NiFi 中的重要术语
- 1.Flow Controller
- 2.Processor
- 3.Connection
- 4.Controller Service
- 5.Process Group
- 6.FlowFile
那些一个个黑匣子称为 Processor,它们通过称为 Connection 的队列交换名为 FlowFile 的信息块。最后,FlowFile Controller 负责管理这些组件之间的资源。

1.Flow Controller
在 NIFI 的代码架构设计中有一个模块叫 Extension,这个模块里包含了以下我们说的 Processor、Controller Service 等等可扩展的部分。Flow Controller 是将一切融合在一起的粘合剂。它为处理器分配和管理线程。

2.Processor
处理器是执行操作的黑匣子。处理器可以访问 FlowFile 的属性和内容来执行所有类型的操作。它们使你能够在数据输入,标准数据转换 / 验证任务中执行许多操作,并将这些数据保存到各种数据接收器。

3.Connection
Connection 是处理器之间的队列。这些队列允许处理器以不同的速率进行交互,就像存在不同尺寸的水管。 Connection 可以具有不同的容量。

如果 FlowFiles 的数量或数据量超过定义的阈值,则将触发背压机制(backpressure)。在队列中没有空间之前,Flow Controller 不会安排 Connection 上游的处理器再次运行。
4.Controller Service
例如数据库连接池或云服务提供商凭据。Controller Service 是守护进程(daemons)。它们在后台运行,并提供配置,资源和参数供处理器执行。

5.Process Group
一堆处理器及其连接可以组成一个 Process Group。你添加了一个 Input Port 和一个 Output Port,以便 Process Group 可以接收和发送数据。

6.FlowFile

FlowFile 分为两个部分:
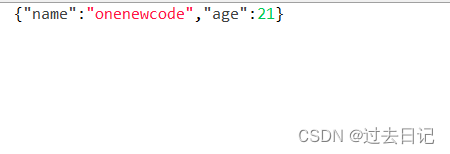
Attributes:即键 / 值对。例如,文件名,文件路径和唯一标识符是标准属性。Content:对字节流的引用构成了FlowFile内容。
FlowFile 不包含数据本身,否则会严重限制 pipeline 的吞吐量。相反,FlowFile 保留的是一个指针,该指针引用存储在本地存储中某个位置的数据。这个地方称为 内容存储库(Content Repository)。

当处理器修改 FlowFile 的内容时,将保留先前的数据。NIFI 的 copies-on-write 机制会在将内容复制到新位置时对其进行修改。原始信息保留在内容存储库中。








![[云原生2. ] Kubernetes的简单介绍](https://img-blog.csdnimg.cn/38874a0348984d20a50f70362cafd634.png)