一、Spark是什么
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。是专门为大数据处理而设计的通用的计算引擎。
二、Spark需要运行的环境
Spark需要scala作为运行环境
三、下载scala,并且配置环境变量
Scala官网:Install | The Scala Programming Language。注意对应的版本
配置scala的环境变量,在path中输入对应的地址

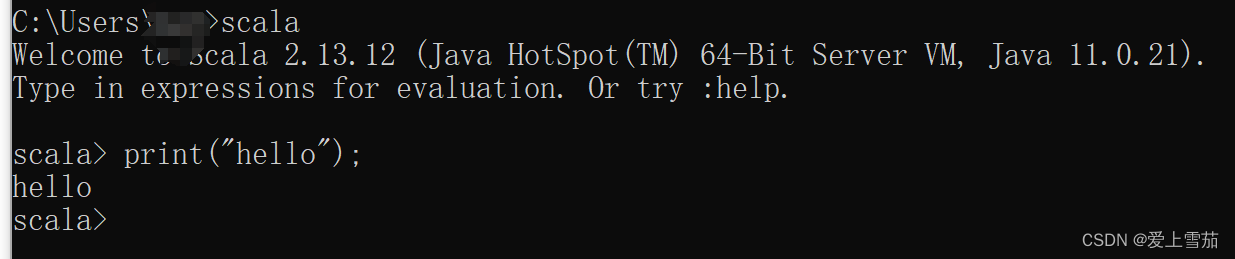
配置成功后,在cmd中执行scala
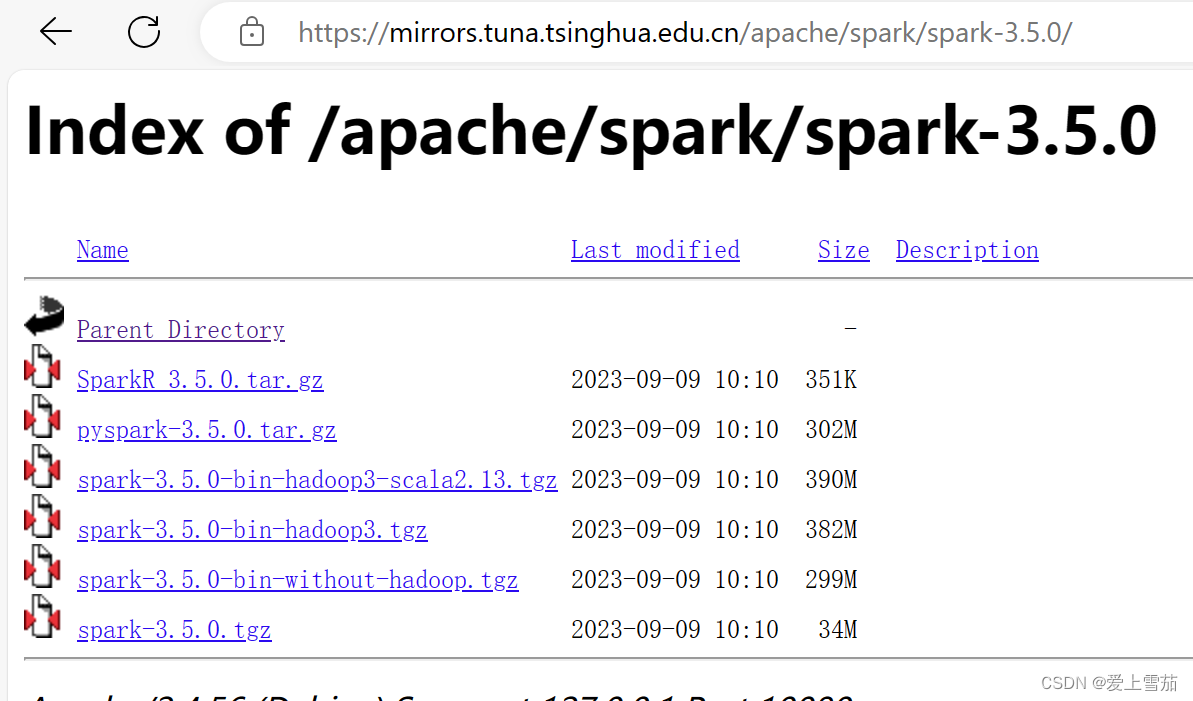
四、下载Spark,我们在清华的镜像网站下载
配置spark的环境变量
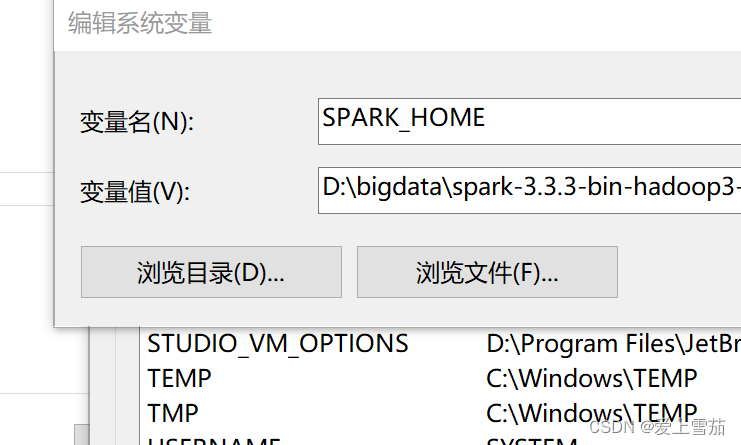
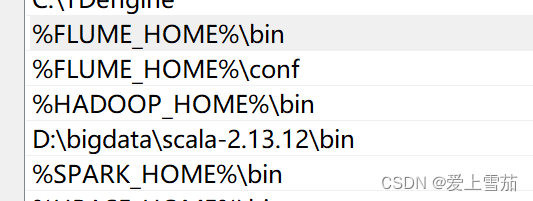
配置完成环境变量之后,就可以启动spark了。
在spark的bin下面执行spark-shell.cmd
在浏览器中输入下面的url就可以看到对应启动的界面,执行任务的时候可以看到任务作业
http://192.168.1.103:4040/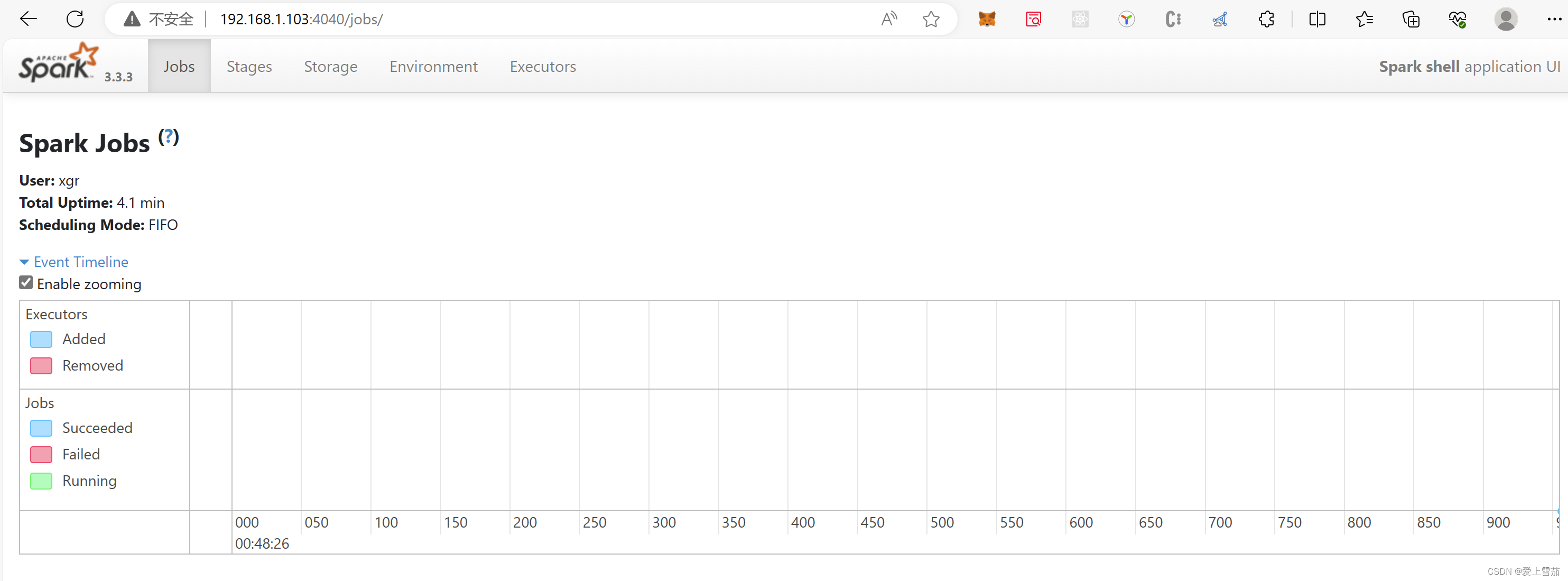


![[架构之路-246]:目标系统 - 设计方法 - 软件工程 - 需求工程- 需求开发:获取、分析、定义、验证](https://img-blog.csdnimg.cn/24c3d7fd670c4e8fb18a9fd57ecbb487.png)