1. 引言
前序博客:
- CUDA简介——基本概念
CPU是用于控制的。即,host控制整个程序流程:
- 1)程序以Host代码main函数开始,然后顺序执行。
- Host代码是顺序执行的,并执行在CPU之上。
- Host代码会负责Launch kernel。
- 2)对于想转移给CPU执行的代码,称为Device代码,通过Launch kernel来实现:
- Device代码是并行执行的,并执行在GPU之上。
- kernel做为a grid运行在Device端。
- Device端程序会立即返回给Host。即,除非明确要求,Host并不会等待Device执行完成后才再执行后续Host代码。【因此,如需收集特定kernel launch Device程序的执行结果,需在host代码中创建明确的barrier,让main c函数等待kernel执行完成再继续执行后续代码。】

launch kernel时的语法规则为:
- 与常规C函数调用类似
- 需指定配置参数grid_size和block_size,二者均为dim3 CUDA数据结构,默认均为(1,1,1)。

launch kernel示例如:

从Host角度来看,实际更详细的程序流为:
- 1)程序以Host代码main函数开始,然后顺序执行。
- Host代码是顺序执行的,并执行在CPU之上。
- 为kernel launch做准备【Host和Device内存是独立的】:Host与Device之间的数据拷贝至关重要,且是程序性能主要限制因素。
- 分配Device内存:
cudaMalloc(...)。 - 将Host上数据拷贝到Device上:
cudaMemcpy(...),即将数据由CPU拷贝到GPU之上。
- 分配Device内存:
- Host代码会负责Launch kernel:在GPU上并行执行Threads。
- 为获取kernel执行结果,需将Device数据拷贝到Host上:
cudaMemcpy(...)。

其中,Device内存管理:
-
与C中内存管理类似:C中内存分配用
malloc(...),内存释放用free(...)。

-
CUDA Device内存管理为:
- 内存分配用
cudaMalloc(LOCATION, SIZE):- LOCATION:Device上分配内存的内存位置,为某GPU内存地址。
- size:为分配的字节数。
- 内存释放用
cudaFree()。

- 内存分配用
Device和Host之间数据拷贝:
- 使用
cudaMemcpy(dst, src, numBytes, direction):- dst:拷贝目标地址
- src:拷贝源地址
- numBytes:拷贝字节数。numBytes = N*sizeof(type)
- direction:拷贝方向。
- cudaMemcpyHostToDevice:由Host拷贝数据到Device。
- cudaMemcpyDeviceToHost:由Device拷贝数据到Host。
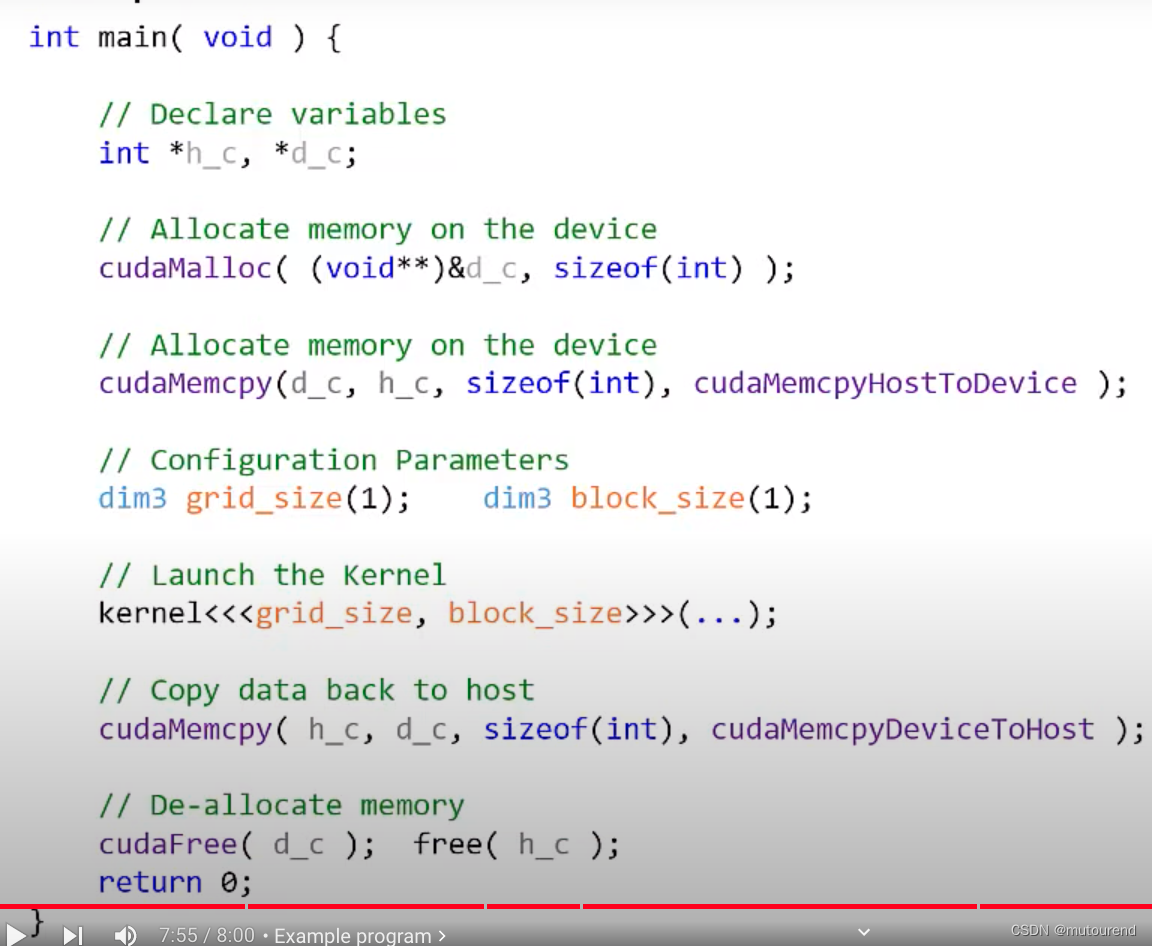
总体的完整流程为:
- 1)以main()函数起始
- 2)定义变量:通常以
h_来表示Host端变量,以d_来表示Device端变量。若在Host端引用了device变量,则程序将崩溃,反之亦然。

- 3)分配device内存:使用
cudaMalloc(...)。

- 4)将host数据拷贝到device:使用
cudaMemcpy(...)。【此时假设h_c为已做数据初始化】

- 5)设置kernel launch配置参数:grid_size和block_size。【下图中均为默认值(1,1,1)】

- 6)Launch kernel:

- 7)将device执行结果拷贝回host:使用
cudaMemcpy(...)。

- 8)释放device和host内存:分别使用
cudaFree(...)和free(...)。

- 9)结束main()函数执行。
参考资料
[1] 2019年5月视频 Intro to CUDA (part 2): Programming Model


![随机链表的复制[中等]](https://img-blog.csdnimg.cn/direct/cf962e1010e24cc7a54fcefb73c99443.png)