OpenAI第一代文本生成图片模型
paper:https://arxiv.org/abs/2102.12092
DALL·E有120亿参数,基于自回归transformer,在2.5亿 图片-文本对上训练的。实现了高质量可控的text to image,同时也有zero-shot的能力。
DALL-E没有使用扩散模型,而是dVAE(discrete variational autoencoder离散变分自动编码器)。文中主要和GAN相关模型进行比较,如AttnGAN、DM-GAN、DF-GAM。
1. 介绍
自回归式的模型处理图片的时候,如果直接把像素拉成序列,当成image token来处理,如果图片分辨率过高,一方面会占用过多的内存,另一方面Likelihood的目标函数会倾向于建模短程的像素间的关系,因而会学到更多的高频细节,而不是更能被人辨认的低频结构。
与 GPT-3 一样,DALL·E是一个 Transformer 语言模型。它将文本和图像作为单个数据序列接收,通过Transformer进行自回归。
Zero-Shot:对于GPT-3来说,我们可以指示它仅根据描述和提示执行多种任务,来生成我们想要的答案,而无需任何额外的培训。例如,当提示“here is the sentence 'a person walk his dog in the park' translated into French: ”时,GPT-3 会回答“un homme qui promène son chien dans le parc”。这种能力称为零样本推理。研究者发现 DALL·E 将这种能力扩展到了视觉领域,在以正确的方式提示时,它能够执行多种图像到图像的转换工作。比如最直接的方法是输入一张照片,然后用文本描述“粉红色的照片”或“倒影的照片”,这也往往是最可靠的,尽管照片通常没有被完美地复制或反映,但也从一定程度上表明这个功能有望实现。实现图像版GPT-3。
功能一,创造拟人的器具

功能二,Dall-E能够很聪明地捕捉到每个事物的特性,并且合理地组织在了一起。

功能三,根据文本自动渲染真实场景图片,其仿真程度与真实照片十分接近

功能四,根据文本指令改变和转换现有图片风格。
 不同于GAN(生成式对抗网络)的一点是,虽然GAN能够替换视频里的人脸,但其仅仅限制于人脸的范畴,而Dalle是将概念和概念之间做了关联,这在以往也是从未被实现过的。
不同于GAN(生成式对抗网络)的一点是,虽然GAN能够替换视频里的人脸,但其仅仅限制于人脸的范畴,而Dalle是将概念和概念之间做了关联,这在以往也是从未被实现过的。
2. 方法
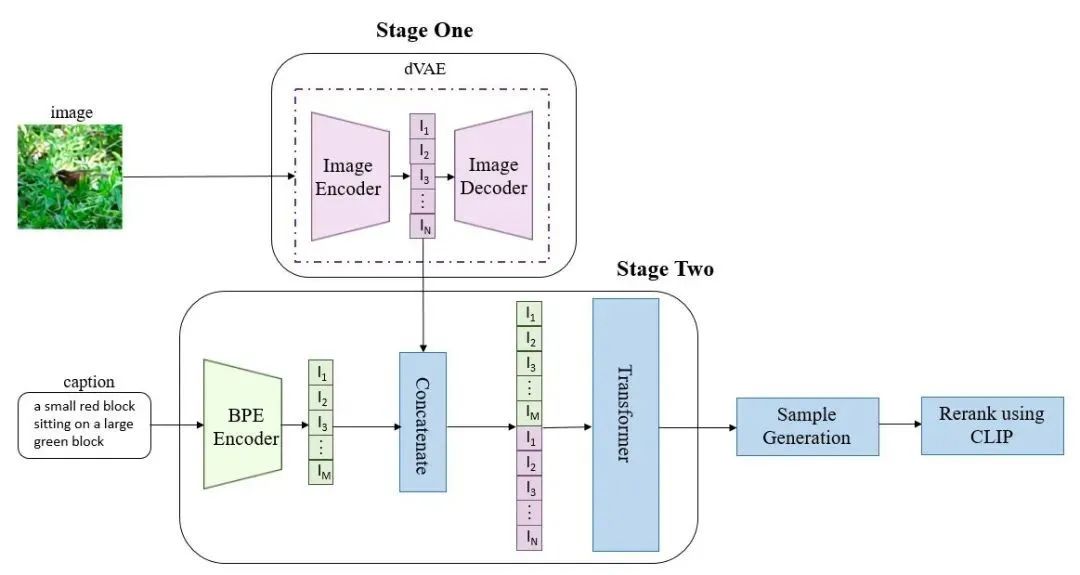
整体流程如下:
1.第一个阶段,训练一个dVAE(discrete variational autoencoder离散变分自动编码器),其将256*256的RGB图片转换为32*32的图片token。目的:降低图片的分辨率,从而解决计算量的问题。图片token的词汇量大小是8192个,即每个位置有8192种可能的取值(也就是说dVAE的encoder输出是维度为32x32x8192的logits,然后通过logits索引codebook的特征进行组合,codebook的embedding是可学习的)。第一阶段同时训练dVAE编码器和dVAE解码器。
2.第二阶段,用BPE Encoder对文本进行编码,得到最多256个文本token,token数不满256的话padding到256,然后将256个文本token与1024个图像token(32*32=1024)进行拼接,得到长度为1280的数据,用拼接的数据去训练一个自回归transformer来建模文本和图片token的联合分布。

3.最后的推理阶段,给定一张候选图片和一条文本,通过transformer可以得到融合后的token,然后用dVAE的decoder生成图片,最后通过预训练好的CLIP计算出文本和生成图片的匹配分数,得到不同采样图片的分数排序,最终找到跟文本最匹配的图片。
从以上流程可知,dVAE、Transformer和CLIP三个模型都是不同阶段独立训练的。下面讲一下dVAE、Transformer和CLIP三个部分。
3. 组成
3. 1 dVAE
由于图像特征的密集性和冗余性,不能直接提供给Transformer进行训练。目前主流的方式,例如ViT,Swin-Transformer等都是将图像的Patch作为模型的输入,然后通过一个步长等于Patch大小的大卷积核得到每个Patch的特征向量。
DALL-E提供的方案是使用离散的变分自编码器(dVAE)将大小为256x256的RGB图像压缩到大小为32x32的,通道数为8192的one-hot token的分布,变分自编码器的架构如图2所示。换句话说,阶段1的作用是将图像映射到一个大小为8192的图表中。这里通道数为8192的one-hot向量可以看做是一个词表,它的思想是通过离散VAE,实现图像特征空间想文本特征空间的映射。
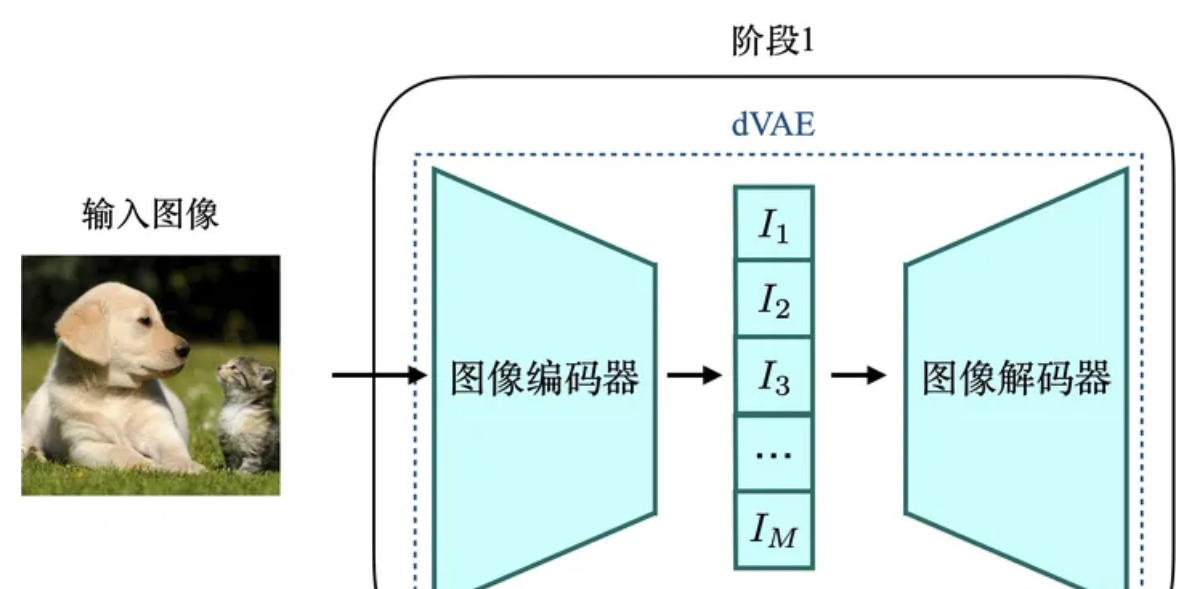
不同于AE的是,VAE的预测不再是一个值,而是一个分布,通过在分布上的随机采样便可以解码成不同的生成内容。给定一个输入x,VAE的编码器的输出应该是特征z的后验分布![]() 。
。
VQVAE:
通过Encoder学习出中间编码,然后通过最邻近搜索将中间编码映射为codebook中K个向量之一,然后通过Decoder对latent code进行重建。
另外由于最邻近搜索使用argmax来找codebook中的索引位置,导致不可导问题,VQVAE通过stop gradient操作来避免最邻近搜索的不可导问题,也就是latent code的梯度跳过最近邻搜索直接复制到中间编码上。
VQVAE相比于VAE最大的不同是,直接找每个属性的离散值,通过类似于查表的方式,计算codebook和中间编码的最近邻作为latent code。由于维护了一个codebook,编码范围更加可控,VQVAE相对于VAE,可以生成更大更高清的图片(这也为后续DALLE和VQGAN的出现做了铺垫)。

作用:
dVAE主要用来为图像的每个patch生成token表示,这次openAI开出的代码就是dVAE的推理代码。dVAE的encoder和decoder的机构较为简单,都是由bottleneck-style的resblock组成,相比于普通的VAE,dVAE有两点区别:
1.和VQVAE方法相似,dVAE的encoder是将图像的patch映射到8192的词表中,论文中将其分布设为在词表向量上的均匀分类分布,这是一个离散分布,由于不可导,此时不能采用重参数技巧,DALL·E使用Gumbel Softmax trick来解决这个问题。
2、在重建图像时,真实的像素值是在一个有界区间内,而VAE中使用的Gaussian分布和Laplace分布都是在整个实数集上,这造成了不匹配的问题。为了解决这个问题,论文中提出了logit-Laplace分布,如下式所示:
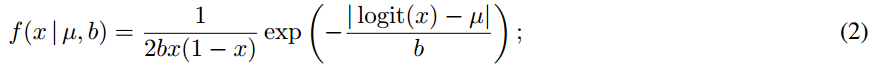
3.2 Transformer
Dall-E中的Transformer结构由64层attention层组成,每层的注意力头数为62,每个注意力头的维度为64,因此,每个token的向量表示维度为3968。如图2所示,attention层使用了行注意力mask、列注意力mask和卷积注意力mask三种稀疏注意力。

图2 Transformer使用的3种稀疏注意力
训练方法是用seq2seq的方法,用前面的序列预测下一个token,结合上mask的设计,可以实现行预测或者列预测。
Transformer的输入如图3所示,其中pad embd通过学习得到,根据论文介绍,为每个位置都训练了一个pad embd,即256个pad embd,在对文本token进行pad时,使用对应位置的pad embd。

图3 Transformer输入示意图(假设文本最大长度6)
训练目标:采用Evidence Lower BOund (ELBO,推导详见文章最下面)。如下: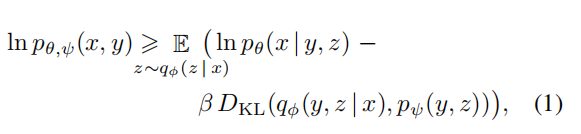
x指图片,y指文本,z指对编码的图片(用于生成图片)。

3.3 CLIP
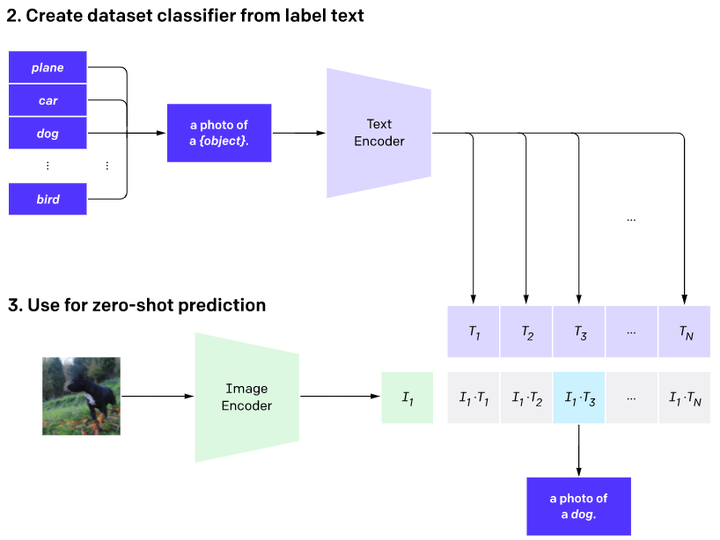
CLIP的推理过程:
1.先将预训练好的CLIP迁移到下游任务,如图(2)所示,先将下游任务的标签构建为一批带标签的文本(例如 A photo of a {plane}),然后经过Text Encoder编码成一批相应的word embedding。
2.然后将没有见过的图片进行zero-shot预测,如图(3)所示,通过Image Encoder将一张小狗的图片编码成一个feature embedding,然后跟(2)编码的一批word embedding先归一化然后进行点积,最后得到的logits中数值最大的位置对应的标签即为最终预测结果。
在DALL·E中,CLIP的用法跟上述过程相反,提供输入文本和一系列候选图片,先通过Stage One和Stage Two生成文本和候选图片的embedding,然后通过文本和候选图片的匹配分数进行排序,最后找到跟文本最匹配的图片。
总结:总的来说,目前公开的DALL-E的实现在模型结构上并没有太多创新,而是合理利用了现有的模型结构进行组合,并采用了一些trick解决了遇到的问题,从而在大数据集上训练得到超大规模的模型,取得了令人惊艳的效果,这也符合openAI的一贯风格。但无论如何,DALL-E在深度学习能力边界探索的道路上又前进了一步,也再一次展示了大数据和超大规模模型的魅力。美中不足的是,DALL-E包含了三个模块,更像是一个pipeline,而对于普通的研究者来说,要运行这样一个复杂的大规模模型是一件很困难的事情。
参考:DALL·E: Zero-Shot Text-to-Image Generation - 知乎
如何评价DALL-E模型的实现? - 知乎