主要的编码规范:
GBK编码
Windows自带



Unicode编码



为什么会有乱码?
原因一

原因二

编码和解码的代码实现

字符流

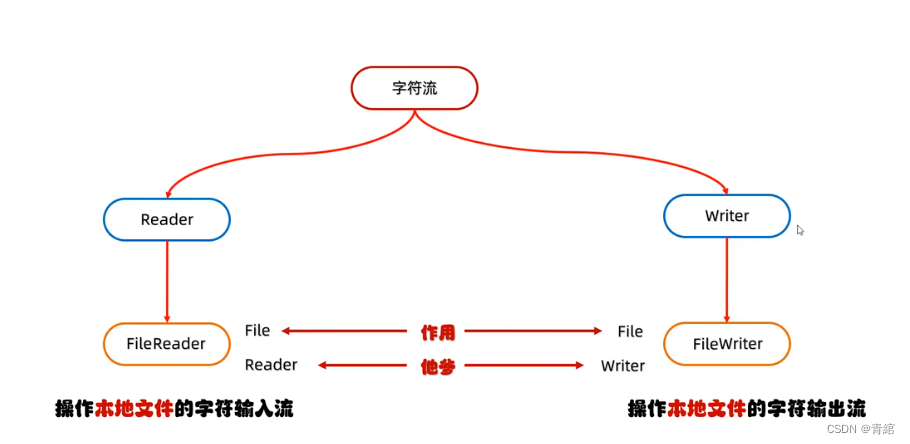
FileReader

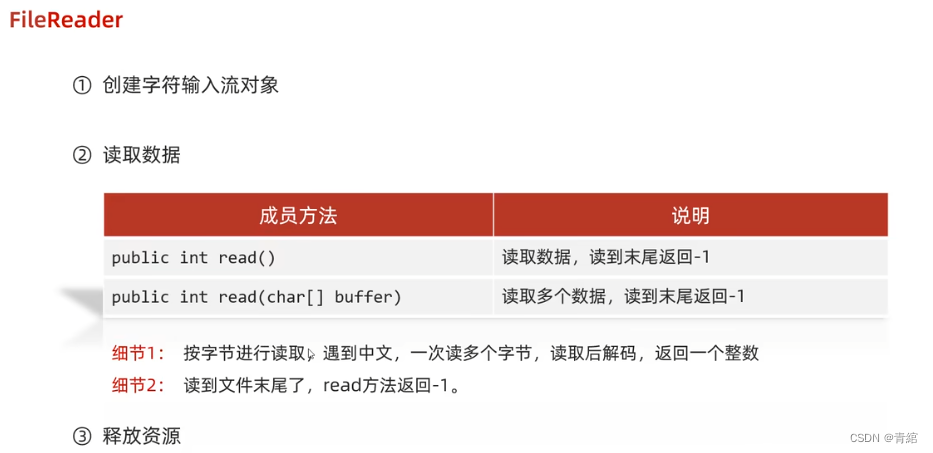

read()细节:
一:默认也是一个字节一个字节的读取,如果遇到中文就会一次读取多个
二:在读取之后,方法的底层还会进行解码并转成十进制
最终把这个十进制作为返回值
这个十进制的数据也表示在字符集上的数字
英文:文件里面二进制数据 0110 0001
read方法进行读取,解码并转成十进制97
中文:文件里面二进制数据 11100110 10110001 10001001
read方法进行读取,解码并转成十进制27721
想看到中文汉字,就是要把这些十进制数据,再进行char强转就可以了
read(chars):读取数据,解码,强转三步合并了,把强转之后的数据存放到数组当中
= 空参的read+强转
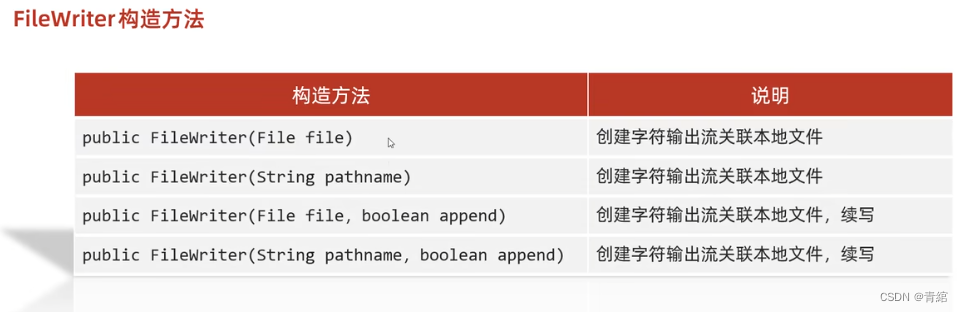
FileWriter
构造方法
成员方法

书写细节

原理解析
输入流
 输出流
输出流
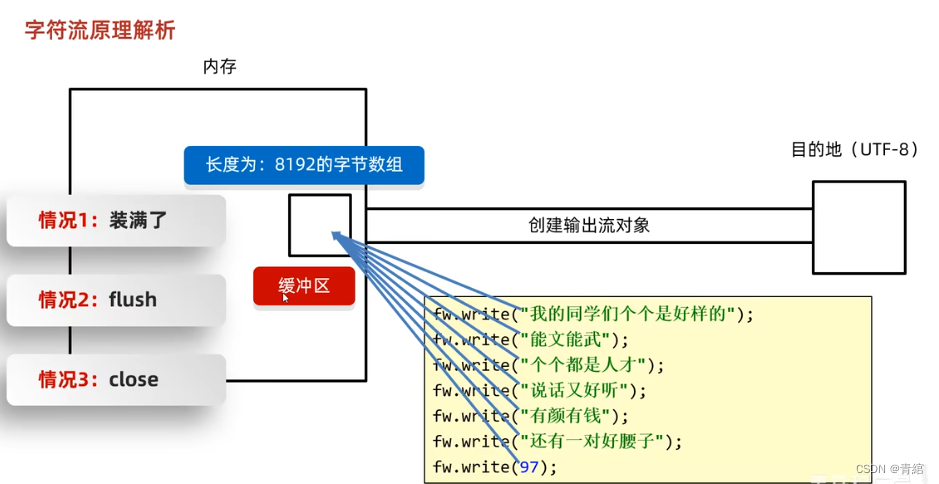
flush和close

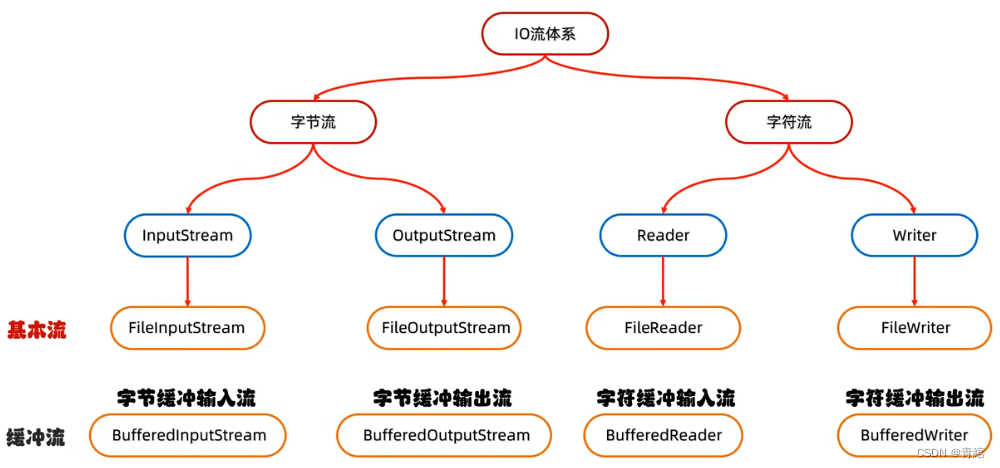
字节流和字符流的使用场景

缓冲流
字节缓冲流
构造方法

字符缓冲流
构造方法

特有方法

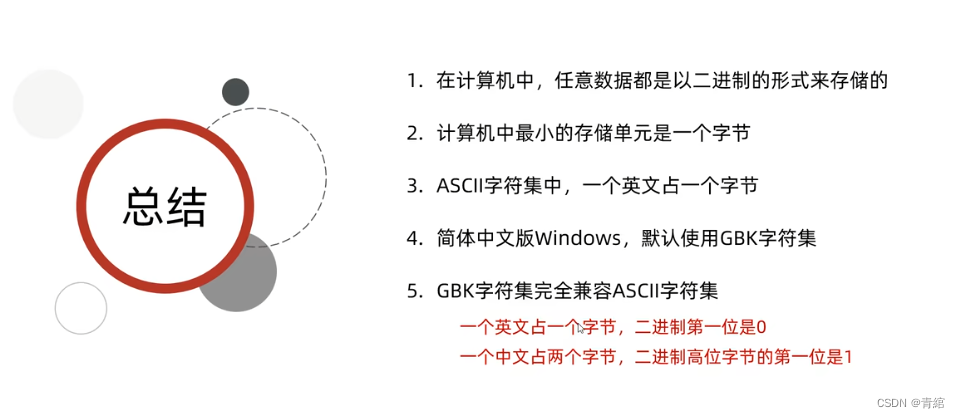
总结

![[香橙派]Orange pi zero 3命令行配网方法——建立ssh连接——Ubuntu配置WIFI自动连接](https://img-blog.csdnimg.cn/direct/166ea3849fb14a948ea511facbc774de.png)