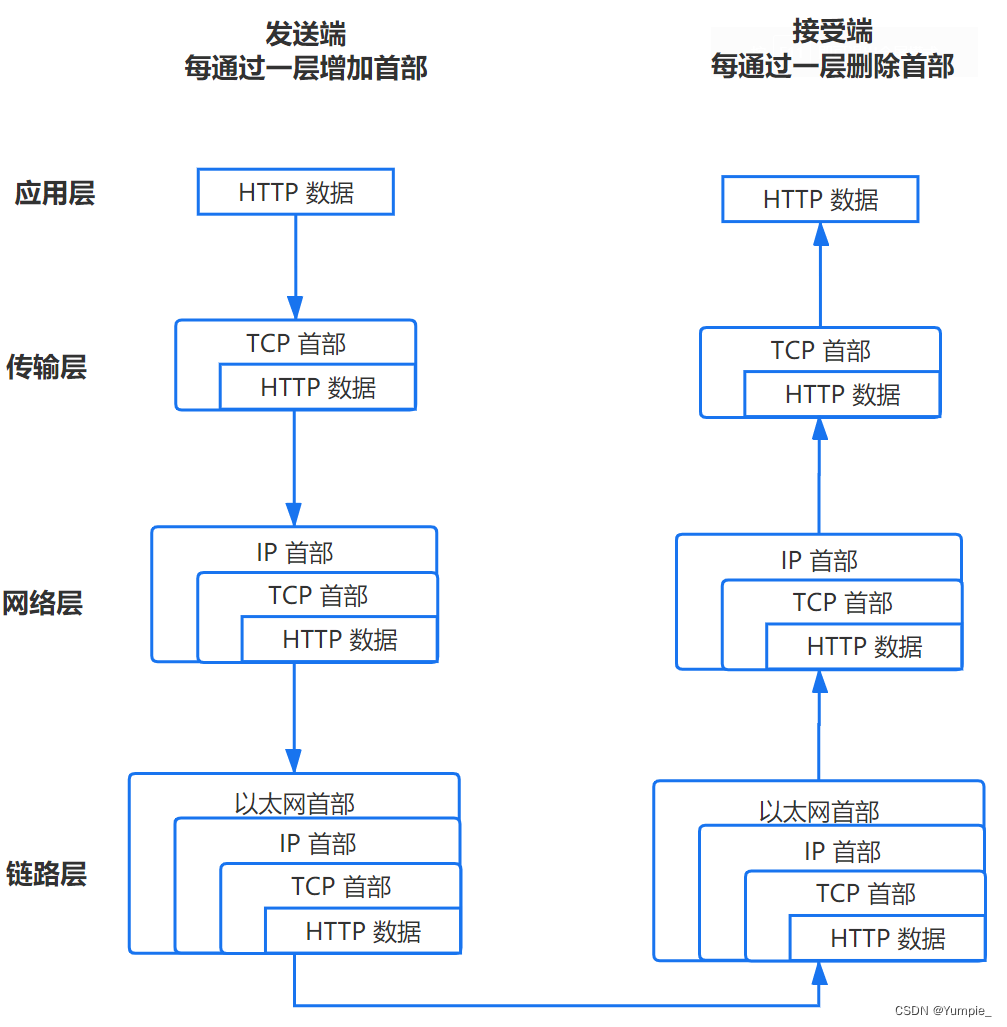
Azure Machine Learning借助对计算机视觉任务的支持,可以控制模型算法和扫描超参数。 这些模型算法和超参数将作为参数空间传入以进行扫描。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

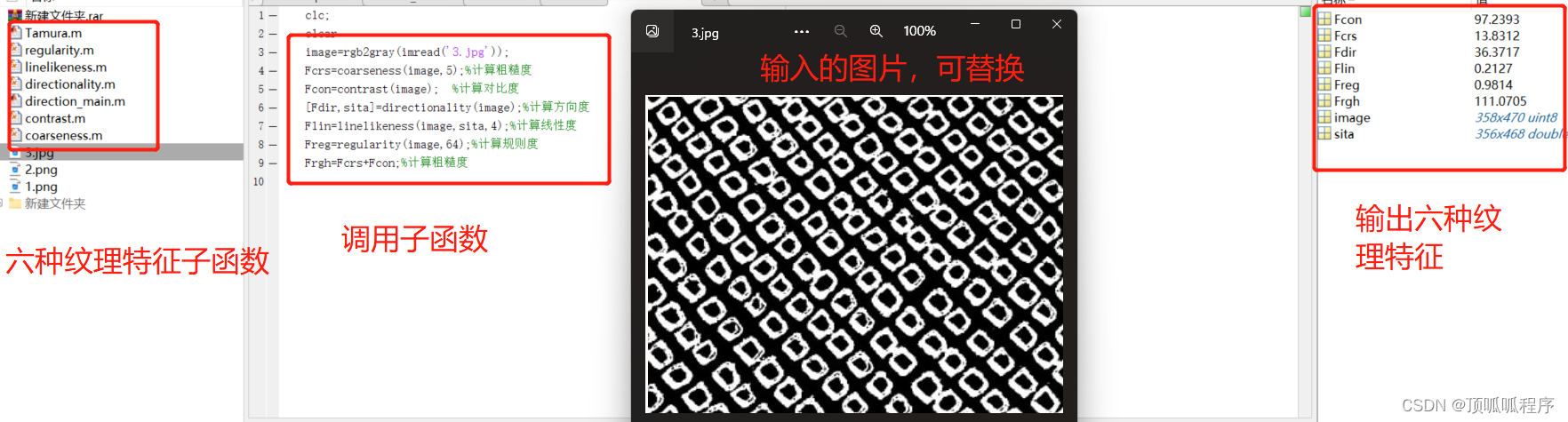
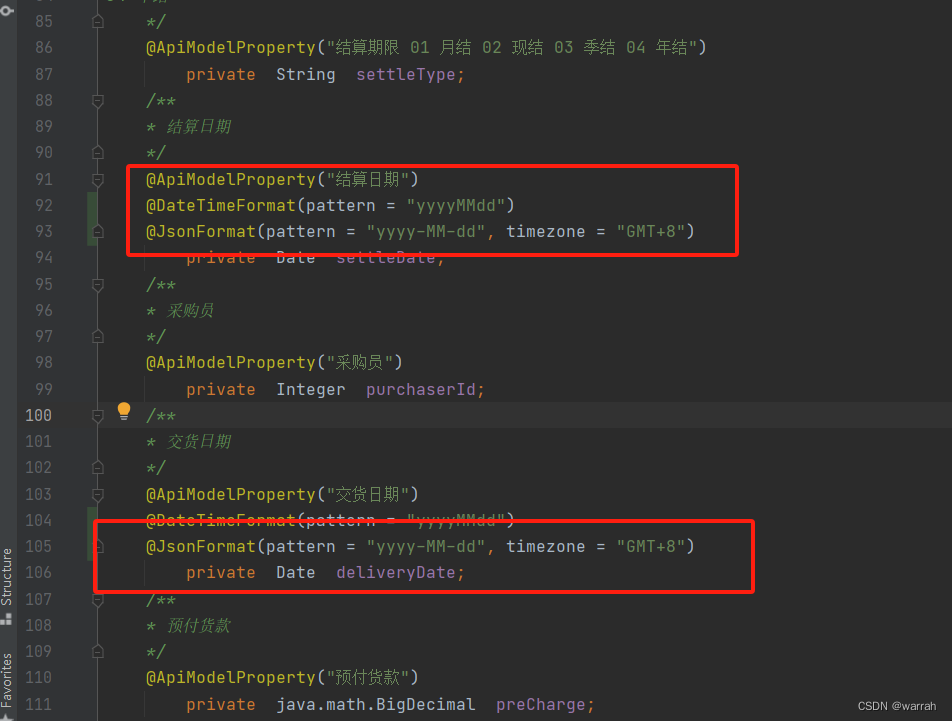
前置信息
本文适用于Azure - 机器学习:使用自动化机器学习训练计算机视觉模型 的任务中:
https://techlead.blog.csdn.net/article/details/134286386
一、Azure中特定于模型的超参数
下表汇总了特定于 yolov5 算法的超参数。
| 参数名称 | 说明 | 默认 |
|---|---|---|
validation_metric_type | 用于验证指标的指标计算方法。 | |
必须为 none、coco、voc 或 coco_voc。 | voc | |
validation_iou_threshold | 计算验证指标时框匹配的 IOU 阈值。 | |
| 必须是 [0.1, 1] 范围内的浮点数。 | 0.5 | |
img_size | 用于训练和验证的图像大小。 | |
| 必须是正整数。 | ||
| 注意:如果大小太大,训练运行可能会遇到 CUDA OOM 错误。 |
| 640 |
| model_size | 模型大小。
必须为 small、 medium、large 或 xlarge。
注意:如果模型大小太大,训练运行可能会遇到 CUDA OOM 错误。
| medium |
| multi_scale | 通过在 +/- 50% 范围内改变图像大小来启用多比例图像
必须为 0 或 1。
注意:如果 GPU 内存不足,训练运行可能会遇到 CUDA OOM 错误。
| 0 |
| box_score_thresh | 在推理期间,仅返回分数大于 box_score_thresh 的建议。 该分数是对象性分数和分类概率的乘积。
必须是 [0, 1] 范围内的浮点数。 | 0.1 |
| nms_iou_thresh | 在非最大抑制后处理中进行推理期间使用的 IOU 阈值。
必须是 [0, 1] 范围内的浮点数。 | 0.5 |
| tile_grid_size | 用于平铺每个图像的网格大小。
注意:若要启用小物体检测逻辑,tile_grid_size 不得为 None
作为字符串传递的、由两个整数构成的元组。 示例:–tile_grid_size “(3, 2)” | 无默认值 |
| tile_overlap_ratio | 每个维度中相邻图块之间的重叠率。
必须是 [0, 1) 范围内的浮点数 | 0.25 |
| tile_predictions_nms_thresh | 合并图块和图像的预测结果时用于执行 NMS 的 IOU 阈值。 在验证/推理中使用。
必须是 [0, 1] 范围内的浮点数 | 0.25 |
下表汇总了特定于 maskrcnn_* 的超参数,用于推理期间的实例分段。
| 参数名称 | 说明 | 默认 |
|---|---|---|
mask_pixel_score_threshold | 记录将像素作为部分对象掩码的临界分数。 | 0.5 |
max_number_of_polygon_points | 从掩码转换后,多边形中 (x, y) 坐标对的最大数量。 | 100 |
export_as_image | 将掩码导出为图像。 | 错误 |
image_type | 掩码导出为的图像类型(选项有 jpg、png、bmp)。 | JPG |
二、与模型无关的超参数
下表描述了与模型无关的超参数。
| 参数名称 | 说明 | 默认 |
|---|---|---|
number_of_epochs | 训练循环数。 | |
| 必须是正整数。 | 15 | |
(yolov5 除外:30) | ||
training_batch_size | 训练批大小。 | |
| 必须是正整数。 | 多类/多标签:78 | |
| (vit-variants 除外: | ||
vits16r224:128 | ||
vitb16r224:48 | ||
vitl16r224:10) | ||
| 物体检测:2 | ||
(yolov5 除外:16) |
实例分段:2
注意:默认值是可以在 12 GiB GPU 内存上使用的最大批大小。
|
| validation_batch_size | 验证批大小。
必须是正整数。 | 多类/多标签:78
(vit-variants 除外:
vits16r224:128
vitb16r224:48
vitl16r224:10)
物体检测:1
(yolov5 除外:16)
实例分段:1
注意:默认值是可以在 12 GiB GPU 内存上使用的最大批大小。
|
| grad_accumulation_step | 梯度累积是指在累积这些步骤的梯度的同时运行所配置数量的 grad_accumulation_step(不更新模型权重),然后使用累积的梯度来计算权重更新。
必须是正整数。 | 1 |
| early_stopping | 在训练期间启用提前停止逻辑。
必须为 0 或 1。 | 1 |
| early_stopping_patience | 在运行停止之前未经过主要指标
改进的最小循环数或验证评估数。
必须是正整数。 | 5 |
| early_stopping_delay | 在跟踪主要指标改进以便提前停止之前
要等待完成的最小循环数或验证评估数。
必须是正整数。 | 5 |
| learning_rate | 初始学习速率。
必须是 [0, 1] 范围内的浮点数。 | 多类:0.01
(vit-variants 除外:
vits16r224:0.0125
vitb16r224:0.0125
vitl16r224:0.001)
多标签:0.035
(vit-variants 除外:
vits16r224:0.025
vitb16r224:0.025
vitl16r224:0.002)
物体检测:0.005
(yolov5 除外:0.01)
实例分段:0.005
|
| lr_scheduler | 学习速率计划程序的类型。
必须为 warmup_cosine 或 step。 | warmup_cosine |
| step_lr_gamma | 学习速率计划程序为 step 时的 gamma 值。
必须是 [0, 1] 范围内的浮点数。 | 0.5 |
| step_lr_step_size | 学习速率计划程序为 step 时的步长大小值。
必须是正整数。 | 5 |
| warmup_cosine_lr_cycles | 学习速率计划程序为 warmup_cosine 时的余弦周期值。
必须是 [0, 1] 范围内的浮点数。 | 0.45 |
| warmup_cosine_lr_warmup_epochs | 学习速率计划程序为 warmup_cosine 时的预热循环值。
必须是正整数。 | 2 |
| optimizer | 优化器的类型。
必须为 sgd、adam 或 adamw。 | sgd |
| momentum | 优化器为 sgd 时的动量值。
必须是 [0, 1] 范围内的浮点数。 | 0.9 |
| weight_decay | 优化器为 sgd、adam 或 adamw 时的权重衰减值。
必须是 [0, 1] 范围内的浮点数。 | 1e-4 |
| nesterov | 当优化器为 sgd 时启用 nesterov。
必须为 0 或 1。 | 1 |
| beta1 | 当优化器为 adam 或 adamw 时的 beta1 值。
必须是 [0, 1] 范围内的浮点数。 | 0.9 |
| beta2 | 当优化器为 adam 或 adamw 时的 beta2 值。
必须是 [0, 1] 范围内的浮点数。 | 0.999 |
| amsgrad | 当优化器为 adam 或 adamw 时启用 amsgrad。
必须为 0 或 1。 | 0 |
| evaluation_frequency | 评估验证数据集以获得指标分数所遵循的频率。
必须是正整数。 | 1 |
| checkpoint_frequency | 存储模型检查点所遵循的频率。
必须是正整数。 | 验证时具有最佳主要指标的循环中的检查点。 |
| checkpoint_run_id | 具有用于增量训练的预训练检查点的试验的运行 ID。 | 无默认值 |
| checkpoint_dataset_id | FileDataset ID,其中包含用于增量训练的预训练检查点。 确保将 checkpoint_filename 与 checkpoint_dataset_id 一起传递。 | 无默认值 |
| checkpoint_filename | FileDataset 中用于增量训练的预训练检查点文件名。 确保将 checkpoint_dataset_id 与 checkpoint_filename 一起传递。 | 无默认值 |
| layers_to_freeze | 要为模型冻结的层数。 例如,传递 2 作为 seresnext 值意味着冻结引用下面的受支持模型层信息的 layer0 和 layer1。
必须是正整数。
'resnet': [('conv1.', 'bn1.'), 'layer1.', 'layer2.', 'layer3.', 'layer4.'],
'mobilenetv2': ['features.0.', 'features.1.', 'features.2.', 'features.3.', 'features.4.', 'features.5.', 'features.6.', 'features.7.', 'features.8.', 'features.9.', 'features.10.', 'features.11.', 'features.12.', 'features.13.', 'features.14.', 'features.15.', 'features.16.', 'features.17.', 'features.18.'],
'seresnext': ['layer0.', 'layer1.', 'layer2.', 'layer3.', 'layer4.'],
'vit': ['patch_embed', 'blocks.0.', 'blocks.1.', 'blocks.2.', 'blocks.3.', 'blocks.4.', 'blocks.5.', 'blocks.6.','blocks.7.', 'blocks.8.', 'blocks.9.', 'blocks.10.', 'blocks.11.'],
'yolov5_backbone': ['model.0.', 'model.1.', 'model.2.', 'model.3.', 'model.4.','model.5.', 'model.6.', 'model.7.', 'model.8.', 'model.9.'],
'resnet_backbone': ['backbone.body.conv1.', 'backbone.body.layer1.', 'backbone.body.layer2.','backbone.body.layer3.', 'backbone.body.layer4.']
| 无默认值 |
三、图像分类(多类和多标签)特定的超参数
下表汇总了图像分类(多类和多标签)任务的超参数。
| 参数名称 | 说明 | 默认 |
|---|---|---|
weighted_loss | 0 表示无加权损失。 | |
| 1 表示使用 sqrt.(class_weights) 计算的加权损失 | ||
| 2 表示使用 class_weights 计算的加权损失。 | ||
| 必须为 0、1 或 2。 | 0 | |
valid_resize_size | - 在为验证数据集裁剪之前要将图像调整到的大小。 |
-
必须是正整数。
说明:
-
seresnext不取任意大小。 -
注意:如果大小太大,训练运行可能会遇到 CUDA OOM 错误。 | 256 |
|valid_crop_size| - 输入到神经网络的用于验证数据集的图像裁剪大小。 -
必须是正整数。
说明:
-
seresnext不取任意大小。 -
ViT-variants 应该拥有相同的
valid_crop_size和train_crop_size。 -
注意:如果大小太大,训练运行可能会遇到 CUDA OOM 错误。 | 224 |
|train_crop_size| - 输入到神经网络的用于训练数据集的图像裁剪大小。 -
必须是正整数。
说明:
-
seresnext不取任意大小。 -
ViT-variants 应该拥有相同的
valid_crop_size和train_crop_size。 -
注意:如果大小太大,训练运行可能会遇到 CUDA OOM 错误。 | 224 |
四、对象检测和实例分段任务特定的超参数
以下超参数用于物体检测和实例分段任务。
警告
yolov5 算法不支持这些参数。 有关 yolov5 支持的超参数,请参阅模型特定的超参数部分。
| 参数名称 | 说明 | 默认 |
|---|---|---|
validation_metric_type | 用于验证指标的指标计算方法。 | |
必须为 none、coco、voc 或 coco_voc。 | voc | |
validation_iou_threshold | 计算验证指标时框匹配的 IOU 阈值。 | |
| 必须是 [0.1, 1] 范围内的浮点数。 | 0.5 | |
min_size | 在将图像馈送到主干之前要将其重新缩放到的最小大小。 | |
| 必须是正整数。 | ||
| 注意:如果大小太大,训练运行可能会遇到 CUDA OOM 错误。 |
| 600 |
| max_size | 在将图像馈送到主干之前要将其重新缩放到的最大大小。
必须是正整数。
注意:如果大小太大,训练运行可能会遇到 CUDA OOM 错误。
| 1333 |
| box_score_thresh | 在推理期间,仅返回分类分数大于 box_score_thresh 的建议。
必须是 [0, 1] 范围内的浮点数。 | 0.3 |
| nms_iou_thresh | 预测头的非最大抑制 (NMS) 中使用的 IOU(交并比)阈值。 在推理期间使用。
必须是 [0, 1] 范围内的浮点数。 | 0.5 |
| box_detections_per_img | 所有类的每个图像的最大检测次数。
必须是正整数。 | 100 |
| tile_grid_size | 用于平铺每个图像的网格大小。
注意:若要启用小物体检测逻辑,tile_grid_size 不得为 None
作为字符串传递的、由两个整数构成的元组。 示例:–tile_grid_size “(3, 2)” | 无默认值 |
| tile_overlap_ratio | 每个维度中相邻图块之间的重叠率。
必须是 [0, 1) 范围内的浮点数 | 0.25 |
| tile_predictions_nms_thresh | 合并图块和图像的预测结果时用于执行 NMS 的 IOU 阈值。 在验证/推理中使用。
必须是 [0, 1] 范围内的浮点数 | 0.25 |
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。