经过一段时间的积累,搭建的分析平台已经日渐进入稳定的状态,很多粉丝也在和我们反馈,让我们出一下零代码生信套路课。
小编找了很久,发现某某机构出的TCGA联合GEO 免疫基因+代谢基因的生信套路,该套路应用常见相对来说比较广,又属于双热点套路。但是代码运行真的是太麻烦了,还有各种各样的报错,实在是不好弄,为此,我们推出了复现课程,该课程内容较长, 分成几篇进行讲解,如带来不便,请大家谅解!
一、TCGA数据的下载和预处理
这里通过生信豆芽菜官网可以直接下载TCGA的数据,比如这里我们以LUAD数据为例,
http://www.sxdyc.com/tcgaDataSet
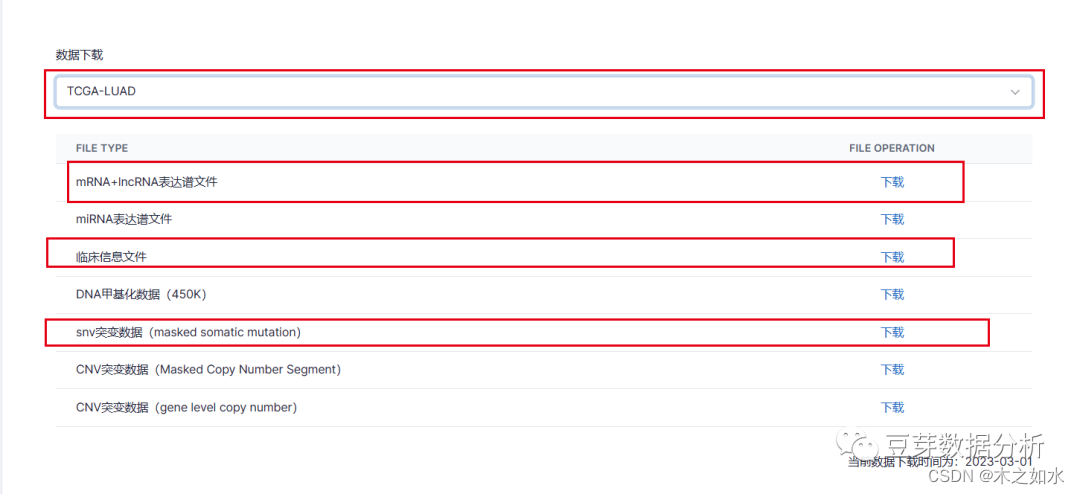
下载后放在文件夹1.TCGA.pre下面
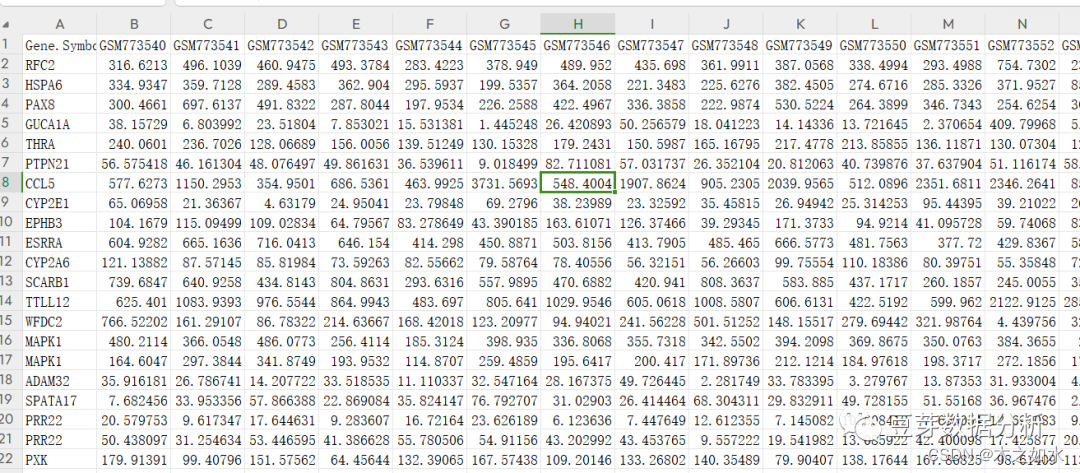
用excel打开TCGA.merge.cli.txthe tcga.merge.mRNA.TPM.txt的文件
1、整理表达谱数据
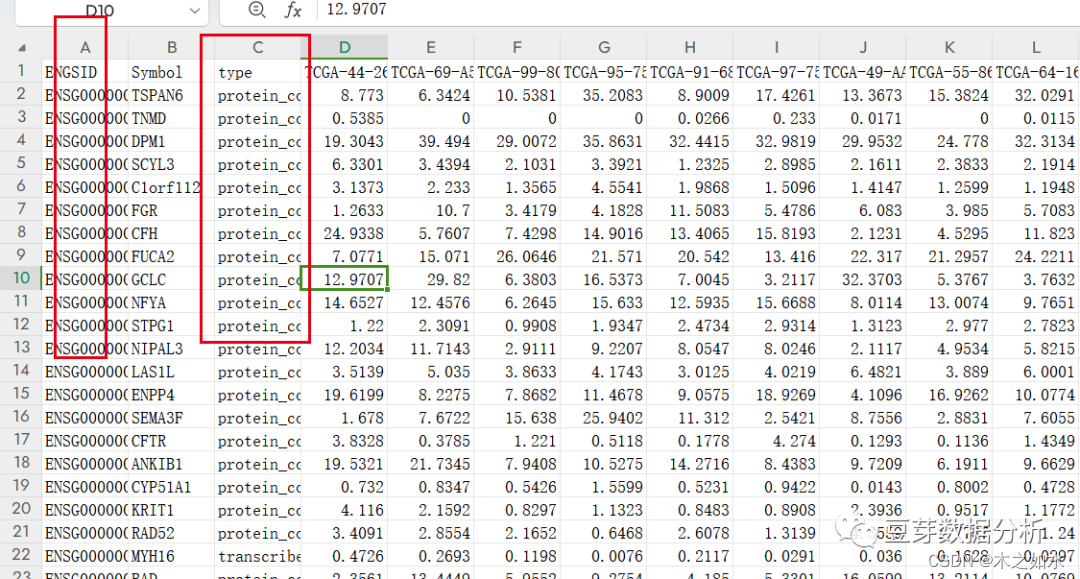
A列的数据为基因ENSG号,可以直接删掉,C列的数据需要注意,代表了基因的类型,比如说这里选择蛋白编码的基因,将其他类型的全部删掉
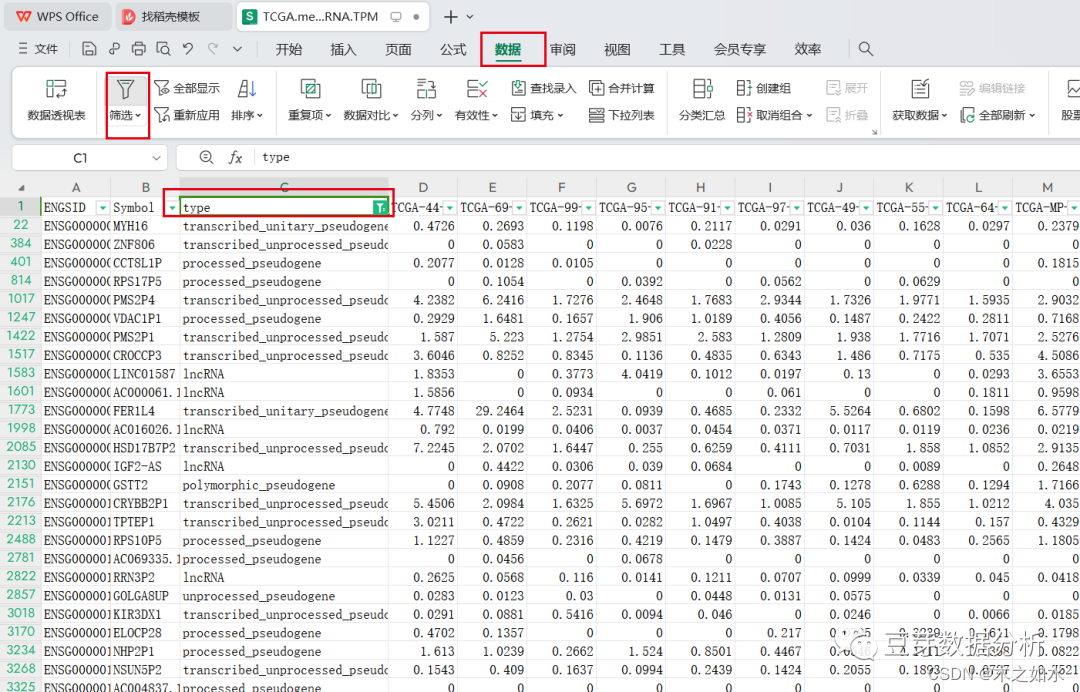
选择数据-筛选-将protein_coding的 基因保留下来,如果这里需要分析lncRNA,就单独只保留lncRNA

这时候,删掉A和C列的数据
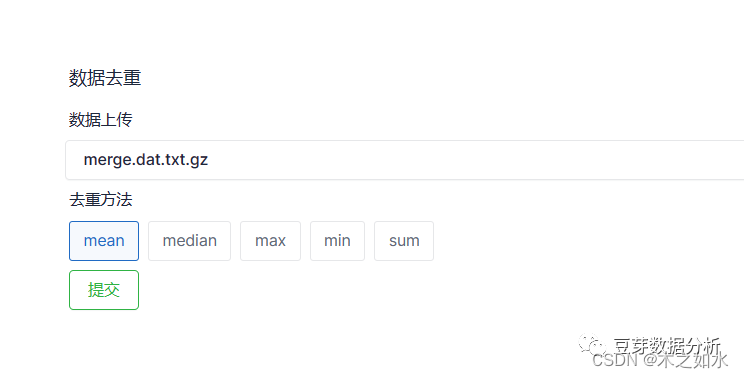
将数据保存后,这里出来后的数据很容易出现重复的基因,所以可以使用我们的去重工具
http://www.sxdyc.com/singleCollectionTool?href-preprocess
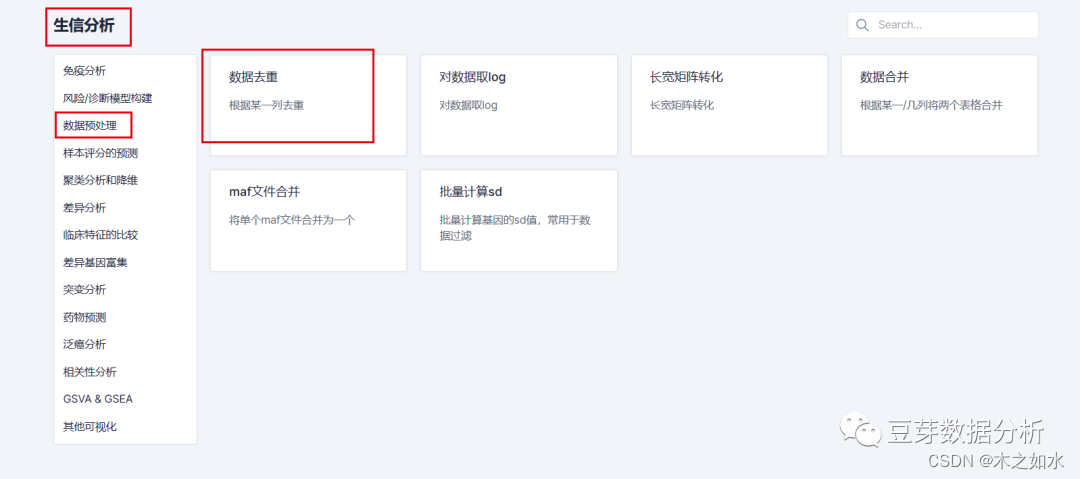
选择去重工具,上传刚刚处理好的TCGA的表达谱数据,并选择去重的方法,等待运行结束即可。
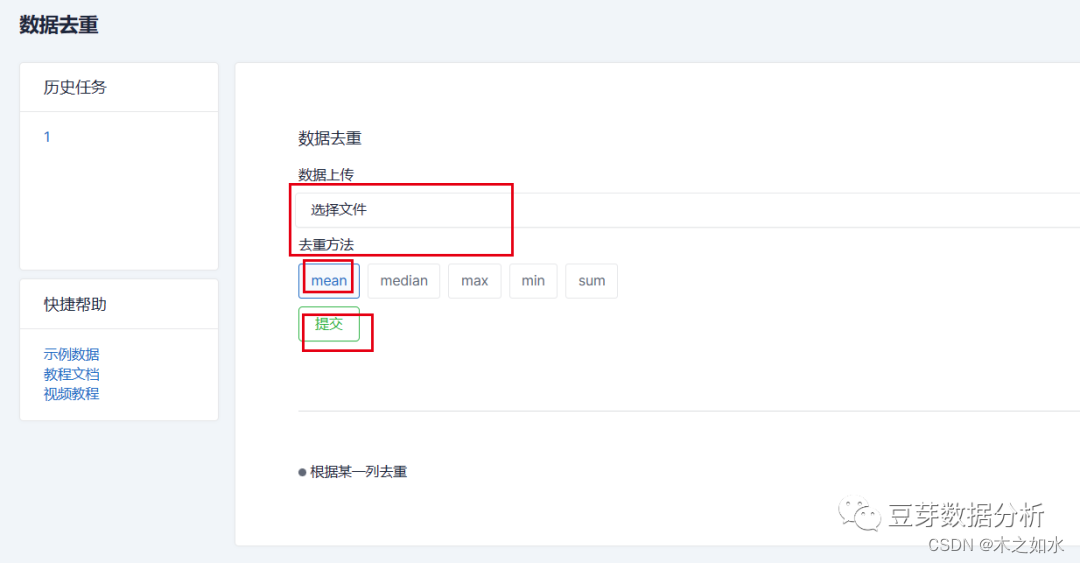
当然如果文件过大,可以选择7-zip进行压缩,将文件压缩为.gz的格式
2、整理生存数据
打开文件后,先删掉后面无用的列名信息,去重
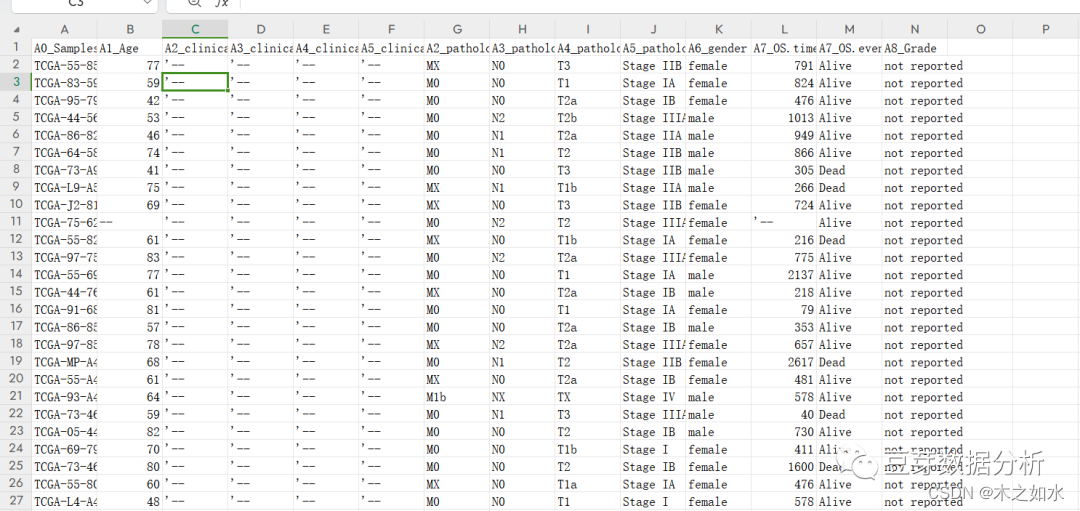
替换字符
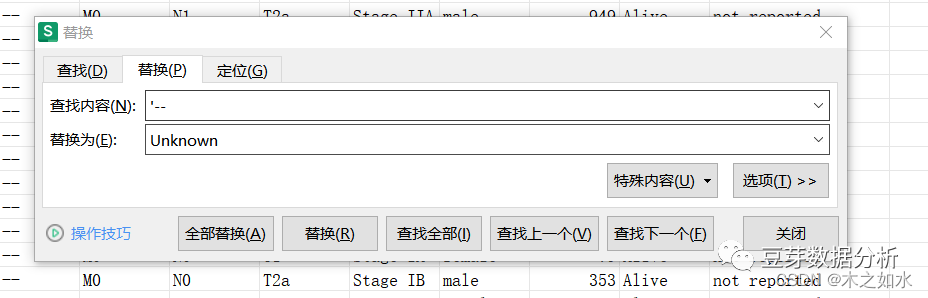
去掉缺少生存时间和生存状态的样本
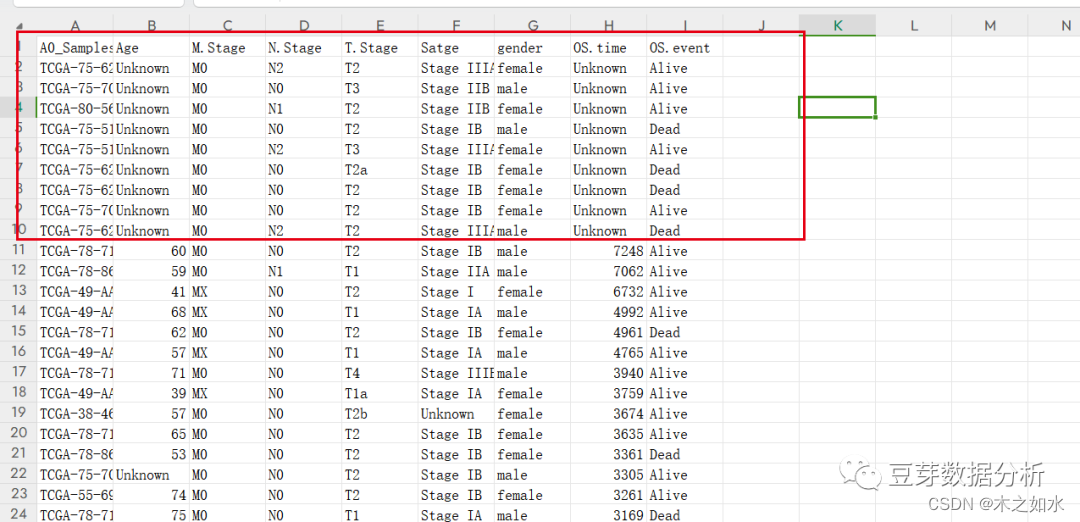
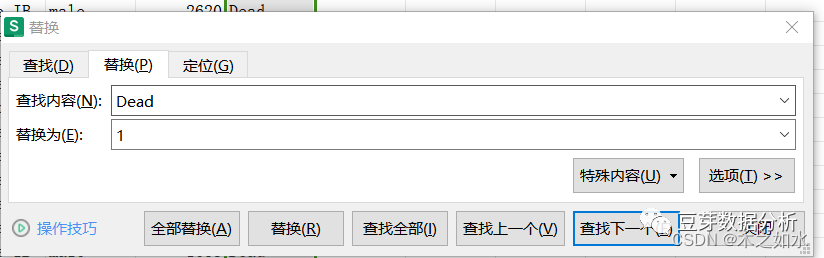
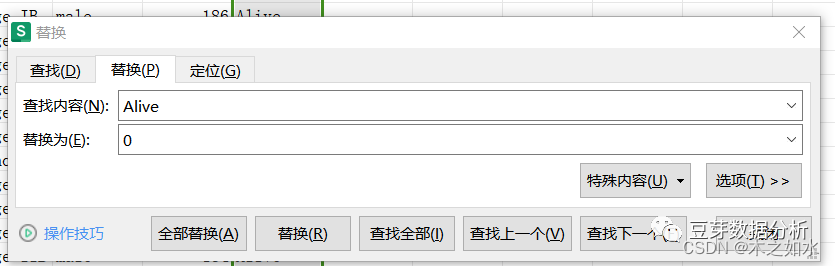
最后保存数据即可
二、GEO数据的下载和预处理
1、从NCBI的GEO dataset官网查找合适的GEO的数据集,可以通过关键词进行查找,也可以通过已经发表的文章进行筛选。
(https://www.ncbi.nlm.nih.gov/)

通过一些关键词进行搜索。
比如这里选择GSE31210,怎么下载呢
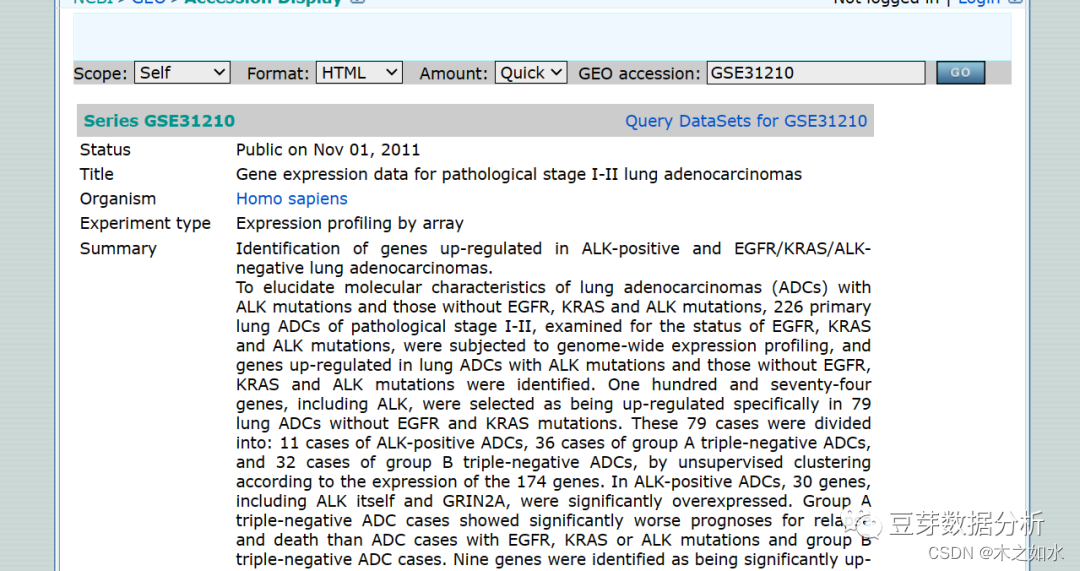
往下滑动,选择platforms(平台注释文件)和矩阵文件
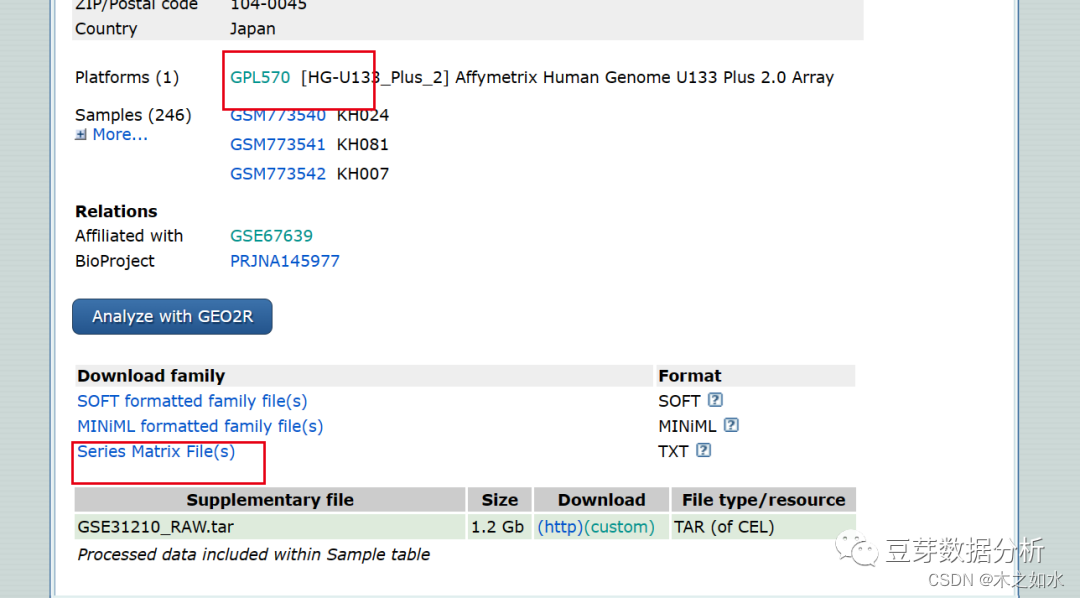

2、表达谱数据和临床数据的处理
对GSE31210_series_matrix.txt.gz文件进行解压,然后excel打开

这一部分为样本的表型数据,有时候,表型的临床是存在原文的附件中。
表达谱的数据,这些信息都要删掉,同时拉到最后,将最后一行删掉。
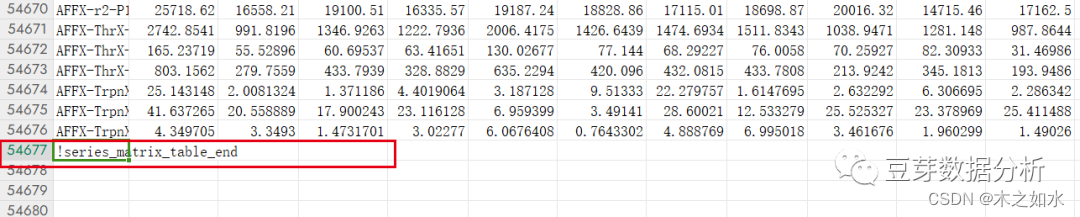
然后保存一下数据
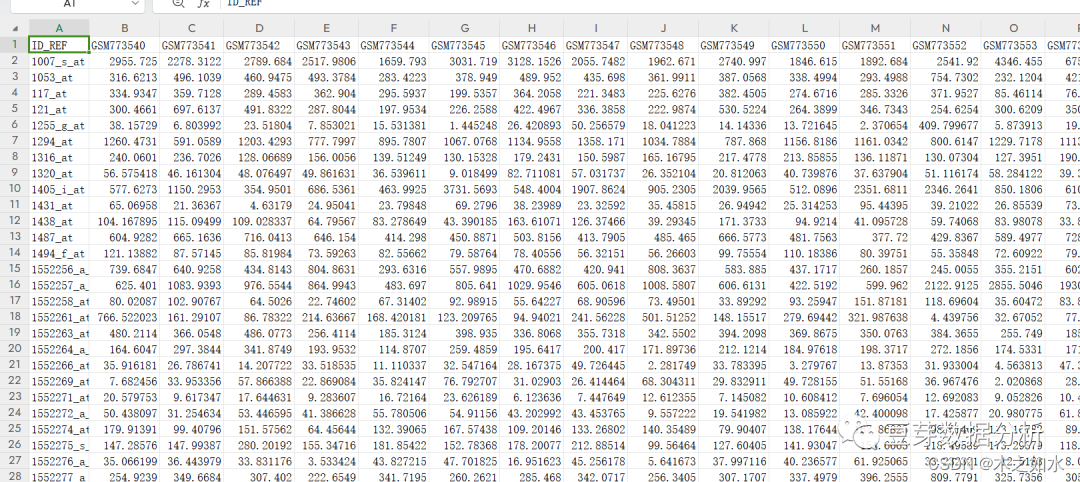
3、注释信息的准备
删掉多余的行和列,去掉一个探针对应多个基因名
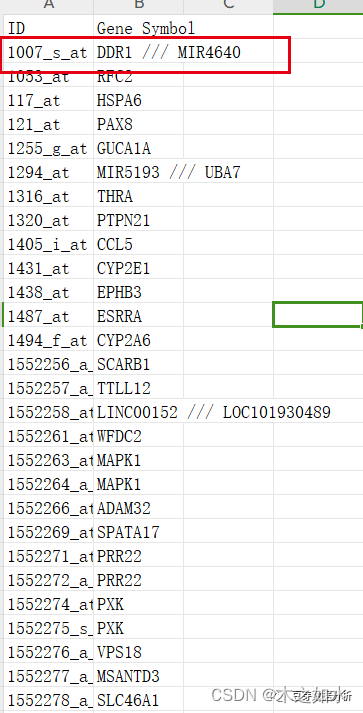
选择筛选-包含-///,将这些行全部删掉。
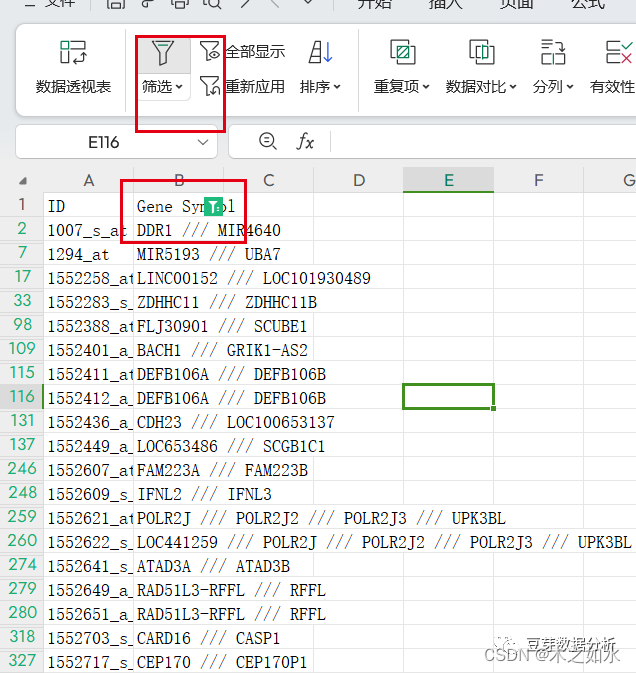
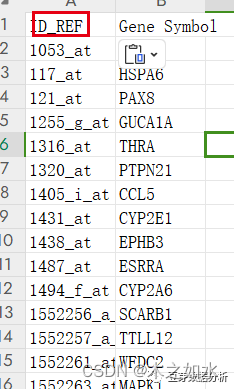
合并数据
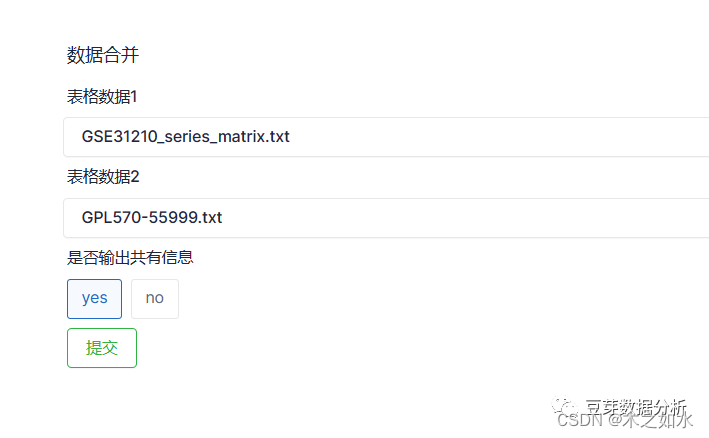
运行完成后
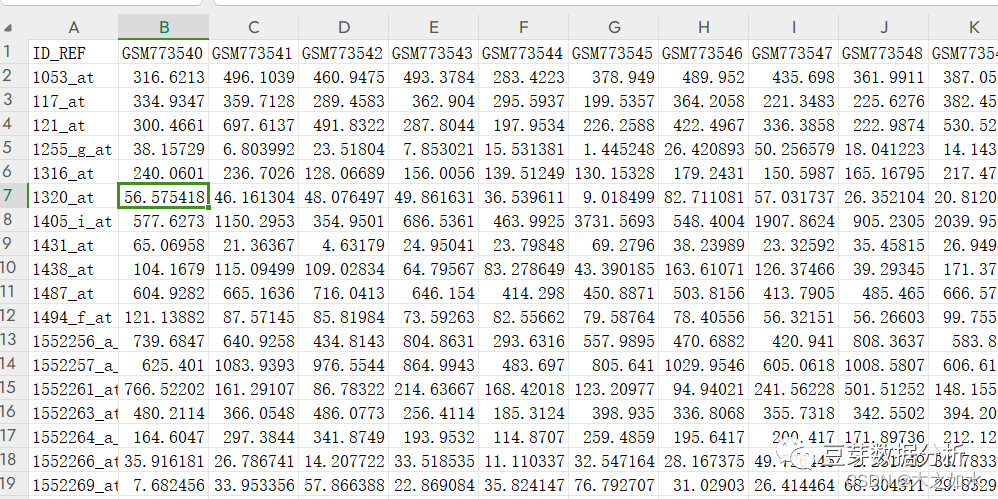
在最后一列,有基因的名字,直接剪切粘贴到A列
这时候保存一下,再用去重工具,去一下重复的基因,在前面处理的时候,我们将一个探针对应多个基因的去掉了,那么这里的基因重复就是多个探针对应一个基因名,可以选择去重方法进行去重,这里就省略了
到这里数据的准备阶段基本就做完了,需要注意的是,在分析的过程中药注意基因的表达,相差大的,可以取一个log进行后续的分析。










![[SSD综述1.7] SSD接口形态: SATA、M.2、U.2、PCIe、BGA](https://img-blog.csdnimg.cn/0888a7fb5e504800bc792a7d74b0ac8e.png)
