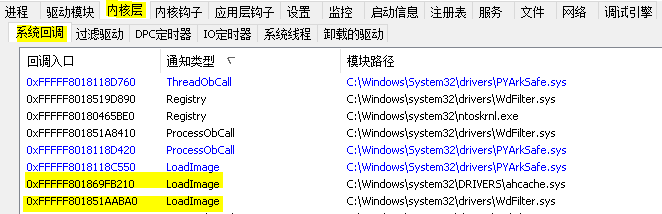
今天回顾一下 5~12 月所遇到的零碎知识点。
文章目录
- 歪门邪道
- 优雅删除“学习资料”
- 快速下载 vscode
- 两种硬盘格式
- zotero在word中插入参考文献
- markdown 下划线
- 查看 CPU Linux 命令
- postgres 无法通过 root 用户操作
- bash 初学者礼包
- git
- win 11 edge 浏览器0x80190001 报错
- python 强化
- python 中的省略号
- 捕获 warning 输出日志
- CPU 资源不够
- 安全创建目录
- sys.argv
- argparse
- wandb
- pip 源更换
- 无损迁移 conda 环境
- 关于matplotlib legend的一些参数
- 极坐标系下的等高热力图
- seaborn set 参数
- matplotlib 保存图片防止截断
- conda 初始化
- conda 安装小窍门
- cudnn 下载
- 安装 pytorch
- cuda 和 cudnn 联系和区别
- npz 文件
- numpy 向量补充知识
- 查看模型参数
- tensorboard 小知识
- torch_scatter.scatter()的使用方法
- cycle_momentum 报错 (一些废话)
- 模型跑崩的表现 (一些废话)
- python 路径搜索相关知识
- seed(42)
- EMA
- segmentation error
- dataloader 报错
- pytorch lightning 单机多卡报错
- Latex
- 超大写
- 抽象字体
- 领域知识
- ase.db
- 贝塞尔函数可视化方法
- 格式转换
- 熵
歪门邪道
那些不知道什么时候能再次用上,但确实好用的知识点
优雅删除“学习资料”
月黑风高,当你进入“贤者时间”后,如何删除“学习资料”以消灭作案证据?
简单使用 delete 会将文件移至回收站,需要手动再次清空回收站才能彻底删除,存在一定风险。优雅的老贼则常常采用 shift + delete 的方式一劳永逸。这种方式更适用于批量删除大量小文件,效率高。
(见 https://www.knowbaike.com/it/14929.html )
快速下载 vscode
复制下载链接后,修改服务器地址至国内源即可
https://blog.csdn.net/weixin_46621570/article/details/128007351
两种硬盘格式
修复移动硬盘报错的时候遇到了GPT和MBR两种硬盘格式
https://www.disktool.cn/content-center/difference-between-mbr-and-gpt-1016.html
https://www.knowbaike.com/it/26421.html
省流版:GPT方式更加先进,是MBR迭代后的产物
性能区别:
MBR分区表最多只能识别2TB左右的空间,大于2TB的容量将无法识别从而导致硬盘空间浪费,而GPT分区表则能够识别2TB以上的硬盘空间。
zotero在word中插入参考文献
正确的插入格式:
https://zhuanlan.zhihu.com/p/570641329
注意到,zotero默认的添加文献的方式(在网页PDF上直接点收藏)容易漏时间,出版号等关键信息,最完备的方式是去到文献刊发的网站,找其对应的 bibtex,然后再添加
https://blog.csdn.net/aiboom/article/details/128651501
https://blog.csdn.net/aiboom/article/details/128651501
markdown 下划线
https://www.zhihu.com/question/28375977
markdown 并无原生的下划线语法,可使用斜体替代
查看 CPU Linux 命令
https://zhuanlan.zhihu.com/p/372564248
查看物理 CPU,每个 CPU 的核数
查看逻辑 CPU(线程数)
postgres 无法通过 root 用户操作
https://blog.csdn.net/li_101357/article/details/69367457
Linux 创建新用户
postgres 等数据库不能在 root 用户下操作
https://zhuanlan.zhihu.com/p/205217949
创建新用户后shell无法自动补全命令或使用基本的shell命令
使用root用户查看passwd文件,可以发现默认的shell 是/bin/sh,将其修改为/bin/bash 后即可
su postgres -c “echo $original_user > new.txt”
使用 su 切换用户
使用 -c 在切换用户之后执行一条命令
两个引号将将要执行的命令裹起来
感谢llm

bash 初学者礼包
如果你是 bash 初学者,发现网上的简单 bash 脚本均无法运行,此时你需要检查测试文件是否是 unix 文件
修改文件为 unix 文件的命令:
https://blog.csdn.net/HYZX_9987/article/details/120061672
‘.sh’文件是如何运行的
https://baijiahao.baidu.com/s?id=1773849793111298095&wfr=spider&for=pc
${} 是如何运行的
https://blog.csdn.net/qq_25518029/article/details/119564512
bash和shell的区别
https://blog.csdn.net/qq_28284627/article/details/124509159
bash语言中的 if else 语句
https://zhuanlan.zhihu.com/p/649417352
冷知识:
在Linux 和 UNIX系统里可以使用多种不同的shell可以使用。最常用的几种是 Bourne shell (sh), C shell (csh), 和 Korn shell (ksh)。
Bourne Again shell ( bash), 正如它的名字所暗示的,是 Bourne shell 的扩展。
https://blog.csdn.net/wenlifu71022/article/details/4069929
git
懒人用 git desktop
但 github desktop 不能指定分支clone
这个问题似乎并没有解决方案
最后是使用命令行的git clone加上-b参数,克隆指定分支,然后打开github desktop添加local仓库
另外,github在和私人仓库进行交互时,有可能会弹出账户密码的对话框。对此,一定要检查,自己想要clone的仓库的地址,注意要去掉特定分支后缀(为此折腾了快一小时)
使用代理 https://ghproxy.com/ 加速 github clone 的速度
注意,第一次使用命令行 git 时需要配置链接秘钥。
https://blog.csdn.net/qq_35206244/article/details/97698815
如果是私密仓库,需要配置一个 personal token
https://github.com/settings/tokens
修改远程仓库地址
git remote set-url origin URL
https://blog.csdn.net/yihanzhi/article/details/78801027
win 11 edge 浏览器0x80190001 报错
https://zhuanlan.zhihu.com/p/632718025
使用 Fiddler 解决win11 edge 登录时报错08x…1的问题
注意,这个fiddler似乎只会捕捉一次报错,每次输完密码,点击继续等等之后,fiddler页面会出现一个 error 的 banner,在报错前即时点一下这个banner就可以了
python 强化
python 中的省略号
https://zhuanlan.zhihu.com/p/489862322
省略号在 Python 中的应用:
- 类型提示。
- 相当于 pass。
- numpy 中做索引
捕获 warning 输出日志
使用 contextlib.redirect_stdout 或 contextlib.redirect_stderr 能够捕获异常和输出,并将其输出至指定位置
https://stackoverflow.com/questions/22822267/how-to-capture-print-output-of-another-module
CPU 资源不够
The paging file is too small for this operation to complete. Error loading “C:\Users\16608\AppData\Roaming\Python\Python310\site-packages\torch\lib\cufft64_10.dll” or one of its dependencies.
网络太大,限制num_workers=1即可
num_workers 指 cpu 并行处理数据的线程数,num_workers 设置过大会占用过多 CPU 资源。因此,限制num_workers=1可以大幅减轻 CPU 压力
上述报错是 CPU 资源不够,GPU 资源不够一般是 memory, cuda 报错

安全创建目录
https://zhuanlan.zhihu.com/p/317254621
使用 pathlib 安全的创建目录
mkdir(parents=True, exist_ok=True)
sys.argv
https://blog.csdn.net/fancynthia/article/details/126271660
Python 中 sys.argv 用法详解
sys.argv[]是一个列表
sys.argv[0]是被调用的脚本文件名或全路径
sys.argv[1:]之后的元素就是我们从程序外部输入的,而非代码本身的,想要看到它的效果,就要将程序保存,从外部运行程序并给参数,这也是我们在cmd里面运行的原因。
argparse
用来做简易接口
https://blog.csdn.net/feichangyanse/article/details/128559542
metavar 和 action 在 argparse 中的含义
https://blog.csdn.net/FelixHe_FelixHe/article/details/130498476
https://stackoverflow.com/questions/19124304/what-does-metavar-and-action-mean-in-argparse-in-python
parser.add_argument 中 nargs 用法
nargs=N,一个选项后可以跟多个参数(action='append’时,依然是一个选项后跟一个参数,只不过选项可以多次出现),参数的个数必须为N的值,这些参数会生成一个列表,当nargs=1时,会生成一个长度为1的列表。
nargs=?,如果没有在命令行中出现对应的项,则给对应的项赋值为default。特殊的是,对于可选项,如果命令行中出现了此可选项,但是之后没有跟随赋值参数,则此时给此可选项并不是赋值default的值,而是赋值const的值。
nargs=*,和N类似,但是没有规定列表长度。
nargs=+,和*类似,但是给对应的项当没有传入参数时,会报错error: too few arguments。
wandb
https://zhuanlan.zhihu.com/p/493093033
wandb
weights and biases
是用来存模型参数、记录实验参数的工具,还能输出视频,GIF 图片等
类似tensorboard,但没有 tensorboard 用起来方便
https://blog.csdn.net/qq_42312574/article/details/132662921
wandb offline 模式 sync
https://zhuanlan.zhihu.com/p/493093033
wandb 基本用法
pip 源更换
我们常常使用 pip 源去加速软件包的安装。有时,pip 源网址本身可能会发生更换,比如半年前,我在使用西交源的时候就遇到了更换:
从原先的: https://mirrors.xjtu.edu.cn/pypi/simple
更换为了:https://mirrors.xjtu.edu.cn/pypi/web/simple
学到的知识点是:
源更换不可怕,因为一般源作者会在原来的地方留下新源的信息。就好比饭店搬迁,会在原址留下新饭店的位置。我们可以登录源网址查看变更信息。一般来说,不会整个源丢掉,大概率是换了链接,耐心一点总能找到。
无损迁移 conda 环境
如果你想要无损搬迁自己的conda环境,不妨了解一下 pip freeze
https://blog.csdn.net/qq_44886601/article/details/129933666
关于matplotlib legend的一些参数
columnspacing, labelspacing, handletextpad, borderpad
这几个参数指定了 legend 中的一些细节
ncols 可以指定 legend 有几列
在 matplotlib < 3.6 版本中,这一参数叫 ncol
在 matplotlib >= 3.6 版本中,这一参数叫 ncols

https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.legend.html
极坐标系下的等高热力图
https://www.youtube.com/watch?v=DyPjsj6azY4&ab_channel=HagesLab
contour 是 绘制等高线的函数
contourf 是 填充等高线间的空隙的函数
contour中的linewidth调节成None即可获得光滑过度的热力图
ax.set_rticks([])
ax.set_xticks([])
去掉等高线和刻度的正确方法
https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.contourf.html#matplotlib.axes.Axes.contourf
seaborn set 参数
https://www.statology.org/seaborn-title/
seaborn 绘图中使用 set 设置标题和 xlabel, ylabel 等
matplotlib 保存图片防止截断
在 savefig 中使用 bbox_inches=‘tight’ 可以解决
https://stackoverflow.com/questions/35992492/savefig-cuts-off-title
conda 初始化
win下初始化conda环境,是使用conda可执行文件,地址在script目录下
https://blog.csdn.net/u010984516/article/details/125517492
在新进入镜像时,一般来说,是没有一个conda shell环境的
此时需要用命令 conda init bash 来初始化一个环境(不是 conda init )
初始完后再次进入该镜像即有初始的 conda 环境
conda 安装小窍门
conda install -y -c conda-forge rdkit==2021.09.5
-y 指 Sets any confirmation values to ‘yes’ automatically. Users will not be asked to confirm any adding, deleting, backups, etc.
-c 是选择安装的源
cudnn 下载
更换国内源加速下载(com改成cn即可):
https://blog.csdn.net/HunterMiki/article/details/122738632
安装 pytorch
我们可以使用 -i & -f 两个参数指定下载源,虽然有博客认为,使用 -f 会影响下载速度
https://blog.csdn.net/WannaSeaU/article/details/102830613
但我这边实测没有感受到。反而,二者同时用可以避免“镜像源配置错误”的问题。
也有博客认为二者同时使用比较好
https://blog.csdn.net/uflexnihao/article/details/113244103
我这边无痛安装 cu117 版本的 pytorch 以及一些附属的库:
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1 -f https://download.pytorch.org/whl/cu117/torch_stable.html
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch_geometric torch_scatter torch_sparse torch_cluster torch_spline_conv -f https://data.pyg.org/whl/torch-2.0.0+cu117.html
注意:-i 和 --trusted-host 放在包前面较为合适, -f 是在指定链接里去找想要的包
requirements.txt 里的空行会先对空行前的包build dependency,然后再接着安装剩余的包
requirements编写时考虑CPU和GPU的不同
https://stackoverflow.com/questions/72720235/requirements-txt-for-pytorch-for-both-cpu-and-gpu-platforms
苹果用户:
http://www.360doc.com/content/23/0701/13/54508727_1086924383.shtml
如果机器是cuda版本,需要先在conda里安装cuda和cudann
https://blog.csdn.net/qq_43705697/article/details/121618276
最后,安装完cuda可能检测不到
https://blog.csdn.net/weixin_43301333/article/details/128911561
cuda 和 cudnn 联系和区别
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。
https://www.jianshu.com/p/622f47f94784
更详细的工具的汇总可以参见:
https://blog.csdn.net/qq_42406643/article/details/109545766
npz 文件
split.npz 文件常用来存储训练集、验证集、测试集中每个样本在原数据集中的位置。
我们可以使用 np.load 载入该文件,并使用 test = info['test_idx'] 的方式查看文件内容
在存的时候,与 npy 不同的是,我们需要用 np.savez 函数
使用npz存字典时会遇到一个问题,在不知道字典的键值情况下,可以尝试将整个字典写到一个条目下,但在取数据时会遇到格式问题。
在解决上述问题时,无意间翻到了一个回答,答主指出,可以使用kwargs语法,在不知道键值的情况下将字典以键值对的形式写入
https://stackoverflow.com/questions/52996433/loading-dictionary-stored-as-npz-fails
numpy 向量补充知识
使用 type 查看类型,使用 ndim 查看维度,使用 shape 查看维度
(22, 0) 这样子是一维
round 相关知识
np.ndarray 类型数据在round以后,确实是变成了四舍五入的格式
但是输出的时候,如果不变成str,输出时小数点后好几位会有数字
如果变成了str,输出时会保留截取的形式
float形式的数据,round以后直接输出,会自动保持截取的形式
(这个事情还不好下定论,养成输出时加str的习惯是对的)
查看模型参数
num_params = sum(p.numel() for p in model.parameters())
print(f'#Params: {num_params}')
tensorboard 小知识
同时观察多个 event 文件
我们在主文件夹下建立多个子文件夹,每个子文件夹放入一个 event 文件,这样在 logdir=主文件夹 的时候会同时打开多个子文件夹中的 event,且曲线图中每条曲线的名字就是子文件夹的名字。
torch_scatter.scatter()的使用方法
scatter函数的作用就是将index中相同索引对应位置的src元素进行某种方式的操作,例如sum、mean等,然后将这些操作结果按照索引顺序进行拼接
https://blog.csdn.net/Cyril_KI/article/details/125908710
cycle_momentum 报错 (一些废话)
pytorch CyclicLR momentum 参数仅在优化器支持 momentum 的情况下有效
https://blog.csdn.net/weixin_43002433/article/details/104969477
模型跑崩的表现 (一些废话)
验证集和训练集均出现了nan值

python 路径搜索相关知识
Python import module 的搜索路径由sys.path指定,实质为一个列表,列表索引先后决定搜索优先级。
我们可以人为补充某些路径,从而可以直接索引
如下:
import sys
sys.path.append('.')
from sub_image.pyG_infer import leftnet_dpdispatcher
from sub_image.postgres import postgres_interaction
from sub_image.cgleftnet import cgleftnet_dpdispatcher
这样我们可以在不安装包的情况下将当前目录补充到包搜索列表中
该实例中 sub_image 是当前目录下一个文件夹,我们需要在该文件夹下填入一个 _init_ 文件才能将该文件夹转换成可以被搜索的模块(module)
下图是示例中提到的三个模块

seed(42)
np.random.seed(42) 的用法
https://stackoverflow.com/questions/21494489/what-does-numpy-random-seed0-do
If you set the np.random.seed(a_fixed_number) every time you call the numpy’s other random function, the result will be the same
EMA
https://testerhome.com/topics/10996
指数加权平均(EMA)稳定训练的原理:
EMA 可以让梯度下降更加稳定
segmentation error
指你的程序波及到了本该不属于它的范围
就好比,每个程序对应现实世界一个人,程序运行时,这个人的活动范围局限在特定的街区。如果程序因为特别的错误,比如除零等,导致其占用了过多的资源,以至于跑到了其他街区。此时会报错 segmentation error
segmentation 还用于种族隔离等语境。
python 中无法捕获因C子程序导致的 segmentation error (极难捕获)
遇到类似的问题只能想方设法解决造成 error 的原因,而不是做 try catch
dataloader 报错
raise RuntimeError(‘DataLoader worker (pid(s) {}) exited unexpectedly‘.format(pids_str))RuntimeErro
原因是程序运行需要在一个主程序下,把
if __name__ == "__main__":
添加到主程序目录下即可
pytorch lightning 单机多卡报错
跟slurm系统
RuntimeError: You set --ntasks=40 in your SLURM bash script, but this variable is not supported. HINT: Use --ntasks-per-node=40 instead.
网上也有很多讨论:
https://github.com/Lightning-AI/lightning/pull/16955/files
一般是让自己新建一个 slurm 脚本 & 修改任务名称
在提交任务的 command 里加上两句 unset 即可:
unset SLURM_NTASKS && unset SLURM_JOB_NAME && python train_homo_lumo_ddp.py > tmp_log 2>&1
Latex
超大写
经常阅读计算机系算法论文的同学可能会看到同一个单词里出现了大小不一的大写字母。
如下:

这种单词可以通过 latex (\textsc{} 或者 \scshape)超大写格式实现。U 是超大写,NIFIED 大写
此外,我们可以使用 \textsuperscript{} 实现上标,\textsubscript{} 实现下标
\textregistered 是带圆圈的R
抽象字体
读论文时,可能会遇到一些抽象的字体,例如Fraktur字体。这种字体常用于表示集合等,曾广泛应用于德国、东欧国家
https://en.wikipedia.org/wiki/Mathematical_Alphanumeric_Symbols
在latex里,使用 \mathfrak{} 可以轻松打出 Fraktur 字体
领域知识
ase.db
ase.db 有一个默认的 id 参数,该参数记录了当前条目在 db 中的位置,是创建 db 时自动赋值的,不能手动赋值
我们可以通过新建 id 名的方式手动赋值新的 id,比如,ep_id
ase.db select 时候不是一个atoms对象,往往需要根据某个 id 重新 select
一个相对优雅的方式是将 row 对象一步转成 atoms 对象
with connect('new.db') as db:
for a_row in db.select():
an_atoms = a_row.toatoms()
view(an_atoms)
数据库操作应该注意,删除一行,会造成数据库的不连续( id 的不连续)
可行(但有点笨拙)的方法是重新写一个数据库,跳过待删除行
贝塞尔函数可视化方法
https://www.youtube.com/watch?v=DyPjsj6azY4&ab_channel=HagesLab
make a 2D contour plot in Python in polar coordinates.
炫酷的贝塞尔函数可视化方法
格式转换
pyG object 和 ase object 的相互转换:
https://ulissigroup.cheme.cmu.edu/ml_catalysis_tutorials/notes/custom_datasets/data_preprocessing.html
lmdb 和 ase object 的相互转换:
https://ulissigroup.cheme.cmu.edu/ml_catalysis_tutorials/notes/custom_datasets/lmdb_dataset_creation.html
xyz 2 mol 的标准操作:
https://github.com/jensengroup/xyz2mol
熵
熵,交叉熵,KL散度公式与计算实例
https://finisky.github.io/2020/07/09/crossentropyloss/
相对熵=KL散度,描述了两个概率分布间的相对大小
如果两个分布完全相同,则相对熵为0
相对熵+目标函数本身的熵=交叉熵
由于目标函数本身的熵是固定的,因此在训练网络时,选择交叉熵作为损失函数与相对熵等同
https://finisky.github.io/2020/07/09/crossentropyloss/
nllloss,negative log likelihood loss 负对数似然损失函数,常用于分类问题中,是CrossEntropyLoss的其中一个吧步骤
NLLloss+log+softmax=CrossEntropyLoss
https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html
https://zhuanlan.zhihu.com/p/570118948
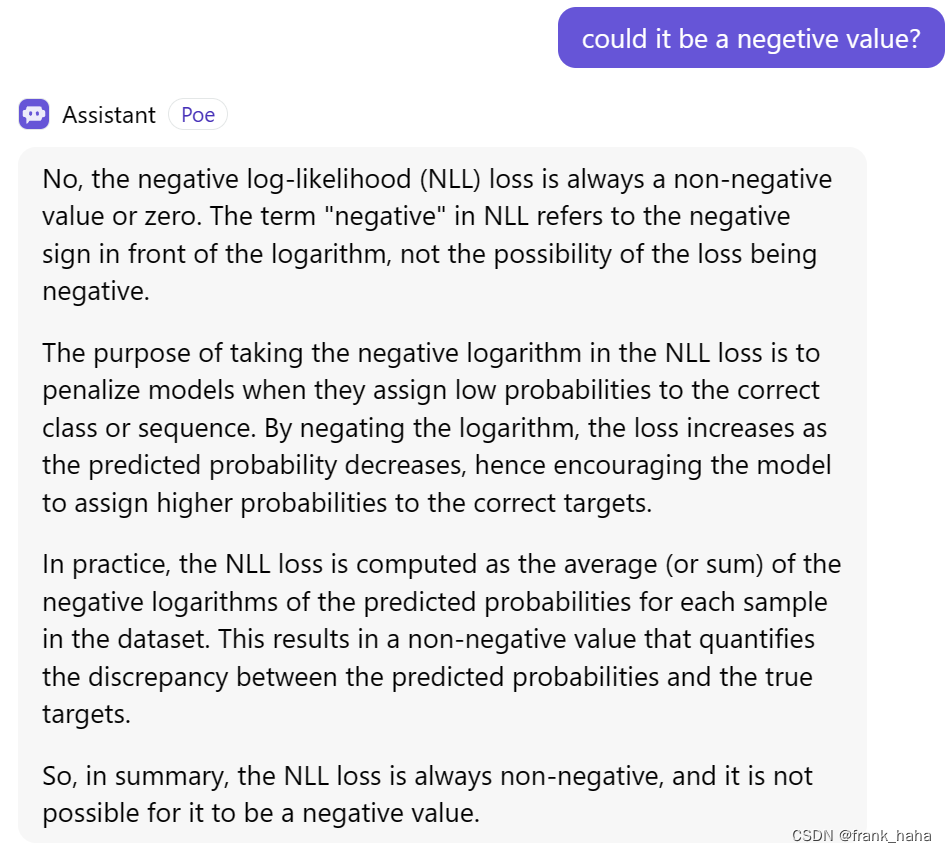
nll loss 本应该处于 0~1 之间,但前提是 predicted distribution 也处于 0~1 之间,即 normalize 过
如果没有 normalize 过,也可能会出现 nll loss 取负的现象,这些都是正常的行为