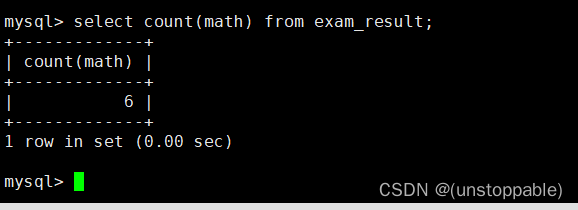
我们会发现统计出来是错的,因为数学成绩有重复的,重复的数学成绩只能算一个。
所以统计的时候要去重。

我们会发现不能统计的同时去重,要先去重再统计
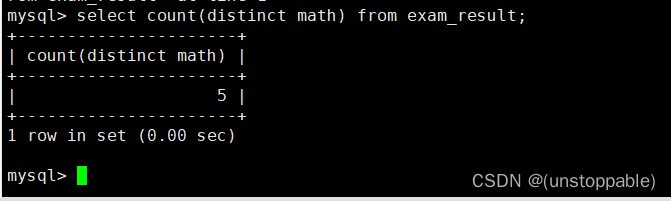
统计数学成绩总分
原表:
统计:

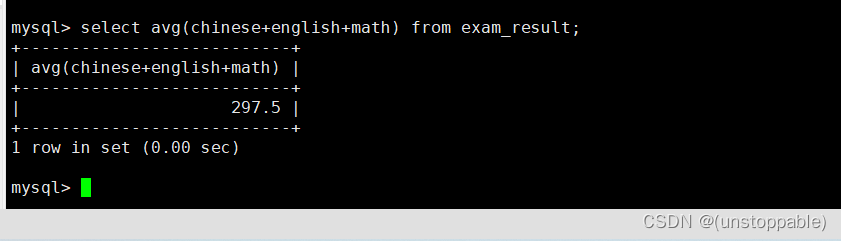
统计平均总分
原表:
统计:
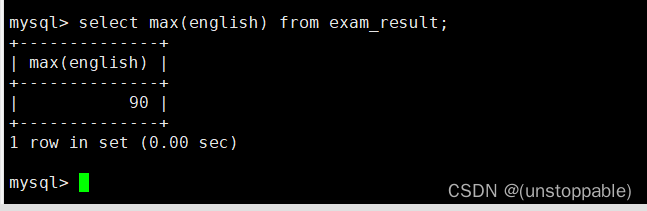
返回英语最高分
原表:
统计:
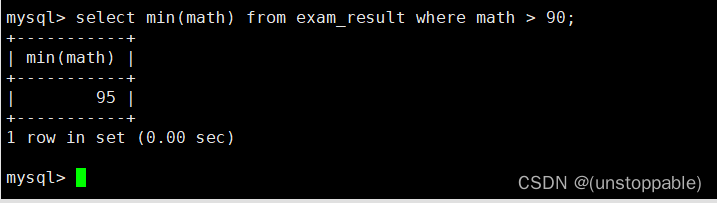
返回 > 90 分以上的数学最低分
原表:
统计:
group by(分组)
如果我们既要打出数学成绩最高分又要打出那个人的名字可以吗?

我们测试了发现不行,为什么呢?
因为name不能聚合。
这时我们就要用到分组了。
语法:

建表
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
插入数据
大家根据数据自行插入
部门表数据:
工资等级表数据:
员工信息表数据:
操作
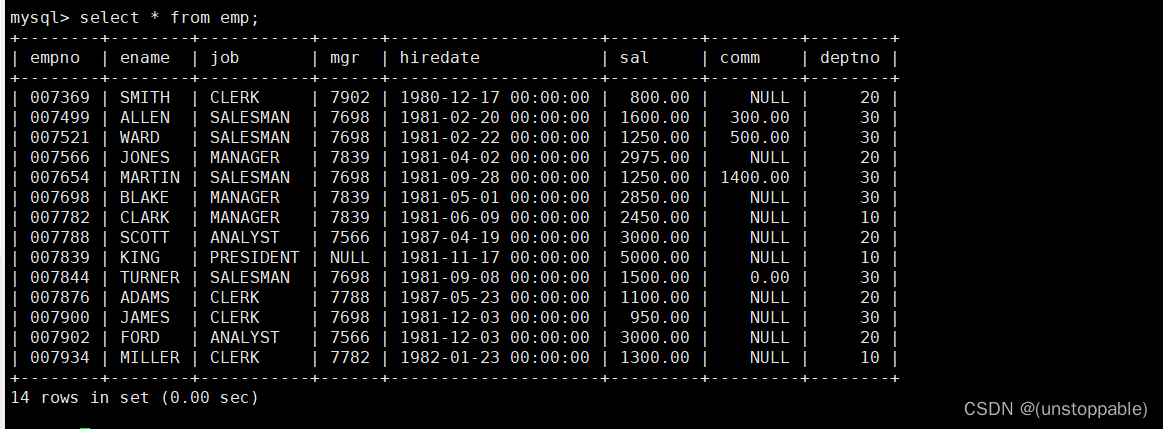
显示每个部门的平均工资和最高工资
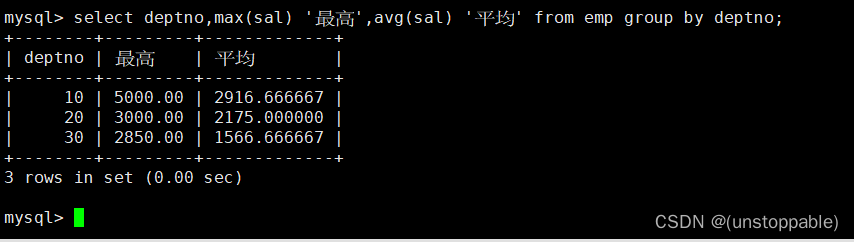

显示每个部门的每种岗位的平均工资和最低工资
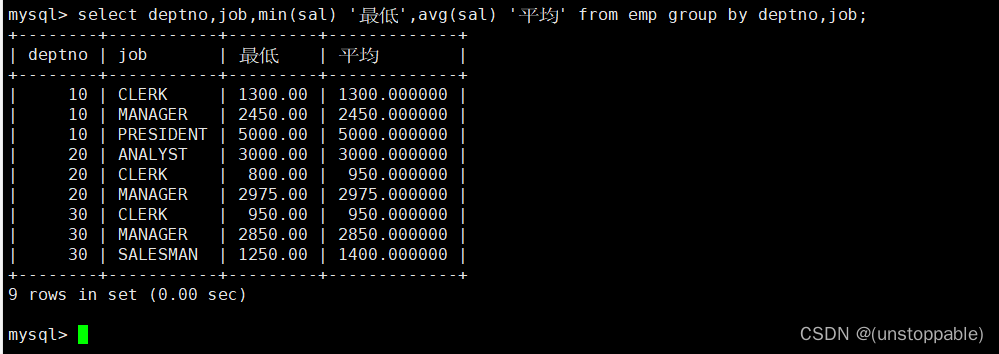
显示平均工资低于2000的部门和它的平均工资
首先统计各个部门的平均工资:
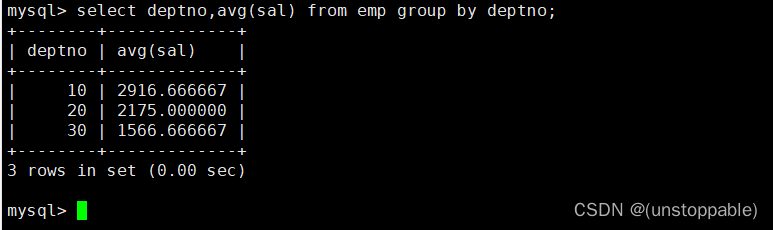
最后having和group by配合使用,对group by结果进行过滤
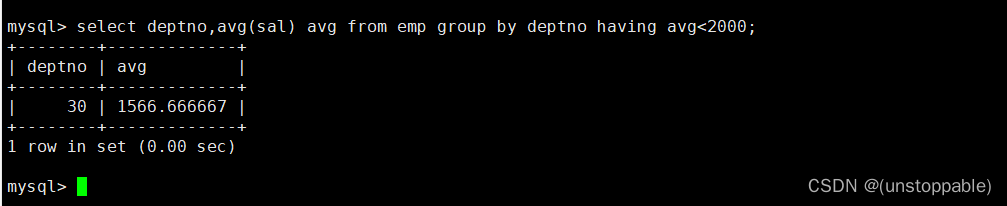
having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
having和where的区别理解?
1.执行顺序的理解
2.对结果的理解
3.where无法替换having
1.执行顺序的理解:
显示每个部门平均工资低于2000的岗位,但是不要把SMITH这个人计算在其中
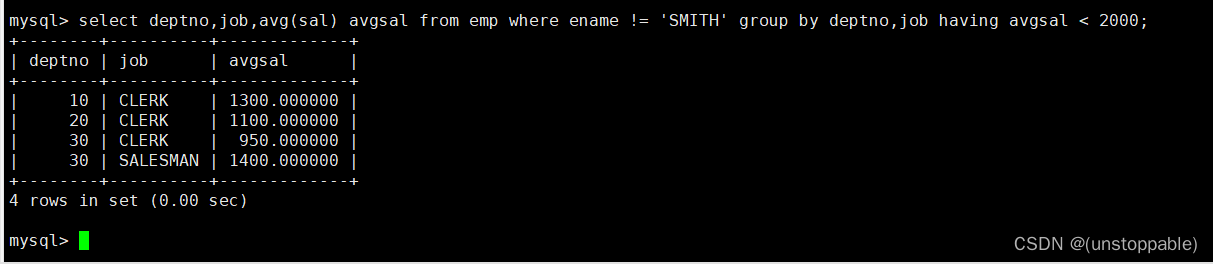

2.对结果的理解
where:对具体任意列进行条件筛选
having:对聚合之后的结果进行条件筛选
having和where条件筛选的阶段是不同的!
不要单纯的认为,只有磁盘上表的结果导入到mysql中、真实存在的表才叫做表。
中间筛选出来的、包括最终结果,其实全部都是逻辑上的表!
'‘MySQL’'一切皆表,未来只要我们能处理单表的CURD,多有SQL场景下的表,我们全部都能用统一方式进行。