一、主题描述
2014 年生成对抗网络的诞生及其对任意数据分布进行有效建模的能力席卷了计算机视觉界。两人范例的简单性和推理时令人惊讶的快速样本生成是使 GAN 成为现实世界中实际应用的理想选择的两个主要因素。
然而,在它们出现后的很长一段时间内,GAN 的生成能力仅限于为相对低分辨率的数据集生成样本(例如 MNIST(28× 28图像),CIFAR10(32× 32图像)等)。这可以归因于这样一个事实:生成对抗网络难以捕获底层数据分布的多种模式和高分辨率图像中复杂的低级细节。这在实践中受到限制,因为现实世界中的应用通常需要高分辨率的样本生成。
因此,计算机视觉界齐心协力改进底层网络架构,引入新的训练技术来稳定训练过程并提高生成样本的质量。
在本教程中,我们将研究一种这样的技术,即渐进式生长,它在弥合这一差距并使 GAN 能够以更高分辨率生成高质量样本方面发挥了关键作用,这对于各种实际应用至关重要。具体来说,我们将详细讨论以下内容:
- Progressive GAN(PGAN)的架构细节
- 渐进式生长技术和显着特征使PGAN能够通过稳定高效的训练生成高分辨率样本
- 从 Torch Hub 导入 PGAN 等预训练生成模型,以便快速、无缝地集成到我们的深度学习项目中
- 使用预训练的 PGAN 模型生成高分辨率人脸图像
- 走过经过训练的 PGAN 的潜在空间
二、渐进式 GAN 架构
长期以来,生成对抗网络一直在努力生成高分辨率图像。这主要是因为高分辨率图像包含大量以高级结构和复杂的低级细节形式存在的信息,这些信息很难一次性全部学习。
这可以从多人训练范式的角度来理解,该范式构成了 GAN 训练的一个组成部分。正如之前教程中所讨论的,GAN 的主要组成部分是在每一步更新生成器以愚弄鉴别器。然而,当采用 GAN 生成高分辨率图像时,生成器很难同时对图像的高级细节和复杂的低级细节进行整体建模。尤其是在训练的初始阶段,权重或多或少是随机的,尤其如此。
这使得鉴别器变得更强,因为它可以轻松区分生成器样本和真实样本,从而扰乱生成器和鉴别器的平衡,而这对于 GAN 的最佳收敛至关重要。
此外,在另一个教程中,我们讨论了 GAN 容易出现模式崩溃。上述问题也可以从 GAN 的目标分布建模的角度来看待。具体来说,生成器很难一次有效地捕获数据分布的所有模式。当数据具有高分辨率并且包含与高级结构和更精细的语义细节相关的多种模式时,这个问题变得更加严重。
渐进式 GAN 旨在通过将生成高分辨率图像的复杂任务划分为更简单的子任务来缓解上述问题。这主要是通过要求生成器在每一步解决更简单的生成任务来实现的。
具体来说,在训练过程中,生成器最初需要学习图像的低分辨率版本。随着它在以较低分辨率生成图像方面慢慢变得更好,要求生成器生成的图像的分辨率也会增加。这保持了生成高分辨率图像的最终目标不变,但不会立即使生成器负担过重,并允许它逐渐捕获图像中的高级别和低级别细节。图 1有效地体现了该技术背后的动机。

图 1:渐进式增长学习范式背后的直觉(图片来源)。
图 2说明了构成 PGAN 基础的渐进式增长范式。具体来说,我们从一个生成低分辨率图像的生成器开始(例如,8× 8)和一个相应的鉴别器,它采用生成的8× 8图像作为输入以及真实图像(最初是1024× 1024)调整大小为8× 8方面。

图 2:训练过程中的 PGAN 架构(图片由作者提供)。
此时,生成器学习对图像分布的高级结构进行建模。逐渐地,新层同步添加到生成器和鉴别器,使它们能够以更高分辨率处理图像。这使得生成器能够遵循平滑且渐进的学习曲线,并慢慢学习更高分辨率图像中的精细细节。
渐进增长范式也可以从假设估计的角度来看待。我们不要求生成器立即学习复杂的函数,而是要求它在每一步学习更简单的子函数。因此,生成器需要在特定时间步捕获更少的模式。因此,随着训练的进行,它可以逐渐捕获不同的数据分布模式。
此外,由于生成器面临着生成低分辨率图像的更简单的任务,特别是在训练的初始阶段,生成器可以在这些任务上做得相当好,保持鉴别器和生成器的强度之间的平衡。
三、渐进式种植技术
我们在上一节中讨论了 PGAN 网络如何通过将高分辨率图像划分为更简单的任务来解决生成高分辨率图像的复杂问题。此外,我们观察到,这需要生成器和鉴别器架构同步渐进增长,以从低分辨率图像开始逐渐处理更高分辨率的图像。
在本部分教程中,我们将讨论 PGAN 架构如何实现渐进式增长技术。具体来说,总体目标是在每个阶段慢慢向生成器和鉴别器添加层。
图 3显示了渐进式增长范式的要点。形式上,我们希望逐步在生成器和鉴别器中添加层,并确保它们平稳且逐步地与网络集成,而不会对训练过程产生任何突然的改变。
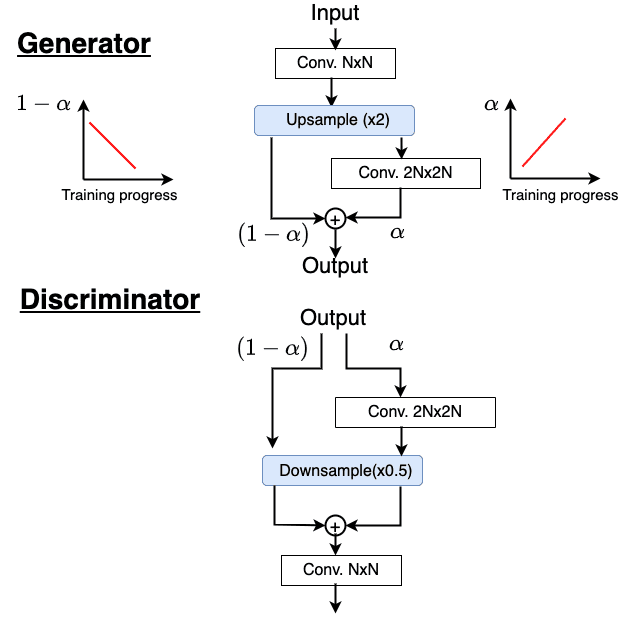
图 3:渐进式增长技术逐渐向网络添加层(图片由作者提供)。
对于生成器(即图 3顶部)的情况,我们假设在给定阶段,我们得到如图所示的输入,并且我们希望将生成器的输出分辨率加倍。为了实现这一点,我们首先使用upsample()操作,将图像的空间维度增加了一个因子× 2。此外,我们添加了一个新的卷积层,输出2N×2N三维图像(显示在右侧分支上)。请注意,最终输出是左右分支输出的加权和α和1-α分别为加权系数。
现在我们来了解一下它的作用α 在上面所示的架构中。从右侧的图中我们可以看到,α随着训练的进行线性增加,因此,1-α 线性衰减。
最初,卷积层是随机初始化的,它不会计算任何有意义的函数或输出。因此,卷积层的输出被赋予一个低的非零加权系数(例如,α = 0.1 ),整个输出几乎来自上采样层。请注意,上采样层不可学习或参数化,并使用最近邻插值等技术来增加空间维度。
即使系数α最初很低,梯度流过卷积层。随着训练的进行,新添加层的权重逐渐开始学习并输出有意义的图像。因此,慢慢地,卷积层的权重(即α)如图所示增加,并且来自不可学习的上采样层的贡献(即,1-α) 降低了。这使得新添加的卷积层能够平滑地与网络集成,并学习比简单的基于最近插值的上采样更复杂的函数。
鉴别器也遵循类似的方法,如图 3(底部)所示,逐渐添加层。这里唯一的区别是鉴别器从生成器获取输出图像并对空间维度进行下采样,如图所示。请注意,在给定阶段,层同时添加到鉴别器和生成器,因为鉴别器必须在任何给定时间步处理来自生成器的输出图像。
现在我们已经讨论了 PGAN 架构,让我们继续看看网络的运行情况!
四、CelebA 数据集
在本教程中,我们将使用CelebA 数据集,它由各种名人的高分辨率面部图像组成,使其成为我们教程的合适选择。具体来说,CelebA 数据集由香港中文大学 MMLAB 的研究人员收集,包含 202,599 张人脸图像,分别属于 10,177 位独特的名人。此外,该数据集还提供图像的面部标志和二元属性注释,这有助于定位面部特征并表示语义特征。
4.1 配置您的开发环境
要遵循本指南,您需要拥有 PyTorch 库,torchvision模块,以及matplotlib库安装在您的系统上。幸运的是,使用 pip 安装这些包非常容易:
$ pip install torch torchvision
$ pip install matplotlib如果您需要帮助配置 OpenCV 开发环境,我们强烈建议您阅读我们的pip install OpenCV指南- 它将让您在几分钟内启动并运行。
4.2 项目结构
现在我们已经讨论了 PGAN 背后的直觉和渐进式增长技术,我们准备好深入研究代码并查看我们的 PGAN 模型的实际应用。我们首先描述目录的项目结构。
→在 Google Colab 上启动 Jupyter Notebook →在 Google Colab 上启动 Jupyter Notebook
首先访问本教程的“下载”部分以检索源代码和示例图像。
我们首先了解项目目录的结构。具体来说,输出文件夹将存储从我们预先训练的 PGAN 模型和潜在空间分析生成的图像的图。
pyimagesearch文件夹中的config.py文件存储了我们代码的参数、初始设置和配置。
最后,predict.py 文件使我们能够从 Torch Hub 预训练的 PGAN 模型生成高分辨率图像,analyze.py 文件存储用于分析和遍历 PGAN 模型的潜在空间的代码。
4.3 创建配置文件
我们首先讨论 config.py 文件,其中包含我们将在教程中使用的参数配置。
# import the necessary packages
import torch
import os
# define gpu or cpu usage
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
USE_GPU = True if DEVICE == "cuda" else False
# define the number of images to generate and interpolate
NUM_IMAGES = 8
NUM_INTERPOLATION = 8
# define the path to the base output directory
BASE_OUTPUT = "output"
# define the path to the output model output and latent
# space interpolation
SAVE_IMG_PATH = os.path.join(BASE_OUTPUT, "image_samples.png")
INTERPOLATE_PLOT_PATH = os.path.sep.join([BASE_OUTPUT,
"interpolate.png"])我们首先在第 2 行和第 3 行导入必要的包。然后,在第 6 行和第 7 行,我们定义 DEVICE 和 USE_GPU 参数,这些参数确定我们将根据可用性使用 GPU 还是 CPU 来生成图像。
在第 10 行,我们定义了 NUM_IMAGES 参数,该参数定义了我们将为 PGAN 模型可视化的输出图像的数量。此外,NUM_INTERPOLATION 参数定义了我们将用于线性插值和遍历潜在空间的点数(第 11 行)。
最后,我们在第 14 行定义输出文件夹的路径(即 BASE_OUTPUT),并在第 18 和 19 行定义用于存储生成图像的相应路径(即 SAVE_IMG_PATH)和潜在空间插值图(即 INTERPOLATE_PLOT_PATH)。
4.4 使用 PGAN 模型生成图像
现在我们已经定义了配置参数,我们可以使用预先训练的 PGAN 模型生成人脸图像。
在本系列之前的教程中,我们观察了如何使用 Torch Hub 导入预训练的 PyTorch 模型并将其与我们的深度学习管道和项目无缝集成。在这里,我们将使用 Torch Hub API 的功能导入在 CelebAHQ 数据集上预训练的 PGAN 模型。
让我们打开predict.py,从我们的项目目录中获取文件并开始使用。
# USAGE
# python predict.py
# import the necessary packages
from pyimagesearch import config
import matplotlib.pyplot as plt
import torchvision
import torch
# load the pre-trained PGAN model
model = torch.hub.load("facebookresearch/pytorch_GAN_zoo:hub",
"PGAN", model_name="celebAHQ-512", pretrained=True,
useGPU=config.USE_GPU)
# sample random noise vectors
(noise, _) = model.buildNoiseData(config.NUM_IMAGES)
# pass the sampled noise vectors through the pre-trained generator
with torch.no_grad():
generatedImages = model.test(noise)
# visualize the generated images
grid = torchvision.utils.make_grid(
generatedImages.clamp(min=-1, max=1), nrow=config.NUM_IMAGES,
scale_each=True, normalize=True)
plt.figure(figsize = (20,20))
plt.imshow(grid.permute(1, 2, 0).cpu().numpy())
# save generated image visualizations
torchvision.utils.save_image(generatedImages.clamp(min=-1, max=1),
config.SAVE_IMG_PATH, nrow=config.NUM_IMAGES, scale_each=True,
normalize=True)在第 5-8 行中,我们导入必要的文件和模块,包括文件夹中的配置文件(第 5 行)和 matplotlib 库(第 6 行),以可视化生成的图像。第 7 行)使库(第 8 行)访问 PyTorch 的各种函数。
在第 11-13 行,我们使用 torch.hub.load 函数加载预配置的 PGAN 模型。请注意,该函数采用以下参数:
- 模型的存储位置。这对应于 PyTorch GAN 动物园(即 facebookresearch/pytorch_GAN_zoo:hub),它为在不同数据集上训练的各种 GAN 模型提供模型和训练权重。
- 我们打算加载的模型的名称(即 PGAN)
- 数据集名称(即 celebAHQ-512)允许我们为给定模型加载数据集特定的预训练权重。
- pretrained 参数设置为 True 时,会指示 Torch Hub API 下载所选模型的预训练权重并加载它们。
- useGPU 布尔参数表示模型是否必须加载到 GPU 或 CPU 上进行推理(由 config.USE_GPU 定义)。
既然我们选择了名人AHQ -512数据集,模型将生成维度的图像512× 512。
由于我们选择了 celebAHQ-512 数据集,因此该模型将生成尺寸为 512×512 的图像。
接下来,在第 16 行,我们使用 PGAN 模型的内置 buildNoiseData() 函数,该函数将我们打算生成的图像数量(即 config.NUM_IMAGES)作为参数,并对这些许多 512 维随机噪声进行采样。
由于我们仅使用预先训练的模型进行推理,因此我们指示 PyTorch 在 torch.no_grad() 的帮助下关闭梯度计算,如第 19 行所示。然后,我们提供随机噪声向量作为内置模型的输入。在 Torch Hub PGAN 模型的 test() 函数中,该函数通过预先训练的 PGAN 处理输入并将输出图像存储在变量 generatedImages 中(第 20 行)。
在第 23-25 行,我们使用 torchvision.utils 包的 make_grid() 函数以网格的形式绘制图像。该函数将要绘制的图像张量(即 generatedImages)、单行中显示的图像数量(即 config.NUM_IMAGES)和其他两个布尔参数(即scale_each和normalize)作为参数,其中scale和normalize张量中的图像值。
请注意,在将 generatedImages 张量传递给 make_grid 函数之前,我们将它限制在 [-1, 1] 范围内。此外,设置 normalize=True 参数会将图像移动到范围 (0, 1)。 scale_each=True 参数确保图像在实例级别缩放,而不是基于所有图像缩放。设置这些参数可确保图像在 make_grid 函数所需的特定范围内标准化,以实现结果的最佳可视化。
最后,在第 26 行和第 27 行,我们设置图形的大小并使用 matplotlib 的 imshow() 函数显示生成的图像。我们使用 torchvision.utils 模块的 save_image() 函数将输出保存在第 30-32 行 config.SAVE_IMG_PATH 定义的位置,如图所示。
图 5 显示了 PGAN 模型生成的图像。请注意,即使在 512×512 的高分辨率下,模型也可以捕获面部图像的高级结构和精细细节(例如肤色、性别、发型、表情等),从而确定特定面部的语义。

图 5:从我们的 PGAN 模型生成的图像。
4.5 行走潜在空间
我们讨论了渐进式生长技术如何帮助 PGAN 捕获图像中的高级结构和精细细节并生成高分辨率人脸。进一步分析 GAN 捕获数据分布语义的程度的一种潜在方法是遍历网络的潜在空间并分析生成图像的转换。对于已成功捕获底层数据分布的网络,图像之间的转换预计会是平滑的。具体来说,在这种情况下,估计的概率分布函数将是平滑的,并且适当的概率质量均匀地分布在分布的图像上。
预训练的 PGAN 网络是从噪声空间中的点到图像空间的确定性映射。这仅仅意味着如果一个特定的噪声向量(例如,z1)多次输入到预训练的 PGAN,它将始终输出与该特定噪声向量相对应的相同图像。
上述事实意味着,给定两个不同的噪声向量, 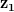 和
和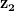 ,我们得到两个独立的输出(即图I1和I2)对应于输入向量。另外,如果我们取向量连接线上的任意点z1和z2在噪声空间中,它在图像空间中会有相应的映射。
,我们得到两个独立的输出(即图I1和I2)对应于输入向量。另外,如果我们取向量连接线上的任意点z1和z2在噪声空间中,它在图像空间中会有相应的映射。
因此,为了分析 PGAN 输出图像空间中图像之间的转换,我们在噪声潜在空间中行走。我们可以取 2 个随机噪声向量, 和,并在连接线上获取点 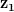 和
和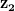 通过简单的线性插值运算:
通过简单的线性插值运算:
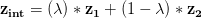
在哪里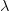 是范围内的数字( 0 , 1 ) 。最后,我们可以传递插值向量
是范围内的数字( 0 , 1 ) 。最后,我们可以传递插值向量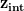 通过PGAN得到对应的图像就行连接
通过PGAN得到对应的图像就行连接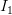 和
和 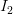 。为了行走和分析潜在空间,我们将通过改变连接噪声向量的线上的多个点来执行此操作
。为了行走和分析潜在空间,我们将通过改变连接噪声向量的线上的多个点来执行此操作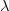 区间内的值 ( 0 , 1 ) .
区间内的值 ( 0 , 1 ) .
接下来,让我们打开analyze.py文件并在代码中实现它来分析我们的PGAN学习的结构。
# USAGE
# python analyze.py
# import the necessary packages
from pyimagesearch import config
import matplotlib.pyplot as plt
import torchvision
import numpy as np
import torch
def interpolate(n):
# sample the two noise vectors z1 and z2
(noise, _) = model.buildNoiseData(2)
# define the step size and sample numbers in the range (0, 1) at
# step intervals
step = 1 / n
lam = list(np.arange(0, 1, step))
# initialize a tensor for storing interpolated images
interpolatedImages = torch.zeros([n, 3, 512, 512])
# iterate over each value of lam
for i in range(n):
# compute interpolated z
zInt = (1 - lam[i]) * noise[0] + lam[i] * noise[1]
# generate the corresponding in the images space
with torch.no_grad():
outputImage = model.test(zInt.reshape(-1, 512))
interpolatedImages[i] = outputImage
# return the interpolated images
return interpolatedImages
# load the pre-trained PGAN model
model = torch.hub.load("facebookresearch/pytorch_GAN_zoo:hub",
"PGAN", model_name="celebAHQ-512", pretrained=True, useGPU=True)
# call the interpolate function
interpolatedImages = interpolate(config.NUM_INTERPOLATION)
# visualize output images
grid = torchvision.utils.make_grid(
interpolatedImages.clamp(min=-1, max=1), scale_each=True,
normalize=True)
plt.figure(figsize = (20, 20))
plt.imshow(grid.permute(1, 2, 0).cpu().numpy())
# save visualizations
torchvision.utils.save_image(interpolatedImages.clamp(min=-1, max=1),
config.INTERPOLATE_PLOT_PATH, nrow=config.NUM_IMAGES,
scale_each=True, normalize=True)正如我们之前看到的,我们在第 5-9行导入必要的包。在第 11-34 行,我们定义了插值函数,该函数将参数作为输入n,这是我们想要在连接两个噪声向量的线上采样的点数;并返回从我们的 GAN 模型输出的插值图像(即插值图像)。
在第 13 行,我们使用内置的 buildNoiseData() 函数对将用于插值的两个噪声向量进行采样。然后,在第 17 行,我们将定义步长(即 1/n,因为我们希望在大小为 1 的区间内均匀采样点),在第 18 行,我们使用 np.arange() 函数对点进行采样(即我们的 lambda 值)在间隔 (0, 1) 中,间隔由步骤定义。请注意,np.arange() 函数将我们想要采样的间隔的起点和终点(即 0 和 1)以及步长(即步长)作为输入。
在第 21 行,我们初始化一个张量(即 interpolatedImages),这有助于我们将输出插值存储在 GAN 的图像空间中。
从第 24 行开始,我们迭代 lam 定义的 lambda 列表中的每个值,以获得相应的插值。在第 26 行,我们使用列表 lam 中的第 i 个值,并用它来获取连接 和
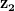 的线上相应的插值点(即噪声[0]和噪声[1]向量)。然后,在第 29-31 行,我们调用前面讨论的 torch.no_grad() 模式,并将插值后的 zInt 通过 PGAN 模型传递,以获取相应的输出图像并将其存储在 outputImage 变量中。
的线上相应的插值点(即噪声[0]和噪声[1]向量)。然后,在第 29-31 行,我们调用前面讨论的 torch.no_grad() 模式,并将插值后的 zInt 通过 PGAN 模型传递,以获取相应的输出图像并将其存储在 outputImage 变量中。
最后,我们将outputImage存储在interpolateImages张量的第i个索引处,它按顺序收集图像空间中的所有插值。最后,在第 34 行,我们返回 interpolatedImages 张量。
现在我们已经定义了 interpolation() 函数,我们准备好在潜在空间中行走并分析图像空间中相应输出的转换。
在第 37 行和第 38 行,我们从 Torch Hub 导入预训练的 PGAN 模型,如前所述。
在第 41 行,我们将 config.NUM_INTERPOLATION 参数(它定义了我们想要在连接两个噪声向量的线上采样的点数)传递给 interpolate() 函数,并将相应的输出存储在 interpolatedImages 变量中。
最后,在第 44-48 行,我们使用 make_grid() 函数和 matplotlib 库来显示插值输出,正如我们在文章前面看到的那样。我们使用 torchvision.utils 模块的 save_image() 函数将可视化保存在 config.INTERPOLATE_PLOT_PATH 定义的位置,如前面详细讨论的(第 51-53 行)。
图 6 显示了当连接 \mathbf{z_1} 和 \mathbf{z_2} 的线上的插值点通过生成器时,PGAN 图像空间中的相应输出。请注意,当我们在图中从左向右移动时,图像的过渡发生得很顺利,没有任何突然的变化。这清楚地表明 PGAN 在学习底层数据分布的语义结构方面做得很好。

图 6:与连接线上的插值点对应的图像的可视化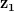 和
和 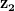 。
。
五、概括
在本教程中,我们讨论了渐进式 GAN 网络的架构细节,使其能够生成高分辨率图像。具体来说,我们讨论了渐进式增长范式,它允许 PGAN 的生成器逐渐学习生成高分辨率图像的精细细节积分。此外,我们还了解了如何使用 Torch Hub 导入预训练的 GAN 模型,并在无需深度学习项目的情况下无缝集成它们。此外,我们通过可视化生成的图像并遍历其潜在空间来看到 PGAN 网络的运行情况。
六、引文信息
Chandhok, S. “火炬中心系列 #4:PGAN”,PyImageSearch,2022 年,Torch Hub Series #4: PGAN — Model on GAN - PyImageSearch