前言
基于PaddleOCR银行卡识别实现(一)
基于PaddleOCR银行卡识别实现(二)
前两篇文章讲了检测模型和识别模型的实现,这一篇文章姗姗来迟,将讲解下两个模型的串联应用和PaddleOCR的源码精简,下面我们来看看如何实现,文章最后有全源码下载。
一、PaddleOCR源码分析
1、源码下载
使用git进行下载:
git clone https://github.com/PaddlePaddle/PaddleOCR.git
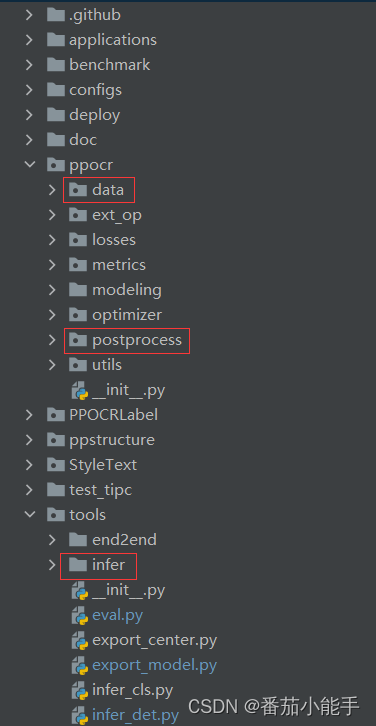
我们先找到下面三个路径,这三个路径中存放了预测的核心代码:
ppocr\data:存放数据预处理代码
ppocr\postprocess:存放数据后处理代码
tools\infer:存放加载模型和相关参数代码
然后,在这个三个目录中详细提取我们需要的代码
2、ppocr\data精简
根据predict_det.py文件,可以查看到,需要的数据预处理并不多
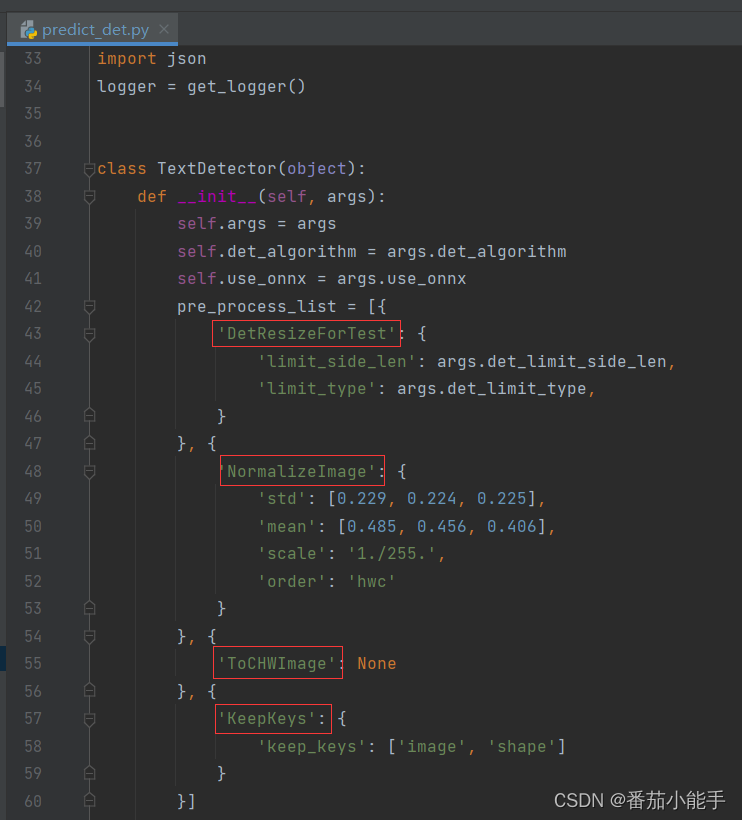
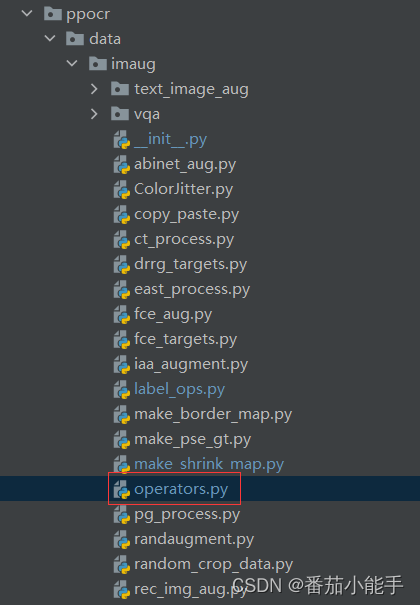
上面的几种方法都集中在一个py文件中,把operators.py中不相干的方法删掉就可以了:
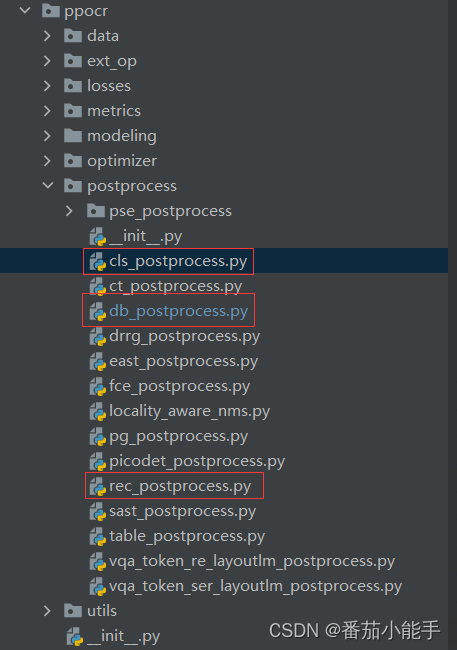
3、ppocr\postprecess精简
我们只需要保存这三个cls_postprocess.py、db_postprocess.py和rec_postprocess.py即可
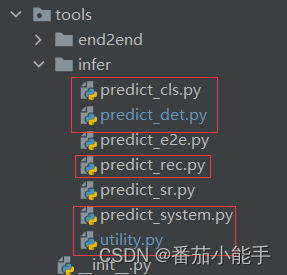
4、 tools\infer精简
仅保留红框的py文件即可,删除predict_e2e.py和predict_sr.py
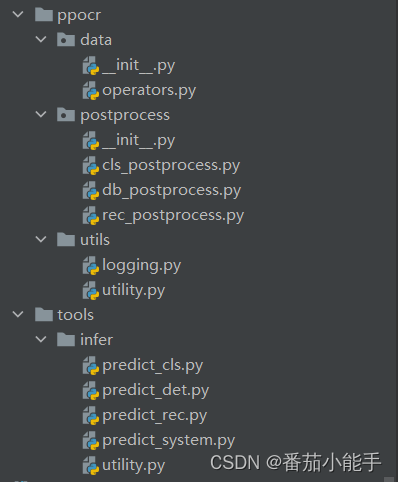
5、精简后的代码并预测
可以看到,文件非常少,以下代码就是PaddleOCR预测的核心代码
注意:需要修改__init__.py中的引用
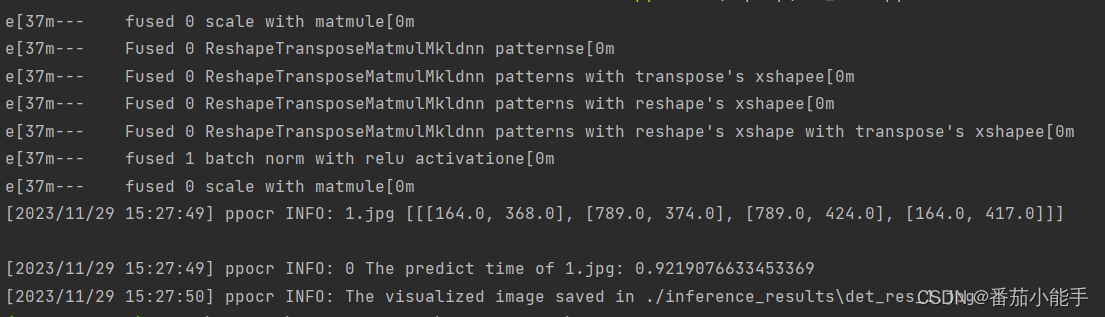
加上模型后就可以预测:
python tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./inference/det/" --image_dir="1.jpg" --use_gpu=False --det_db_unclip_ratio=2.5

二、银行卡卡号识别集成
1、添加预测代码
新建deploy目录,加入预测py文件

核心代码如下:
def predict(self, image=None, path="", **kwargs):
if image is not None:
predicted_data = image
elif path != "":
predicted_data = self.read_image(path)
else:
raise TypeError("The input data is inconsistent with expectations.")
dt_boxes, rec_res, _ = self.text_sys(predicted_data)
dt_num = len(dt_boxes)
if dt_num > 0:
rec_res_final = dict()
text, score = rec_res[0]
rec_res_final.update({
'bank_card_number': text,
'score': float(score),
'location': dt_boxes[0].astype(np.int).tolist()
})
url = "https://ccdcapi.alipay.com/validateAndCacheCardInfo.json?cardNo=" + rec_res_final[
"bank_card_number"] + "&cardBinCheck=true"
r = requests.get(url=url)
res = r.json()
if res["validated"]:
card_types = {
"DC": "借记卡",
"CC": "信用卡",
"SCC": "准贷记卡",
"PC": "预付费卡"
}
if res["cardType"] in card_types:
card_type = card_types[res["cardType"]]
else:
card_type = "未知卡类型【" + res["cardType"] + "】"
if res["bank"] in self.bank:
bank_name = self.bank[res["bank"]]
else:
bank_name = "未知银行"
rec_res_final.update({
"card_type": card_type,
"bank_name": bank_name
})
else:
rec_res_final.update({
"card_type": "未知卡类型",
"bank_name": "未知银行"
})
return rec_res_final
else:
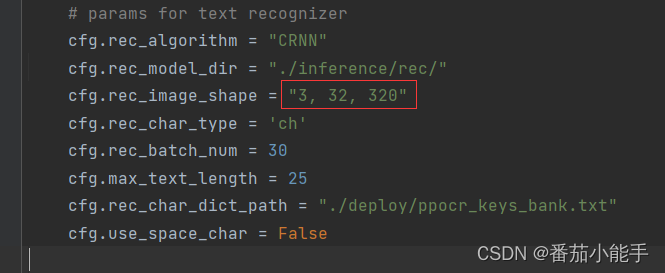
return ""2、参数说明
目前的识别模型是在PP-OCRv2的基础上训练出来的,如何是v3或v4训练的,需要将这里的re_image_shape改成“3,48,320”
3、预测
ocr_bank.py文件中添加main方法:
if __name__ == '__main__':
args = {
"use_gpu": False,
"enable_mkldnn": True
}
ocr_bank = OCRBank(args=args)
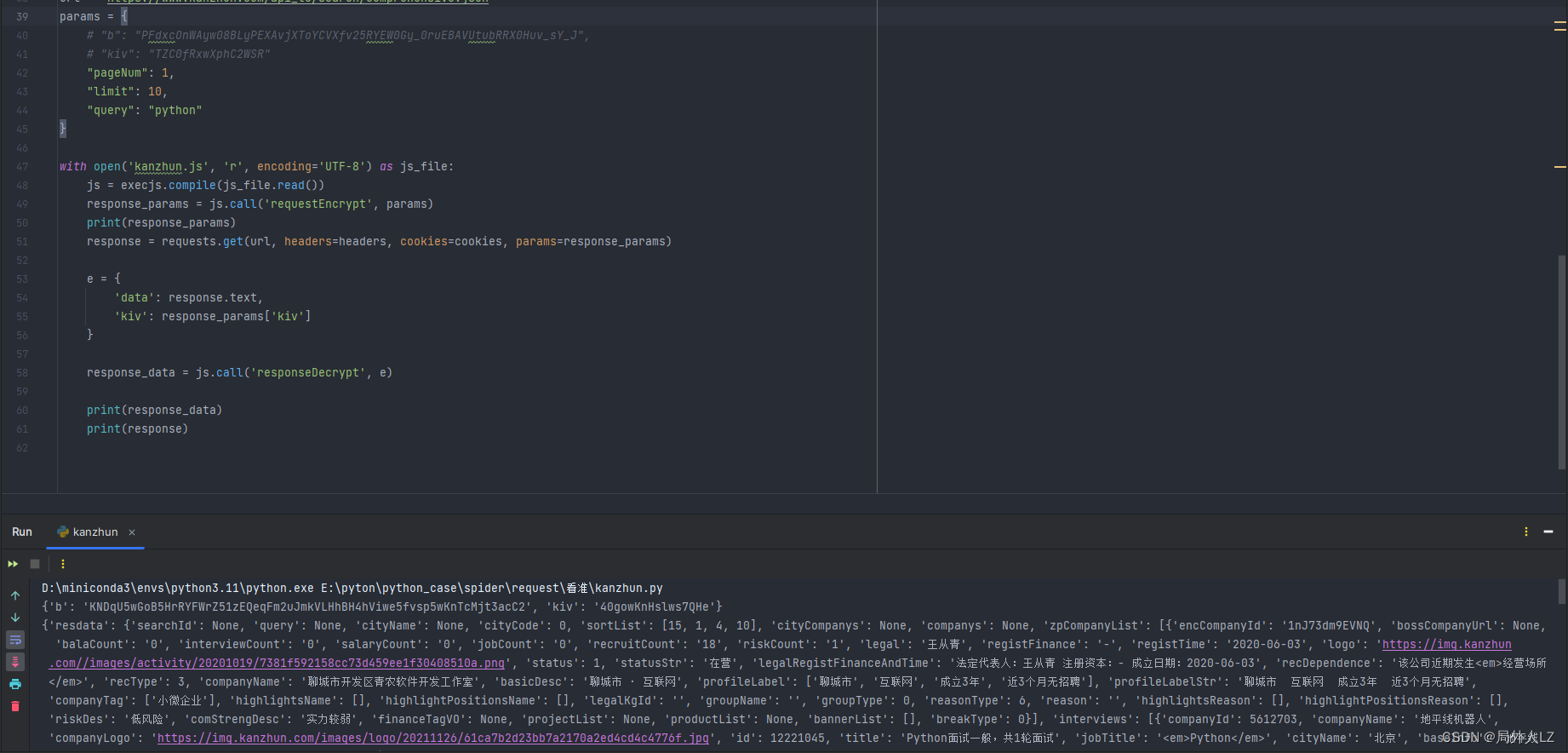
print(ocr_bank.predict(None, "1.jpg"))python .\deploy\ocr_bank.py
结果:
[2023/11/29 15:31:50] ppocr DEBUG: dt_boxes num : 1, elapsed : 0.5060036182403564
[2023/11/29 15:31:50] ppocr DEBUG: rec_res num : 1, elapsed : 0.10000085830688477
{'bank_card_number': '622991116400066409', 'score': 0.9891971945762634, 'location': [[164, 368], [789, 374], [789, 424], [164, 417]], 'card_type': '借记卡', 'bank_name': '河南省农村信用社'}完毕
以上就是银行卡识别的整个流程,精简后可直观的进行部署,这里只是做了第一步精简,在infer中和后处理中,还有部分代码可以进一步精简。
精简后源码下载:
基于PaddleOCR银行卡卡号识别源码