PyTorch学习笔记 7.TextCNN文本分类
- 一、模型结构
- 二、文本分词与编码
- 1. 分词与编码器
- 2. 数据加载器
- 二、模型定义
- 1. 卷积层
- 2. 池化层
- 3. 全连接层
- 三、训练过程
- 四、测试过程
- 五、预测过程
一、模型结构

2014年,Yoon Kim针对CNN的输入层做了一些变形,提出了文本分类模型textCNN。与传统图像的CNN网络相比, textCNN 在网络结构上没有任何变化,包含只有一层卷积,一层最大池化层, 最后将输出外接softmax 来进行n分类。
模型结构:
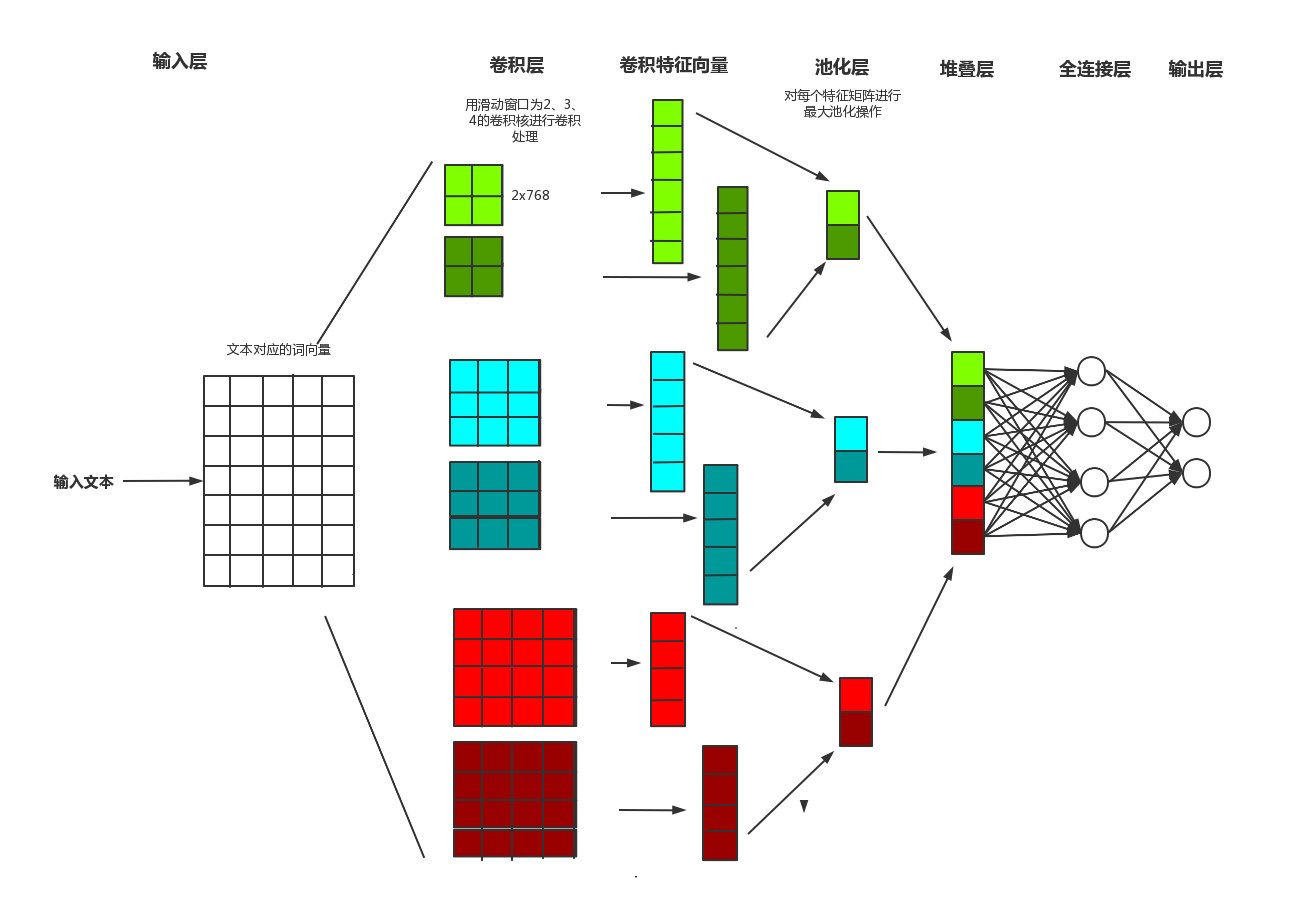
本文使用的数据集是 THUCNews 。
二、文本分词与编码
1. 分词与编码器
这里使用bert的预训练模型 bert-base-chinese 实现tokenizer过程。更多与bert分词编码相关知识可以移步到这里查看。
2. 数据加载器
数据加载器使用pytorch 的 dataset,关于DataSet更多知识可以移步到这里查看。
# 定义数据加载器
class Dataset(data.Dataset):
def __init__(self, data_path):
super().__init__()
self.lines = open(data_path, encoding='utf-8').readlines()
# 如果要指定缓存目录,可以使用 cache_dir='/kaggle/working/tokenizer'
self.tokenizer = BertTokenizer.from_pretrained(BERT_TOKENIZER_MODEL)
def __len__(self):
return len(self.lines)
# 取每条数据进行编码
def __getitem__(self, index):
text, label = self.lines[index].split('\t')
tokenizer = self.tokenizer(text)
input_ids = tokenizer['input_ids']
attention_mask = tokenizer['attention_mask']
# input_ids 和 attention_mask补全
if len(input_ids) < TEXT_LEN:
pad_len = (TEXT_LEN - len(input_ids))
input_ids += [BERT_PAD_ID] * pad_len
attention_mask += [0] * pad_len
target = int(label)
return torch.tensor(input_ids[:TEXT_LEN]), torch.tensor(attention_mask[:TEXT_LEN]), torch.tensor(target)
二、模型定义
1. 卷积层
模型定义3个卷积层,卷积大小分别是2,3,4。
卷积激活函数使用relu。
2. 池化层
卷积后进行最大池化,池化是在2维上进行,池化后进行降维处理。
3. 全连接层
根据池化层的输出和分类类别数量,构建全连接层,再经过softmax,得到最终的分类结果。
这里使用torch.nn.Linear(input_num, num_class)定义全连接层,其中input_num是池化层输出的维数,即m,num_class是分类任务的类别数量。
def conv_and_pool(conv, input):
out = conv(input)
# 第一次out.shape=[2,256,29,1]
out = F.relu(out)
# 池化在2维上进行,out.shape是范围大小,最后进行降维
return F.max_pool2d(out, (out.shape[2], out.shape[3])).squeeze()
class TextCNN(nn.Module):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained(BERT_TOKENIZER_MODEL)
# 固定bert的参数,只训练下游参数
for name, param in self.bert.named_parameters():
param.requires_grad = False
# 从1 变为 256个通道
# 这里定义3个层,卷积核大小分别是[2,3,4]
self.conv1 = nn.Conv2d(1, NUM_FILTERS, (2, EMBEDDING_DIM))
self.conv2 = nn.Conv2d(1, NUM_FILTERS, (3, EMBEDDING_DIM))
self.conv3 = nn.Conv2d(1, NUM_FILTERS, (4, EMBEDDING_DIM))
# 全连接
self.linear = nn.Linear(NUM_FILTERS * 3, NUM_CLASSES)
def forward(self, input, mask):
# self.bert 第0元素 [2,30,768]
# unsqueeze 进行升维,变成[2,1,30,768]
out = self.bert(input, mask)[0].unsqueeze(1)
# 第1层输出 [2,256]
# 在1维上拼接,输出[256,3],3个层上进行拼接
out1 = conv_and_pool(self.conv1, out)
out2 = conv_and_pool(self.conv2, out)
out3 = conv_and_pool(self.conv3, out)
out = torch.cat([out1, out2, out3], dim=1)
# 把3个层拼接,1个层是 out1 = self.conv_and_pool(self.conv1, out)
# 输出[2,10]
return self.linear(out)
三、训练过程
按批次取训练数据,调用模型进行训练,主要是以下几个步骤:
- 获取loss:输入数据和标签,计算得到预测值,计算损失函数;
- optimizer.zero_grad() 清空梯度;
- loss.backward() 反向传播,计算当前梯度;
- optimizer.step() 根据梯度更新网络参数
for batch, (input, mask, target) in enumerate(train_loader):
input = input.to(DEVICE)
mask = mask.to(DEVICE)
target = target.to(DEVICE)
# 预测,形状10*10
pred = model(input, mask)
loss = loss_fn(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
四、测试过程
测试过程对每次正确率累加,最后打印整体的测试结果:
def test():
test_dataset = Dataset(TEST_SAMPLE_PATH)
test_loader = data.DataLoader(test_dataset, batch_size=100, shuffle=False)
loss_fn = nn.CrossEntropyLoss()
y_pred = []
y_true = []
with torch.no_grad():
for batch, (input, mask, target) in enumerate(test_loader):
input = input.to(DEVICE)
mask = mask.to(DEVICE)
target = target.to(DEVICE)
test_pred = model(input, mask)
loss = loss_fn(test_pred, target)
print('>> batch:', batch, 'loss:', round(loss.item(), 5))
test_pred_ = torch.argmax(test_pred, dim=1)
# 计算整体正确率
y_pred += test_pred_.data.tolist()
y_true += target.data.tolist()
# 打印整体的测试指标
print(evaluate(y_pred, y_true, id2labels))
五、预测过程
- 把输入文本进行分词编码
- 输入模型,通过argmax计算预测值
- 通过id转标签函数计算标签值
def predict(texts):
# 分词
tokenizer = BertTokenizer.from_pretrained(BERT_TOKENIZER_MODEL)
batch_input_ids = []
batch_mask = []
start = time.time()
for text in texts:
tokenizers = tokenizer(text)
input_ids = tokenizers['input_ids']
attention_masks = tokenizers['attention_mask']
if len(input_ids) < TEXT_LEN:
pad_len = (TEXT_LEN - len(input_ids))
input_ids += [BERT_PAD_ID] * pad_len
attention_masks += [0] * pad_len
batch_input_ids.append(input_ids[:TEXT_LEN])
batch_mask.append(attention_masks[:TEXT_LEN])
batch_input_ids = torch.tensor(batch_input_ids)
batch_mask = torch.tensor(batch_mask)
pred = model(batch_input_ids.to(DEVICE), batch_mask.to(DEVICE))
pred_ = torch.argmax(pred, dim=1)
ret = ([id2labels[index] for index in pred_])
end = time.time()
runTime = end - start
print("共", len(texts), '条数据,运行时间:', runTime, '秒,平均每条时间', runTime / len(texts), '秒')
return ret