🚩🚩🚩Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在PyCharm中进行
本篇文章配套的代码资源已经上传
从零构建属于自己的GPT系列1:数据预处理
从零构建属于自己的GPT系列2:模型训练1
从零构建属于自己的GPT系列3:模型训练2
从零构建属于自己的GPT系列4:模型训练3
从零构建属于自己的GPT系列5:模型部署1
从零构建属于自己的GPT系列6:模型部署2
5 writer函数
writer()实际上相当于main函数,这里是依次整个任务的运行控制都在这里,前面的那些函数都是在这里进行调用
def writer():
st.markdown( """ ### 杨卓越定制化GPT生成模型 """ )
st.sidebar.subheader("配置参数")
generate_max_len = st.sidebar.number_input("generate_max_len", min_value=0, max_value=512, value=32, step=1)
top_k = st.sidebar.slider("top_k", min_value=0, max_value=10, value=3, step=1)
top_p = st.sidebar.number_input("top_p", min_value=0.0, max_value=1.0, value=0.95, step=0.01)
temperature = st.sidebar.number_input("temperature", min_value=0.0, max_value=100.0, value=1.0, step=0.1)
- writer函数
- 这几行表示的是网页界面的标题,你可以自己更改成任意标题
- 在 Streamlit 应用程序的侧边栏中创建一个名为 “配置参数” 的子标题,通常用于告知用户这部分侧边栏包含了一些可以配置的参数或选项
- Streamlit 包的子功能,设置一个进度条,可以进行进度条的拖拽,用户可以自己设置生成文本最长的长度
- 创建了一个滑块,用于选择 top_k 的值
- 创建了一个数字输入框,用于设置 top_p 的值
- 创建了一个数字输入框用于调节 temperature 参数
这些参数通常用于控制文本生成过程,如控制生成文本的最大长度 (generate_max_len)、控制候选词汇的多样性 (top_k 和 top_p) 以及调节生成的随机性 (temperature)。通过这些控件,用户可以交互式地调整这些参数,从而影响模型的生成结果。
parser = argparse.ArgumentParser()
parser.add_argument('--generate_max_len', default=generate_max_len, type=int, help='生成标题的最大长度')
parser.add_argument('--top_k', default=top_k, type=float, help='解码时保留概率最高的多少个标记')
parser.add_argument('--top_p', default=top_p, type=float, help='解码时保留概率累加大于多少的标记')
parser.add_argument('--max_len', type=int, default=512, help='输入模型的最大长度,要比config中n_ctx小')
parser.add_argument('--temperature', type=float, default=temperature, help='输入模型的最大长度,要比config中n_ctx小')
args = parser.parse_args()
这些都是对应的上面那些进度条的命令行参数,先通过创建的命令行参数指定了有哪些参数,然后再经过那些进度条捕捉到命令行参数
context = st.text_area("主内容", max_chars=512)
title = st.text_area("副内容", max_chars=512)
if st.button("点我生成结果"):
start_message = st.empty()
start_message.write("自毁程序启动中请稍等 10.9.8.7 ...")
start_time = time.time()
result = predict_one_sample(model, tokenizer, device, args, title, context)
end_time = time.time()
start_message.write("生成完成,耗时{}s".format(end_time - start_time))
st.text_area("生成结果", value=result, key=None)
else:
st.stop()
- 输入的文本
- 输入的文本2,两者区别是可以输入两条而已,也可以只输入一条,不会在生成的结果中有区别对待,实际上会将两个输入文本连接到一起
- 一个网页界面的按钮,点击开始生成结果
- 先清空之前生成的所有内容
- 清空过程中,打印的一些内容
- 记录当前时间戳
- 通过前面的生成样本的函数得到生成的所有文本
- 记录结束时间戳
- 打印出生成的用时
- 展示生成结果
- 没有点击生成按钮
- 就停止运行程序
6 生成效果展示
6.1 生成过程解读
- 打开prompt,先切换到项目的盘
A:
- cd到项目地址
cd A:\GPT
- 切换到对应的python环境
activate pytorch
- 启动网页脚本
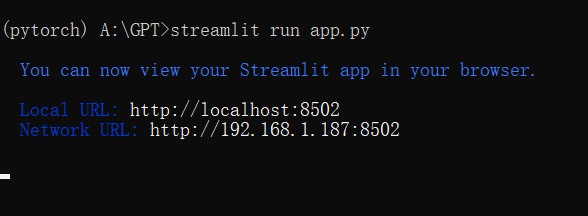
streamlit run app.py
- 没有异常的话,命令行会出现下面信息
- 弹出网页界面

- 输入文本,点击生成,得到生成结果

6.2 相关可手动调节参数解读
- generate_max_len:能够生成的文本的最大长度,最大可以设置成200
- top_k:对每一个生成词,可以有一些多样性
- top_p:累加概率的采样,累加概率值,设置的大一下生成的词多样性会大一些
- temperature:也是如此,调整多样性的
从零构建属于自己的GPT系列1:数据预处理
从零构建属于自己的GPT系列2:模型训练1
从零构建属于自己的GPT系列3:模型训练2
从零构建属于自己的GPT系列4:模型训练3
从零构建属于自己的GPT系列5:模型部署1
从零构建属于自己的GPT系列6:模型部署2