1写在前面
估算前瞻性研究的样本量是我们在招募受试者之前首先要做的事情之一。😘
招募受试者太少会无法得到准确的答案,招募的太多又是巨大的浪费,所以需要估算最佳的受试者数量。🧐
本期我们介绍一下如何使用pwr包进行样本量的估算。😏
2用到的包
rm(list = ls())
library(pwr)
library(tidyverse)
3研究假设
假设我们准备进行一个RCT研究,研究Treatment A和Treatment B的疗效,结局事件为Response或No response的二分类结局。🤫
那我们现在就有了研究假设,
和
了:👇
: Treatment A和Treatment B间结局事件无差异。: Treatment A和Treatment B间结局事件有差异。
通常我们还有几个参数需要设置:👇
alpha level(通常为two-sided);effect size(h);power(通常为80%)
4计算样本量
这里我们需要用到pwr.2p.test函数,我们通常需要设置Treatment A和Treatment B的response比例,这个大家可以通过既往的文献来查找。😘
如果你做的研究非常新,在过去的文献中找不到的话,可以假设为50%。😂
这里我们假设Treatment A反应率是60%, Treatment B反应率是50%,这样Treatment A和Treatment B间的response比例就相差了10%,哈哈哈哈。😉
power1 <-pwr.2p.test(h = ES.h(p1 = 0.60, p2 = 0.50), sig.level = 0.05, power = .80)
power1
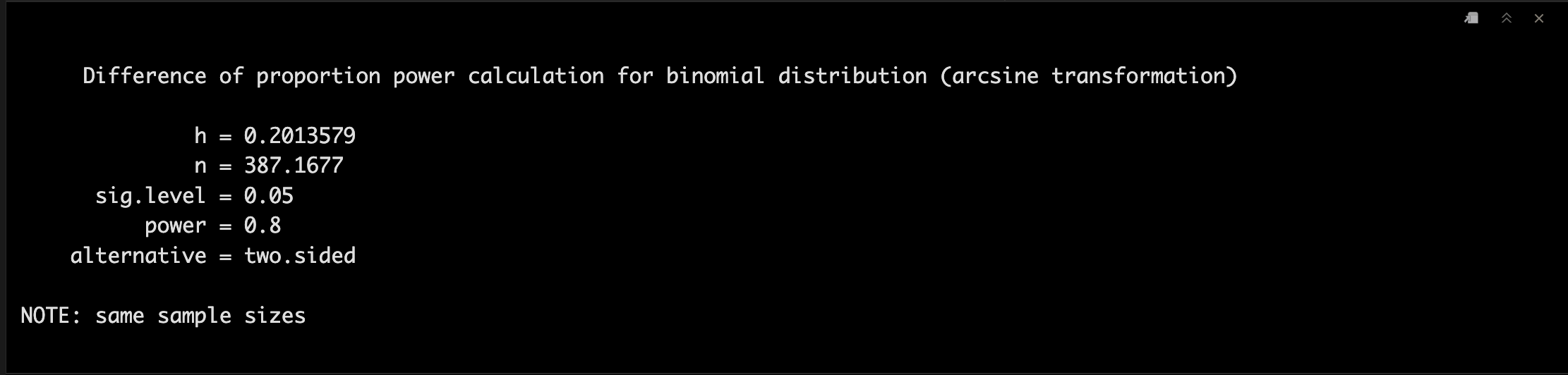
Note! 需要注意的是这里n只是一个组的数量,实际需要的总数量是需要double的。🤞
5Power Analysis
接着是效力分析(Power Analysis),主要是用来确定在指定显著性条件下所需要的样本量并评估该实验设计的统计效力。😗
通过Power Analysis,我们也能给出在现有的样本量下该实验结论的可靠性。🤩
如果结论的可靠性非常低,那么几乎可以认为实验是无效的,我们应该修改或者直接终止实验。🫠
plot(power1)
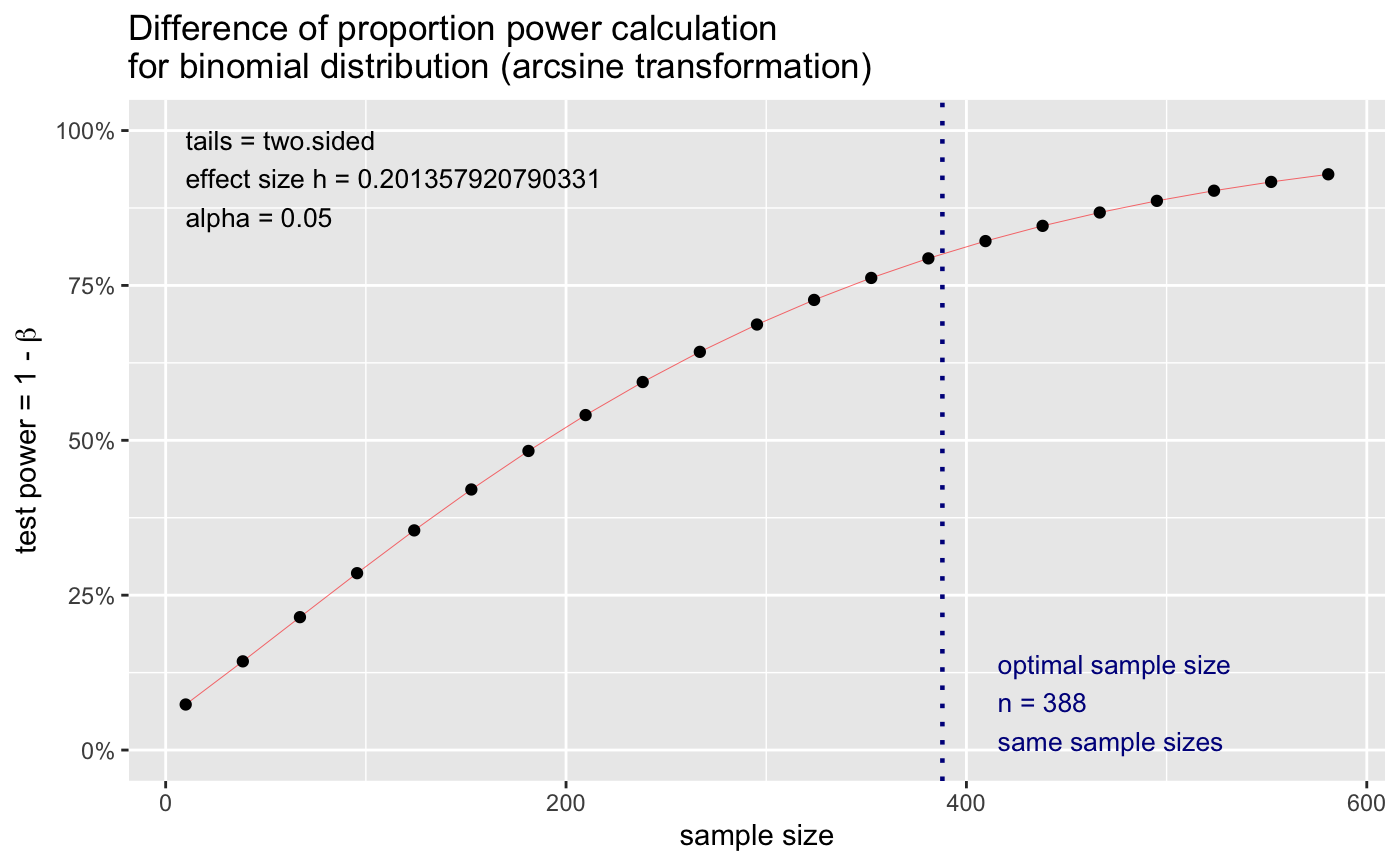
这里我们可以看到power随样本量增加的变化。🤓
6改变一下
这个时候我们改一下Treatment A反应率,并且将每组的样本量固定为388,α值为0.05。
p1 <- seq(0.5, 1.0, 0.05)
power1 <-pwr.2p.test(h = ES.h(p1 = p1, p2 = 0.50),
n = 388,
sig.level = 0.05)
power1
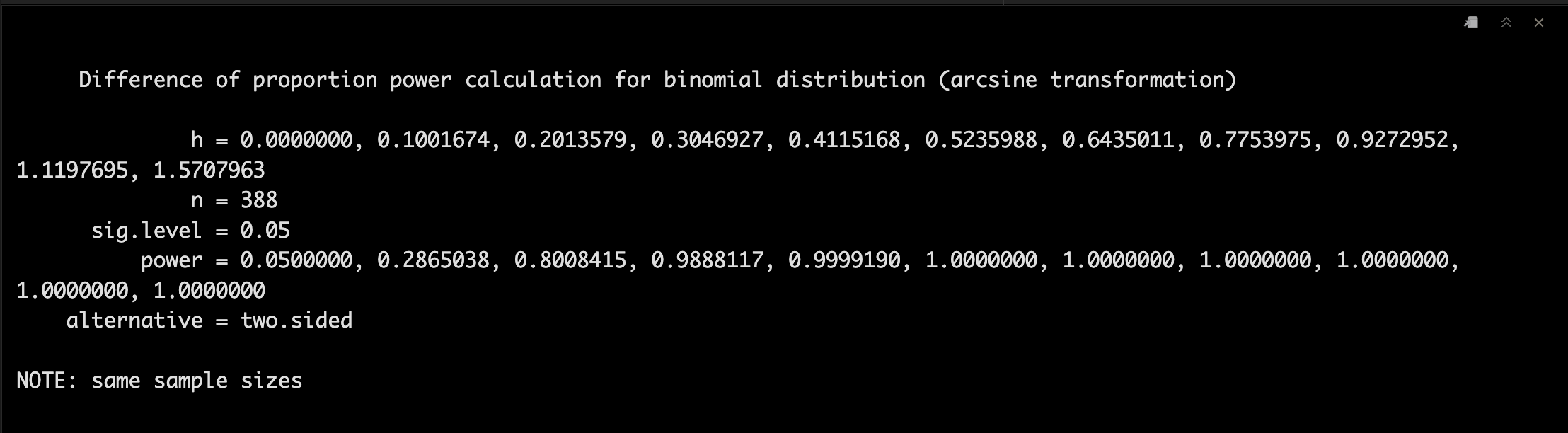
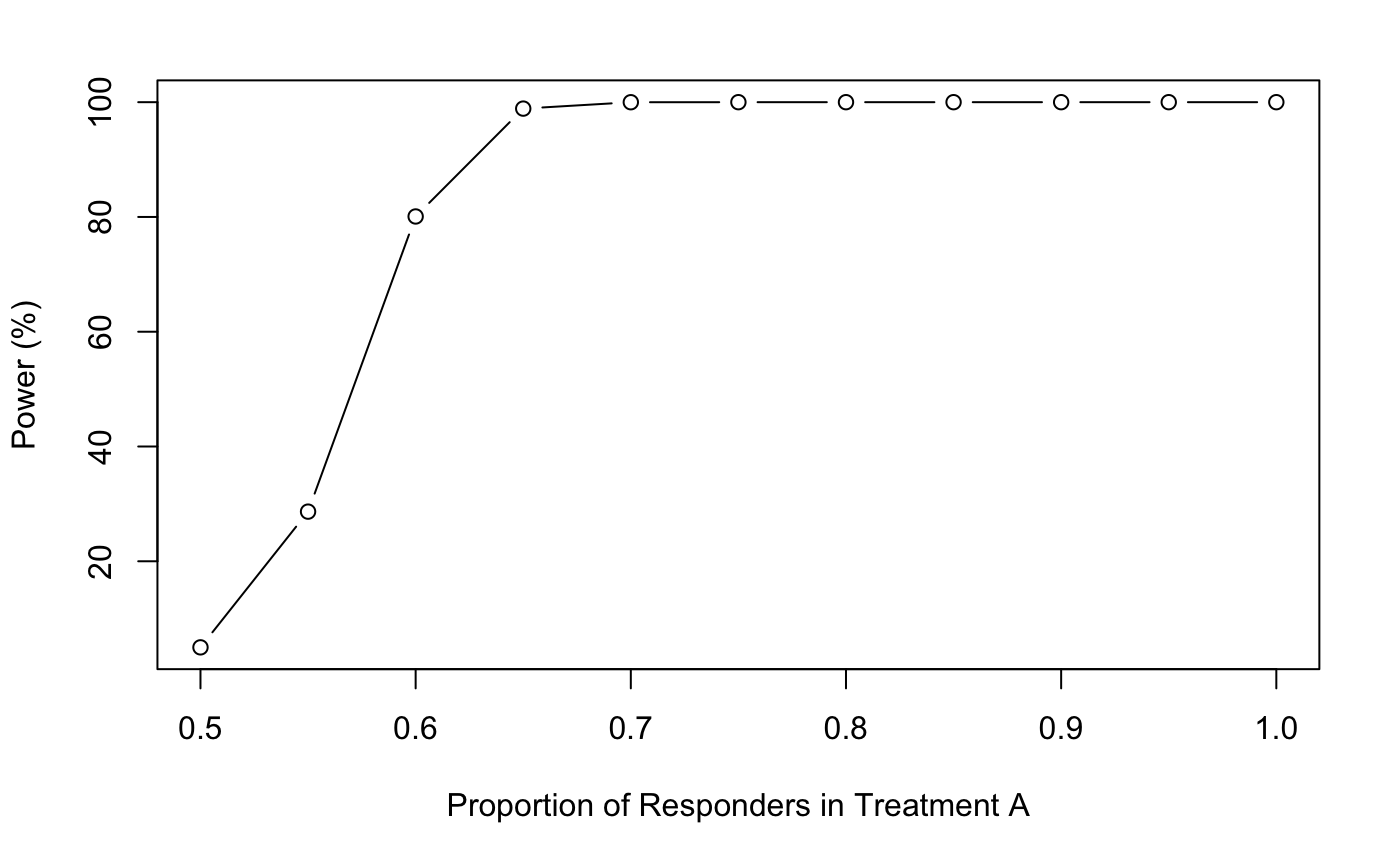
可视化一下可以看到Treatment A反应比例越高,和Treatment B差异越大,power就越大。😏
powerchange <- data.frame(p1, power = power1$power * 100)
plot(powerchange$p1,
powerchange$power,
type = "b",
xlab = "Proportion of Responders in Treatment A",
ylab = "Power (%)")

点个在看吧各位~ ✐.ɴɪᴄᴇ ᴅᴀʏ 〰
📍 🤩 ComplexHeatmap | 颜狗写的高颜值热图代码!
📍 🤥 ComplexHeatmap | 你的热图注释还挤在一起看不清吗!?
📍 🤨 Google | 谷歌翻译崩了我们怎么办!?(附完美解决方案)
📍 🤩 scRNA-seq | 吐血整理的单细胞入门教程
📍 🤣 NetworkD3 | 让我们一起画个动态的桑基图吧~
📍 🤩 RColorBrewer | 再多的配色也能轻松搞定!~
📍 🧐 rms | 批量完成你的线性回归
📍 🤩 CMplot | 完美复刻Nature上的曼哈顿图
📍 🤠 Network | 高颜值动态网络可视化工具
📍 🤗 boxjitter | 完美复刻Nature上的高颜值统计图
📍 🤫 linkET | 完美解决ggcor安装失败方案(附教程)
📍 ......
本文由 mdnice 多平台发布