✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆
🔥系列专栏 :【狂神说Java】
📃新人博主 :欢迎点赞收藏关注,会回访!
💬舞台再大,你不上台,永远是个观众。平台再好,你不参与,永远是局外人。能力再大,你不行动,只能看别人成功!没有人会关心你付出过多少努力,撑得累不累,摔得痛不痛,他们只会看你最后站在什么位置,然后羡慕或鄙夷。
文章目录
- Jedis
- 什么是Jedis
- 导入依赖
- 修改配置
- idea连接并操作
- 事务
- 常用api
- SpringBoot整合
- 导入依赖
- 编写配置文件
- 使用RedisTemplate
- 测试结果
- 定制RedisTemplate模板
- 自定义Redis工具类
- 持久化
- RDB
- 什么是RDB
- 工作原理
- 触发机制
- RDB优缺点
- AOF
- 什么是AOF
- 优点和缺点
- RDB和AOP选择
- Redis发布与订阅
- 命令
- 示例
- 原理
- 缺点
- 应用
- Redis主从复制
- 概念
- 作用
- 为什么使用集群
- 环境配置
- 一主二从配置
- 使用规则
- 哨兵模式
- 哨兵的作用
- 哨兵模式优缺点
- 缓存穿透与雪崩
- 缓存穿透
- 概念
- 解决方案
- 缓存击穿(量太大,缓存过期)
- 概念
- 解决方案
- 缓存雪崩
- 概念
- 解决方案
Jedis
我们要使用java来操作Redis
什么是Jedis
Jedis是Redis官方推荐的java连接开发工具,使用java操作Redis中间件!如果要使用Java操作Redis,要对Jedis十分熟悉
导入依赖
<!--导入jredis的包-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
修改配置
(1)修改redis的配置文件
vim /usr/local/bin/redis-20231111.conf
- 取消只绑定本地注释(注解掉那个bind127.0.0.0)
- 保护模式改为
protected-mode no - 允许后台运行
daemonize yes
(2)开放端口6379
firewall-cmd --zone=public --add-port=6379/tcp --permanet
或者直接关掉防火墙
service firewalld stop
service stop iptables
(3)重启防火墙服务
systemctl restart firewalld.service
(4)去阿里云服务器控制台配置安全组
(5)重启redis-server 启动要设置配置文件目录!
redis-server redis-20231111.conf
idea连接并操作
public class TestPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.3.22", 6379);
String response = jedis.ping();
System.out.println(response); // PONG
}
}
事务
public class TestTX {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.3.22", 6379);
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello", "world");
jsonObject.put("name", "kuangshen");
// 开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
// jedis.watch(result)
try {
multi.set("user1", result);
multi.set("user2", result);
// 执行事务
multi.exec();
}catch (Exception e){
// 放弃事务
multi.discard();
} finally {
// 关闭连接
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close();
}
}
}
常用api
import redis.clients.jedis.Jedis;
public class JedisType {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
System.out.println("=================== String =========================");
System.out.println(jedis.set("name", "zs"));
System.out.println(jedis.get("name"));
System.out.println(jedis.append("name", "+value"));
System.out.println(jedis.get("name"));
System.out.println(jedis.strlen("name"));
System.out.println("=================== List =========================");
System.out.println(jedis.lpush("listKey", "l1", "l2", "l3"));
System.out.println(jedis.lrange("listKey", 0, -1)); // [l3, l2, l1]
System.out.println(jedis.llen("listKey"));
System.out.println("=================== Hash =========================");
System.out.println(jedis.hset("hashKey", "k1", "v1"));
System.out.println(jedis.hset("hashKey", "k2", "v2"));
System.out.println(jedis.hset("hashKey", "k3", "v3"));
System.out.println(jedis.hmget("hashKey", "k1", "k2", "k3")); // [v1, v2, v3]
System.out.println(jedis.hgetAll("hashKey")); // {k3=v3, k2=v2, k1=v1}
System.out.println("=================== Set =========================");
System.out.println(jedis.sadd("setKey", "s1", "s2", "s3", "s4"));
System.out.println(jedis.smembers("setKey")); // [s2, s1, s4, s3]
System.out.println(jedis.scard("setKey"));
System.out.println("=================== Zset =========================");
System.out.println(jedis.zadd("ZKey", 90, "z1"));
System.out.println(jedis.zadd("ZKey", 80, "z2"));
System.out.println(jedis.zadd("ZKey", 85, "z3"));
System.out.println(jedis.zrange("ZKey", 0, -1)); // [z2, z3, z1]
}
}
import java.util.Set;
import redis.clients.jedis.Jedis;
public class TestKey {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
System.out.println("清空数据:" + jedis.flushDB());
System.out.println("判断某个键是否存在:" + jedis.exists("username"));
System.out.println("新增<'username','kuangshen'>的键值对:" + jedis.set("username", "kuangshen"));
System.out.println("新增<'password','password'>的键值对:" + jedis.set("password", "password"));
System.out.print("系统中所有的键如下:");
Set<String> keys = jedis.keys("*");
System.out.println(keys);
System.out.println("删除键password:" + jedis.del("password"));
System.out.println("判断键password是否存在:" + jedis.exists("password"));
System.out.println("查看键username所存储的值的类型:" + jedis.type("username"));
System.out.println("随机返回key空间的一个:" + jedis.randomKey());
System.out.println("重命名key:" + jedis.rename("username", "name"));
System.out.println("取出改后的name:" + jedis.get("name"));
System.out.println("按索引查询:" + jedis.select(0));
System.out.println("删除当前选择数据库中的所有key:" + jedis.flushDB());
System.out.println("返回当前数据库中key的数目:" + jedis.dbSize());
System.out.println("删除所有数据库中的所有key:" + jedis.flushAll());
jedis.connect();
jedis.disconnect();
jedis.flushAll();
}
}
import java.util.concurrent.TimeUnit;
import redis.clients.jedis.Jedis;
public class TestString {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("===========增加数据===========");
System.out.println(jedis.set("key1", "value1"));
System.out.println(jedis.set("key2", "value2"));
System.out.println(jedis.set("key3", "value3"));
System.out.println("删除键key2:" + jedis.del("key2"));
System.out.println("获取键key2:" + jedis.get("key2"));
System.out.println("修改key1:" + jedis.set("key1", "value1Changed"));
System.out.println("获取key1的值:" + jedis.get("key1"));
System.out.println("在key3后面加入值:" + jedis.append("key3", "End"));
System.out.println("key3的值:" + jedis.get("key3"));
System.out.println("增加多个键值对:" + jedis.mset(new String[]{"key01", "value01", "key02", "value02", "key03", "value03"}));
System.out.println("获取多个键值对:" + jedis.mget(new String[]{"key01", "key02", "key03"}));
System.out.println("获取多个键值对:" + jedis.mget(new String[]{"key01", "key02", "key03", "key04"}));
System.out.println("删除多个键值对:" + jedis.del(new String[]{"key01", "key02"}));
System.out.println("获取多个键值对:" + jedis.mget(new String[]{"key01", "key02", "key03"}));
jedis.flushDB();
System.out.println("===========新增键值对防止覆盖原先值==============");
System.out.println(jedis.setnx("key1", "value1"));
System.out.println(jedis.setnx("key2", "value2"));
System.out.println(jedis.setnx("key2", "value2-new"));
System.out.println(jedis.get("key1"));
System.out.println(jedis.get("key2"));
System.out.println("===========新增键值对并设置有效时间=============");
System.out.println(jedis.setex("key3", 2, "value3"));
System.out.println(jedis.get("key3"));
try {
TimeUnit.SECONDS.sleep(3L);
} catch (InterruptedException var3) {
var3.printStackTrace();
}
System.out.println(jedis.get("key3"));
System.out.println("===========获取原值,更新为新值==========");
System.out.println(jedis.getSet("key2", "key2GetSet"));
System.out.println(jedis.get("key2"));
System.out.println("获得key2的值的字串:" + jedis.getrange("key2", 2L, 4L));
}
}
import redis.clients.jedis.Jedis;
public class TestList {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("===========添加一个list===========");
jedis.lpush("collections", new String[]{"ArrayList", "Vector", "Stack", "HashMap", "WeakHashMap", "LinkedHashMap"});
jedis.lpush("collections", new String[]{"HashSet"});
jedis.lpush("collections", new String[]{"TreeSet"});
jedis.lpush("collections", new String[]{"TreeMap"});
System.out.println("collections的内容:" + jedis.lrange("collections", 0L, -1L));
System.out.println("collections区间0-3的元素:" + jedis.lrange("collections", 0L, 3L));
System.out.println("===============================");
System.out.println("删除指定元素个数:" + jedis.lrem("collections", 2L, "HashMap"));
System.out.println("collections的内容:" + jedis.lrange("collections", 0L, -1L));
System.out.println("删除下表0-3区间之外的元素:" + jedis.ltrim("collections", 0L, 3L));
System.out.println("collections的内容:" + jedis.lrange("collections", 0L, -1L));
System.out.println("collections列表出栈(左端):" + jedis.lpop("collections"));
System.out.println("collections的内容:" + jedis.lrange("collections", 0L, -1L));
System.out.println("collections添加元素,从列表右端,与lpush相对应:" + jedis.rpush("collections", new String[]{"EnumMap"}));
System.out.println("collections的内容:" + jedis.lrange("collections", 0L, -1L));
System.out.println("collections列表出栈(右端):" + jedis.rpop("collections"));
System.out.println("collections的内容:" + jedis.lrange("collections", 0L, -1L));
System.out.println("修改collections指定下标1的内容:" + jedis.lset("collections", 1L, "LinkedArrayList"));
System.out.println("collections的内容:" + jedis.lrange("collections", 0L, -1L));
System.out.println("===============================");
System.out.println("collections的长度:" + jedis.llen("collections"));
System.out.println("获取collections下标为2的元素:" + jedis.lindex("collections", 2L));
System.out.println("===============================");
jedis.lpush("sortedList", new String[]{"3", "6", "2", "0", "7", "4"});
System.out.println("sortedList排序前:" + jedis.lrange("sortedList", 0L, -1L));
System.out.println(jedis.sort("sortedList"));
System.out.println("sortedList排序后:" + jedis.lrange("sortedList", 0L, -1L));
}
}
import redis.clients.jedis.Jedis;
public class TestSet {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("============向集合中添加元素(不重复)============");
System.out.println(jedis.sadd("eleSet", new String[]{"e1", "e2", "e4", "e3", "e0", "e8", "e7", "e5"}));
System.out.println(jedis.sadd("eleSet", new String[]{"e6"}));
System.out.println(jedis.sadd("eleSet", new String[]{"e6"}));
System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet"));
System.out.println("删除一个元素e0:" + jedis.srem("eleSet", new String[]{"e0"}));
System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet"));
System.out.println("删除两个元素e7和e6:" + jedis.srem("eleSet", new String[]{"e7", "e6"}));
System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet"));
System.out.println("随机的移除集合中的一个元素:" + jedis.spop("eleSet"));
System.out.println("随机的移除集合中的一个元素:" + jedis.spop("eleSet"));
System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet"));
System.out.println("eleSet中包含元素的个数:" + jedis.scard("eleSet"));
System.out.println("e3是否在eleSet中:" + jedis.sismember("eleSet", "e3"));
System.out.println("e1是否在eleSet中:" + jedis.sismember("eleSet", "e1"));
System.out.println("e1是否在eleSet中:" + jedis.sismember("eleSet", "e5"));
System.out.println("=================================");
System.out.println(jedis.sadd("eleSet1", new String[]{"e1", "e2", "e4", "e3", "e0", "e8", "e7", "e5"}));
System.out.println(jedis.sadd("eleSet2", new String[]{"e1", "e2", "e4", "e3", "e0", "e8"}));
System.out.println("将eleSet1中删除e1并存入eleSet3中:" + jedis.smove("eleSet1", "eleSet3", "e1"));
System.out.println("将eleSet1中删除e2并存入eleSet3中:" + jedis.smove("eleSet1", "eleSet3", "e2"));
System.out.println("eleSet1中的元素:" + jedis.smembers("eleSet1"));
System.out.println("eleSet3中的元素:" + jedis.smembers("eleSet3"));
System.out.println("============集合运算=================");
System.out.println("eleSet1中的元素:" + jedis.smembers("eleSet1"));
System.out.println("eleSet2中的元素:" + jedis.smembers("eleSet2"));
System.out.println("eleSet1和eleSet2的交集:" + jedis.sinter(new String[]{"eleSet1", "eleSet2"}));
System.out.println("eleSet1和eleSet2的并集:" + jedis.sunion(new String[]{"eleSet1", "eleSet2"}));
System.out.println("eleSet1和eleSet2的差集:" + jedis.sdiff(new String[]{"eleSet1", "eleSet2"}));
jedis.sinterstore("eleSet4", new String[]{"eleSet1", "eleSet2"});
System.out.println("eleSet4中的元素:" + jedis.smembers("eleSet4"));
}
}
import java.util.HashMap;
import java.util.Map;
import redis.clients.jedis.Jedis;
public class TestHash {
public TestHash() {
}
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
Map<String, String> map = new HashMap();
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
jedis.hmset("hash", map);
jedis.hset("hash", "key5", "value5");
System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash"));
System.out.println("散列hash的所有键为:" + jedis.hkeys("hash"));
System.out.println("散列hash的所有值为:" + jedis.hvals("hash"));
System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:" + jedis.hincrBy("hash", "key6", 6L));
System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash"));
System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:" + jedis.hincrBy("hash", "key6", 3L));
System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash"));
System.out.println("删除一个或者多个键值对:" + jedis.hdel("hash", new String[]{"key2"}));
System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash"));
System.out.println("散列hash中键值对的个数:" + jedis.hlen("hash"));
System.out.println("判断hash中是否存在key2:" + jedis.hexists("hash", "key2"));
System.out.println("判断hash中是否存在key3:" + jedis.hexists("hash", "key3"));
System.out.println("获取hash中的值:" + jedis.hmget("hash", new String[]{"key3"}));
System.out.println("获取hash中的值:" + jedis.hmget("hash", new String[]{"key3", "key4"}));
}
}
SpringBoot整合
导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
编写配置文件
# 配置redis
spring.redis.host=xxx.xxx.xxx.xxx
spring.redis.port=6379
使用RedisTemplate
@SpringBootTest
class Redis02SpringbootApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
// redisTemplate 操作不同的数据类型,api和我们的指令是一样的
// opsForValue 操作字符串 类似String
// opsForList 操作List 类似List
// opsForHah
// 除了基本的操作,我们常用的方法都可以直接通过redisTemplate操作,比如事务和基本的CRUD
// 获取连接对象
//RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
//connection.flushDb();
//connection.flushAll();
redisTemplate.opsForValue().set("mykey","kuangshen");
System.out.println(redisTemplate.opsForValue().get("mykey"));
}
}
测试结果
回到redis查看数据发现全是乱码,但是控制台可以正常输出
这时候就关系到存储对象的序列化问题,在网络中传输的对象也是一样需要序列化,否者就全是乱码。
默认的序列化器是采用JDK序列化器,后续我们定制RedisTemplate就可以对其进行修改。
定制RedisTemplate模板
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
// 将template 泛型设置为 <String, Object>
RedisTemplate<String, Object> template = new RedisTemplate();
// 连接工厂,不必修改
template.setConnectionFactory(redisConnectionFactory);
/*
* 序列化设置
*/
// key、hash的key 采用 String序列化方式
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// value、hash的value 采用 Jackson 序列化方式
template.setValueSerializer(RedisSerializer.json());
template.setHashValueSerializer(RedisSerializer.json());
template.afterPropertiesSet();
return template;
}
}
这样,只要实体类进行了序列化,我们存什么都不会有乱码的担忧了。
自定义Redis工具类
使用RedisTemplate需要频繁调用.opForxxx然后才能进行对应的操作,这样使用起来代码效率低下,工作中一般不会这样使用,而是将这些常用的公共API抽取出来封装成为一个工具类,然后直接使用工具类来间接操作Redis,不但效率高并且易用。
工具类参考文档:
SpringBoot整合Redis及Redis工具类撰写 - zeng1994 - 博客园
java redisUtils工具类很全 - 静静别跑 - 博客园
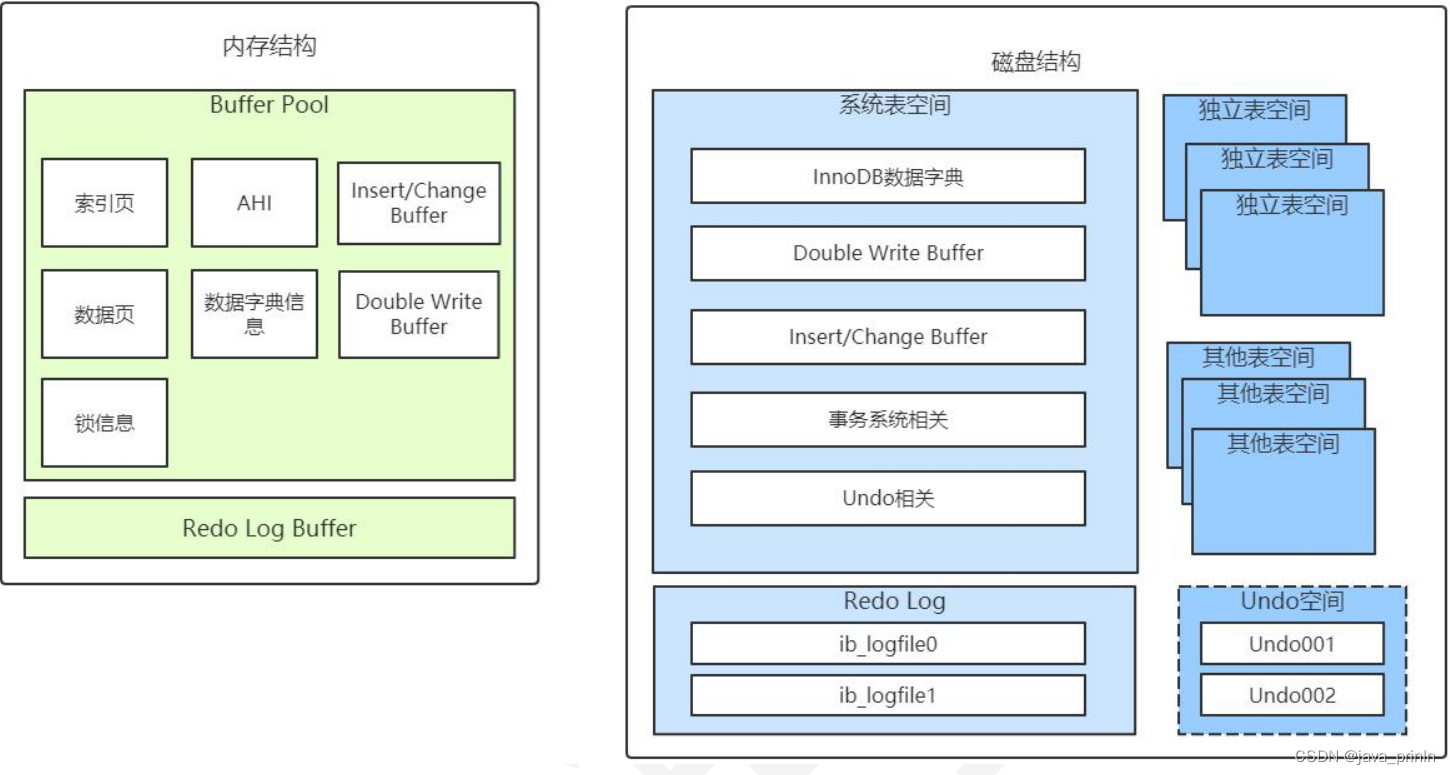
持久化
RDB
什么是RDB
在指定时间间隔后,将内存中的数据集快照写入数据库 ;在恢复时候,直接读取快照文件,进行数据的恢复 ;
默认情况下, Redis 将数据库快照保存在名字为** dump.rdb**的二进制文件中。文件名可以在配置文件中进行自定义。
工作原理
在进行RDB的时候,redis的主线程是不会做io操作的,主线程会fork一个子线程来完成该操作;
- Redis 调用forks。同时拥有父进程和子进程。
- 子进程将数据集写入到一个临时 RDB 文件中。
- 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益(因为是使用子进程进行写操作,而进程依然可以接收来自客户端的请求。)
触发机制
- save的规则满足的情况下,会自动触发rdb原则
- 执行flushall命令,也会触发我们的rdb原则
- 退出redis,也会自动产生rdb文件
save
使用save命令,会立刻对当前内存中的数据进行持久化 ,但是会阻塞,也就是不接受其他操作了
由于save 命令是同步命令,会占用Redis的主进程。若Redis数据非常多时,save命令执行速度会非常慢,阻塞所有客户端的请求。
flushall命令
flushall命令也会触发持久化 ;
触发持久化规则
可以通过配置文件redis.conf 对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动进行数据集保存操作。
bgsave
bgsave是异步进行,进行持久化的时候,redis 还可以将继续响应客户端请求
bgsave和save对比
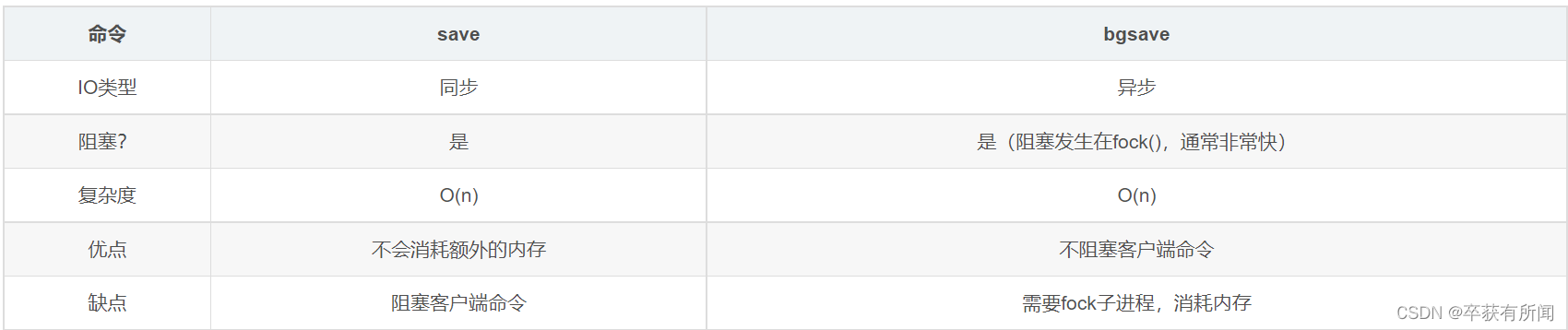
RDB优缺点
优点:
- 适合大规模的数据恢复
- 对数据的完整性要求不高
缺点:
- 需要一定的时间间隔进行操作,如果redis意外宕机了,这个最后一次修改的数据就没有了。
- fork进程的时候,会占用一定的内容空间。
AOF
Append Only File 将我们所有的命令都记录下来,history,恢复的时候就把这个文件全部再执行一遍
什么是AOF
快照功能(RDB)并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、以及未保存到快照中的那些数据。 从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化。
如果要使用AOF,需要修改配置文件:

**appendonly yes **则表示启用AOF
默认是不开启的,我们需要手动配置,然后重启redis。在大部分的情况下,rdb完全够用
如果这个aof文件有错位,这时候redis是启动不起来的,我需要修改这个aof文件
redis给我们提供了一个修复的工具 redis-check-aof --fix
优点和缺点
优点
- 每一次修改都会同步,文件的完整性会更加好
- 没秒同步一次,可能会丢失一秒的数据
- 从不同步,效率最高
缺点
- 相对于数据文件来说,aof远远大于rdb,修复速度比rdb慢!
- Aof运行效率也要比rdb慢,所以我们redis默认的配置就是rdb持久化
RDB和AOP选择

如何选择使用哪种持久化方式?
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快
Redis发布与订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
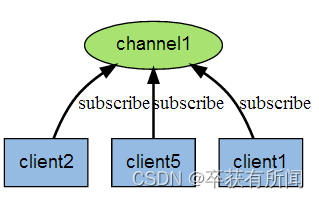
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:

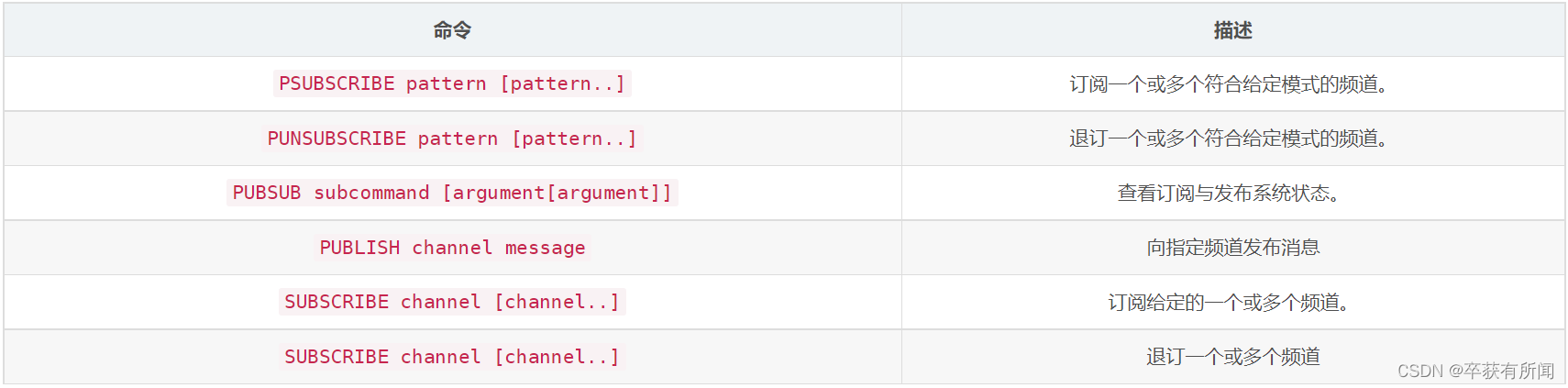
命令
示例
------------订阅端----------------------
127.0.0.1:6379> SUBSCRIBE sakura # 订阅sakura频道
Reading messages... (press Ctrl-C to quit) # 等待接收消息
1) "subscribe" # 订阅成功的消息
2) "sakura"
3) (integer) 1
1) "message" # 接收到来自sakura频道的消息 "hello world"
2) "sakura"
3) "hello world"
1) "message" # 接收到来自sakura频道的消息 "hello i am sakura"
2) "sakura"
3) "hello i am sakura"
--------------消息发布端-------------------
127.0.0.1:6379> PUBLISH sakura "hello world" # 发布消息到sakura频道
(integer) 1
127.0.0.1:6379> PUBLISH sakura "hello i am sakura" # 发布消息
(integer) 1
-----------------查看活跃的频道------------
127.0.0.1:6379> PUBSUB channels
1) "sakura"
原理
每个 Redis 服务器进程都维持着一个表示服务器状态的 redis.h/redisServer 结构, 结构的 pubsub_channels 属性是一个字典, 这个字典就用于保存订阅频道的信息,其中,字典的键为正在被订阅的频道, 而字典的值则是一个链表, 链表中保存了所有订阅这个频道的客户端。
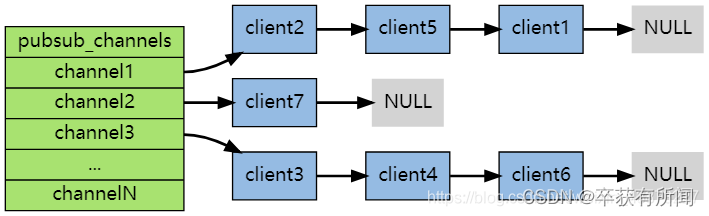
客户端订阅,就被链接到对应频道的链表的尾部,退订则就是将客户端节点从链表中移除。
缺点
- 如果一个客户端订阅了频道,但自己读取消息的速度却不够快的话,那么不断积压的消息会使redis输出缓冲区的体积变得越来越大,这可能使得redis本身的速度变慢,甚至直接崩溃。
- 这和数据传输可靠性有关,如果在订阅方断线,那么他将会丢失所有在短线期间发布者发布的消息。
应用
- 消息订阅:公众号订阅,微博关注等等(其实更多是使用消息队列来进行实现)
- 多人在线聊天室。
但是稍微复杂的场景,我们就会使用消息中间件MQ处理。
Redis主从复制
概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。
作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用基石:主从复制还是哨兵和集群能够实施的基础。
为什么使用集群
- 单台服务器难以负载大量的请求
- 单台服务器故障率高,系统崩坏概率大
- 单台服务器内存容量有限。
环境配置
查看当前库的信息:info replication
既然需要启动多个服务,就需要多个配置文件。每个配置文件对应修改以下信息:
- 端口号
- pid文件名
- 日志文件名
- rdb文件名
启动单机多服务集群:

一主二从配置
默认情况下,每台Redis服务器都是主节点;我们一般情况下只用配置从机就好了!
认老大!一主(79)二从(80,81)
使用 SLAVEOF xxx.xxx.xxx.xxx(主机号) 6379(端口号) 就可以为从机配置主机了。

然后主机上也能看到从机的状态:
我们这里是使用命令搭建,是暂时的,真实开发中应该在从机的配置文件中进行配置,这样的话是永久的。
使用规则
- 从机只能读,不能写,主机可读可写但是多用于写。
- 当主机断电宕机后,默认情况下从机的角色不会发生变化 ,集群中只是失去了写操作,当主机恢复以后,又会连接上从机恢复原状。
- 当从机断电宕机后,若不是使用配置文件配置的从机,再次启动后作为主机是无法获取之前主机的数据的,若此时重新配置称为从机,又可以获取到主机的所有数据。这里就要提到一个同步原理(从机会复制其他从机数据)
- 第二条中提到,默认情况下,主机故障后,不会出现新的主机,有两种方式可以产生新的主机:从机手动执行命令slaveof no one,这样执行以后从机会独立出来成为一个主机使用哨兵模式(自动选举)
如果主机断开了连接,我们可以使用SLAVEOF no one让自己变成主机!其他的节点就可以手动连接到最新的主节点(手动)!如果这个时候老大修复了,那么久重新连接!
哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。
所有我们推荐使用哨兵模式
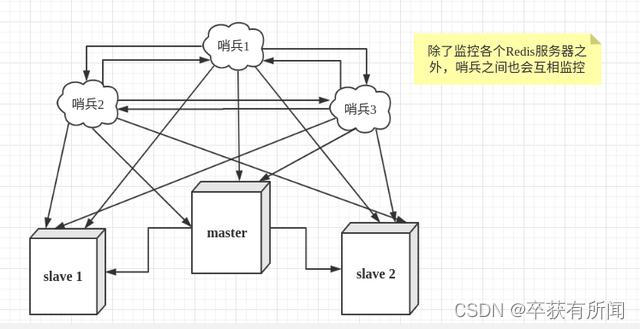
哨兵的作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
哨兵的核心配置
sentinel monitor mymaster 127.0.0.1 6379 1
(数字1表示 :当一个哨兵主观认为主机断开,就可以客观认为主机故障,然后开始选举新的主机)
当从机代替主机之后,之前被替换掉的主机重新加入不能再继续当主机了
哨兵模式优缺点
- 哨兵集群,基于主从复制模式,所有主从复制的优点,它都有
- 主从可以切换,故障可以转移,系统的可用性更好
- 哨兵模式是主从模式的升级,手动到自动,更加健壮
缺点:
- Redis不好在线扩容,集群容量一旦达到上限,在线扩容就十分麻烦
- 实现哨兵模式的配置其实是很麻烦的,里面有很多配置项
缓存穿透与雪崩
缓存穿透
概念
在默认情况下,用户请求数据时,会先在缓存(Redis)中查找,若没找到即缓存未命中,再在数据库中进行查找,数量少可能问题不大,可是一旦大量的请求数据(例如秒杀场景)缓存都没有命中的话,就会全部转移到数据库上,造成数据库极大的压力,就有可能导致数据库崩溃。网络安全中也有人恶意使用这种手段进行攻击被称为洪水攻击。
解决方案
布隆过滤器
对所有可能查询的参数以Hash的形式存储,以便快速确定是否存在这个值,在控制层先进行拦截校验,校验不通过直接打回,减轻了存储系统的压力。
缓存空对象
一次请求若在缓存和数据库中都没找到,就在缓存中方一个空对象用于处理后续这个请求。
这样做有一个缺陷:存储空对象也需要空间,大量的空对象会耗费一定的空间,存储效率并不高。解决这个缺陷的方式就是设置较短过期时间
即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿(量太大,缓存过期)
概念
相较于缓存穿透,缓存击穿的目的性更强,一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。这就是缓存被击穿,只是针对其中某个key的缓存不可用而导致击穿,但是其他的key依然可以使用缓存响应。
比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。
解决方案
1、设置热点数据永不过期
这样就不会出现热点数据过期的情况,但是当Redis内存空间满的时候也会清理部分数据,而且此种方案会占用空间,一旦热点数据多了起来,就会占用部分空间。
2、加互斥锁(分布式锁)
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。保证同时刻只有一个线程访问。这样对锁的要求就十分高。
缓存雪崩
概念
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
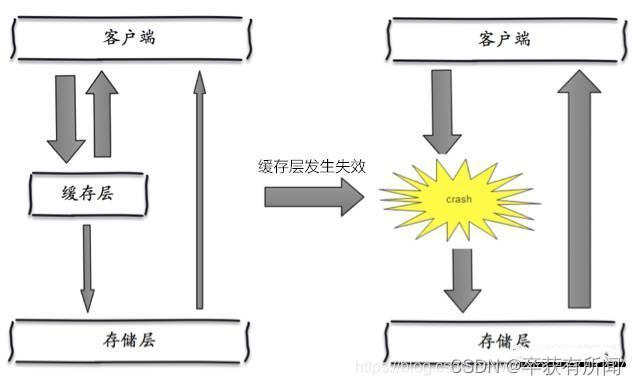
解决方案
redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。