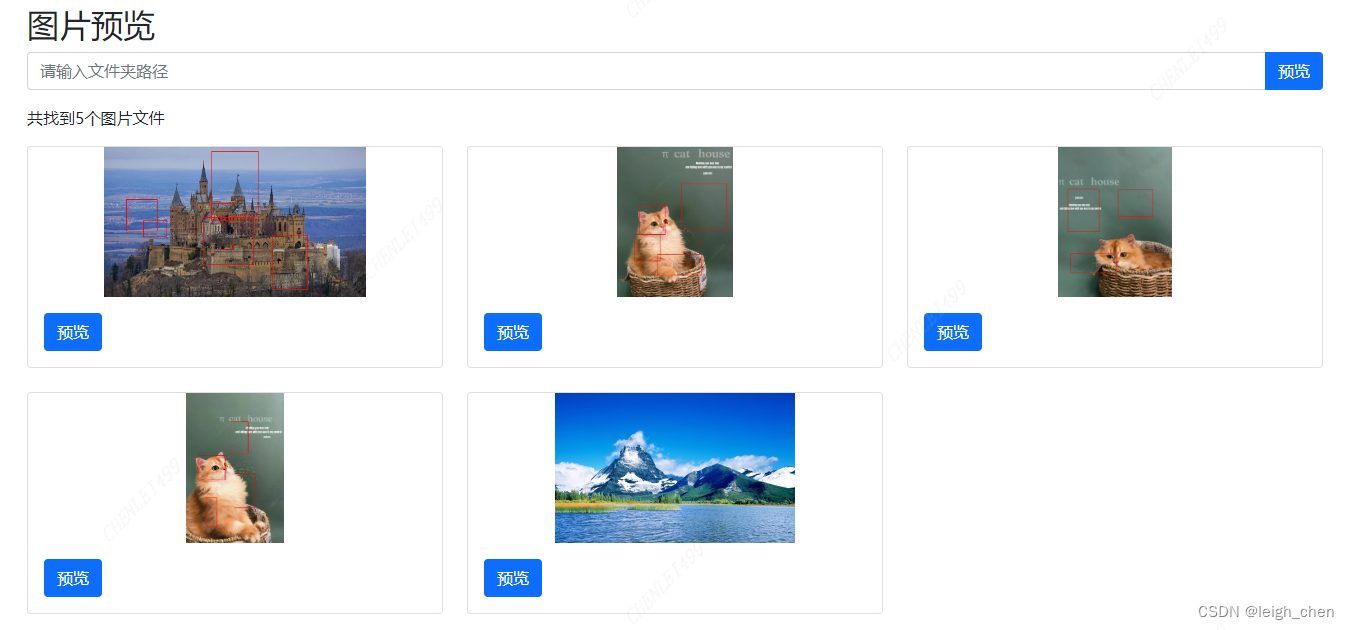
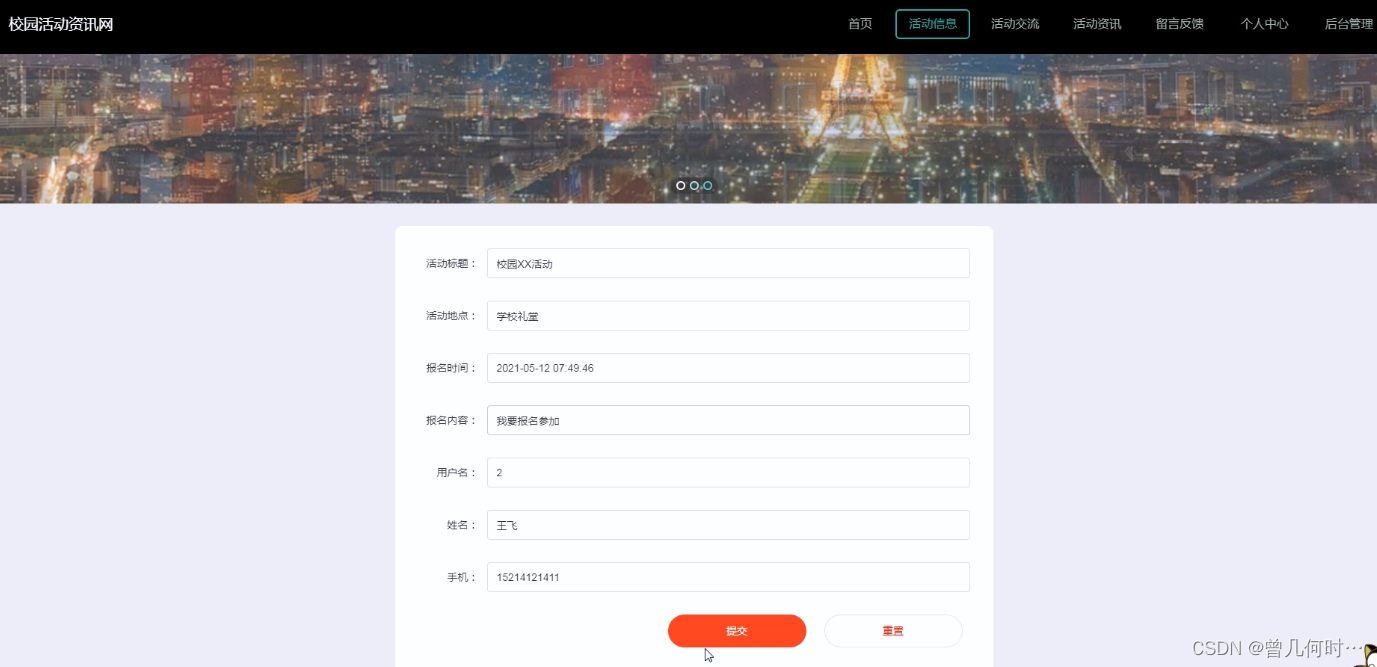
实现功能
通过百度引擎,爬取以“开源之夏”为搜索关键词最新的500条新闻的标题和链接
实现代码
1.安装所需的库:你需要安装requests和beautifulsoup4库。可以使用以下命令通过pip安装:
pip install requests beautifulsoup4
2.发起搜索请求并获取多个搜索结果页面的HTML内容:由于一次搜索结果页面只包含一部分新闻,我们需要多次请求不同页码的搜索结果页面。可以使用以下代码实现:
import requests
def search_baidu(keyword, page):
url = f"https://www.baidu.com/s?wd={keyword}&pn={page}&rn=10"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
这个函数将返回搜索结果页面的HTML内容。
3.解析搜索结果并提取新闻标题和链接:使用beautifulsoup4库解析HTML内容,提取出搜索结果中的新闻标题和链接。可以使用以下代码实现:
from bs4 import BeautifulSoup
def parse_search_results(html):
soup = BeautifulSoup(html, "html.parser")
news_results = soup.find_all("h3", class_="t")
news_list = []
for result in news_results:
title = result.a.text
link = result.a["href"]
news_list.append({"title": title, "link": link})
return news_list
这个函数将返回一个包含新闻标题和链接的列表。
4.完整的爬取过程:将上述步骤整合到一个函数中,实现完整的爬取过程。可以使用以下代码实现:
def crawl_latest_news(keyword, num_news):
news_list = []
num_pages = num_news // 10 + 1 # 每页10条新闻,计算需要请求的页面数
for page in range(num_pages):
html = search_baidu(keyword, page * 10)
if html:
page_news = parse_search_results(html)
news_list.extend(page_news)
else:
print(f"无法获取第 {page+1} 页的搜索结果")
return news_list[:num_news]
现在,你可以调用crawl_latest_news函数,并传入你想要搜索的关键词和要获取的新闻数量(这里是500),获取最新的500条新闻列表。例如:
keyword = "开源之夏"
num_news = 500
news_list = crawl_latest_news(keyword, num_news)
if news_list:
for news in news_list:
print(news["title"])
print(news["link"])
print()
else:
print("无法获取搜索结果")实现效果
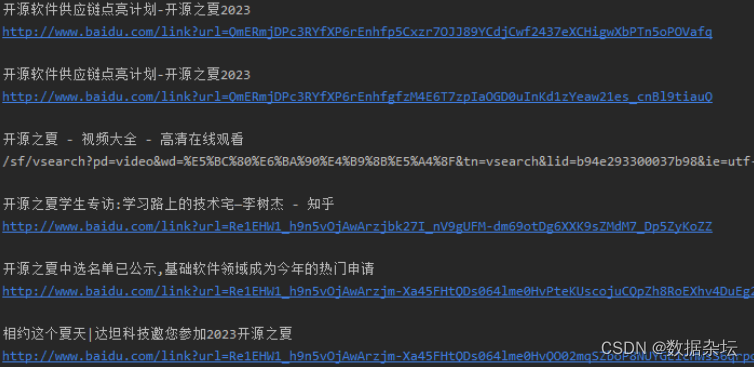
写在后面
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,对Python有一定认知和理解,会结合自身科研实践经历不定期分享关于python、机器学习、深度学习等基础知识与应用案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、邀请三个朋友关注本订阅号或2、分享/在看任意订阅号的三篇文章即可在后台联系我获取相关数据集和源码。
2、关注“数据杂坛”公众号,点击“领资料”即可免费领取资料书籍。
3、如果对本文有疑问,或者有论文指导的相关需求,点击“联系我”添加作者微信直接交流。