主要研究人体姿态估计中heatmap转坐标的方法,提出一种新的解码方法
(其实这人体姿态我毛也不会,过来看看这个heatmap解码方法)
代码:https://github.com/ilovepose/DarkPose/blob/master/lib/core/inference.py
方法
人体姿态估计简单来说就是要预测人的所有关节的坐标,这里主要研究把关节转为热体图,然后进行回归的那种方法。
根据上下文推测,这里应该是一个关键点一个通道heatmap
Coordinate Decoding
如果输出的heatmap的尺寸和原图的大小一样,那么我们只需要找到最大的点。
然而通常我们输出的heatmap需要上采样到原来的尺寸,也就是乘以一个系数
λ
∈
R
+
+
\lambda \in \mathbb{R}_{++}
λ∈R++
这将导致亚像素定位问题(sub-pixel localisation)
The standard coordinate decoding method
令
h
\mathbf{h}
h为模型输出的heatmap
heatmap最大值
m
\mathbf{m}
m,第二大值
s
\mathbf{s}
s
那么heatmap中的关节位置
p
=
m
+
1
4
s
−
m
∥
s
−
m
∥
2
\mathbf{p} = \mathbf{m} + \frac{1}{4}\frac{\mathbf{s}-\mathbf{m}}{\|\mathbf{s}-\mathbf{m}\|_2}
p=m+41∥s−m∥2s−m
这个就是最大值往第二大值的方向移动
1
4
\frac{1}{4}
41像素
最终原图像的关节位置为
p
^
=
λ
p
\hat{\mathbf{p}} = \lambda \mathbf{p}
p^=λp
这个移动的主要目的是补偿下采样导致的量化效应
heatmap中最大值点并不代表真实关节的位置,只是一个大概的位置。
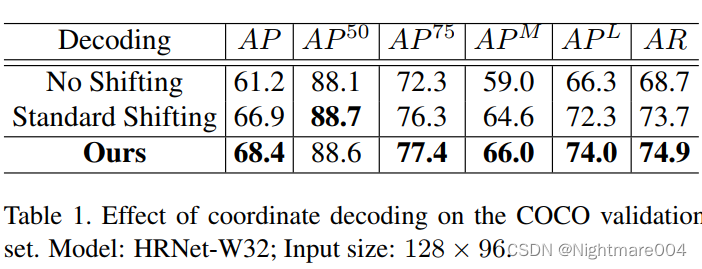
从这个表可以看出,这个移动能够带来很大的提升
Our coordinate decoding method
我们假设预测出来的heatmap和生成的heatmap服从高斯分布
因此预测的heatmap
G
(
x
;
μ
,
Σ
)
=
1
(
2
π
)
∣
Σ
∣
1
2
e
x
p
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
)
\mathcal{G}\left(\mathbf{x};\mathbf{\mu}, \mathbf{\Sigma}\right) = \frac{1}{\left(2\pi\right) \left|\mathbf{\Sigma}\right|^{\frac{1}{2}}}\rm{exp}\left(-\frac{1}{2}\left(\mathbf{x}-\mathbf{\mu}\right)^T\mathbf{\Sigma}^{-1}\left(\mathbf{x}-\mathbf{\mu}\right)\right)
G(x;μ,Σ)=(2π)∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
其中
x
\mathbf{x}
x是预测heatmap中的像素坐标,
μ
\mathbf{\mu}
μ是高斯中心,也就是预测的关节位置
Σ
\mathbf{\Sigma}
Σ是协方差矩阵,是一个对角矩阵
Σ
=
[
σ
2
0
0
σ
2
]
\mathbf{\Sigma} = \begin{bmatrix} \sigma^2 & 0 \\ 0 & \sigma^2 \end{bmatrix}
Σ=[σ200σ2]
σ
\sigma
σ是标准差
取个对数
P
(
x
;
μ
,
Σ
)
=
ln
(
G
)
=
−
ln
(
2
π
)
−
1
2
ln
(
∣
Σ
∣
)
−
1
2
(
x
−
μ
)
T
\begin{aligned} \mathcal{P}\left(\mathbf{x};\mathbf{\mu},\mathbf{\Sigma}\right) &= \ln \left(\mathbf{G}\right)\\ &=-\ln\left(2\pi\right) - \frac{1}{2}\ln\left(\left|\mathbf{\Sigma}\right|\right)-\frac{1}{2}\left(\mathbf{x}-\mathbf{\mu}\right)^T \end{aligned}
P(x;μ,Σ)=ln(G)=−ln(2π)−21ln(∣Σ∣)−21(x−μ)T
一阶导
D
′
(
x
)
∣
x
=
μ
=
∂
P
T
∂
x
∣
x
=
μ
=
−
Σ
−
1
(
x
−
μ
)
∣
x
=
μ
=
0
\left.\mathcal{D}^{\prime}(\boldsymbol{x})\right|_{\boldsymbol{x}=\boldsymbol{\mu}}=\left.\frac{\partial \mathcal{P}^T}{\partial \boldsymbol{x}}\right|_{\boldsymbol{x}=\boldsymbol{\mu}}=-\left.\Sigma^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right|_{\boldsymbol{x}=\boldsymbol{\mu}}=0
D′(x)∣x=μ=∂x∂PT
x=μ=−Σ−1(x−μ)
x=μ=0
二阶导
D
′
′
(
m
)
=
D
′
′
(
x
)
∣
x
=
m
=
−
Σ
−
1
\mathcal{D}^{\prime \prime}(\boldsymbol{m})=\left.\mathcal{D}^{\prime \prime}(\boldsymbol{x})\right|_{\boldsymbol{x}=\boldsymbol{m}}=-\Sigma^{-1}
D′′(m)=D′′(x)∣x=m=−Σ−1
在最大值点泰勒展开到二阶
P
(
μ
)
=
P
(
m
)
+
D
′
(
m
)
T
(
μ
−
m
)
+
1
2
(
μ
−
m
)
T
D
′
′
(
m
)
(
μ
−
m
)
\mathcal{P}(\boldsymbol{\mu})=\mathcal{P}(\boldsymbol{m})+\mathcal{D}^{\prime}(\boldsymbol{m})^T(\boldsymbol{\mu}-\boldsymbol{m})+\frac{1}{2}(\boldsymbol{\mu}-\boldsymbol{m})^T \mathcal{D}^{\prime \prime}(\boldsymbol{m})(\boldsymbol{\mu}-\boldsymbol{m})
P(μ)=P(m)+D′(m)T(μ−m)+21(μ−m)TD′′(m)(μ−m)
接着就能得到
μ
=
m
−
(
D
′
′
(
m
)
)
−
1
D
′
(
m
)
\boldsymbol{\mu} = \mathbf{m}-\left(\mathcal{D}^{\prime \prime}(\boldsymbol{m})\right)^{-1}\mathcal{D}^{\prime}(\boldsymbol{m})
μ=m−(D′′(m))−1D′(m)
说实话,不知道这个怎么得到的,我猜测是泰勒展开后求导为0得到的
代码里,一阶导和二阶导是用数字图像处理那种求导方法得到的
Heatmap distribution modulation
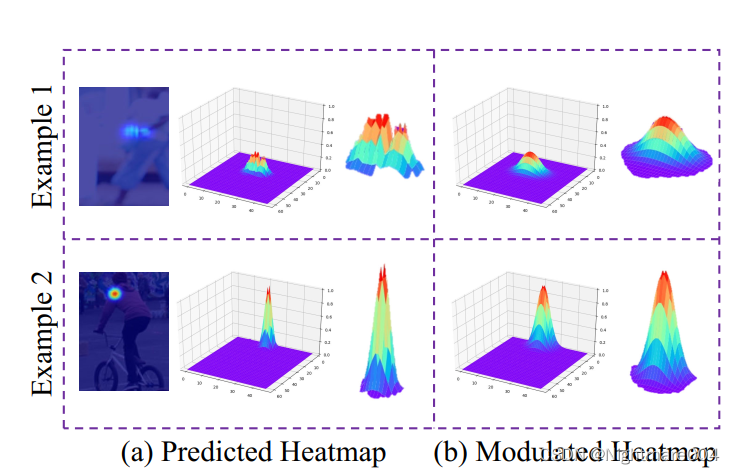
这个图(a)里是预测的heatmap,可以看出其实是有多个峰值的
这可能会对作者的解码方法产生负面影响。为了解决这个问题,先调整一下这个heatmap的分布
更具体地,为了解决这种多个峰值的情况,作者使用了和训练时方差一样的高斯核
K
\mathbf{K}
K
h
′
=
K
⊛
h
\mathbf{h}^{\prime} = \mathbf{K} \circledast \mathbf{h}
h′=K⊛h
为了保留原来的heatmap的大小(?magnitude),最终会放缩一下
h
′
=
h
′
−
min
(
h
′
)
max
(
h
′
)
−
min
(
h
′
)
∗
max
(
h
)
\boldsymbol{h}^{\prime}=\frac{\boldsymbol{h}^{\prime}-\min \left(\boldsymbol{h}^{\prime}\right)}{\max \left(\boldsymbol{h}^{\prime}\right)-\min \left(\boldsymbol{h}^{\prime}\right)} * \max (\boldsymbol{h})
h′=max(h′)−min(h′)h′−min(h′)∗max(h)
Coordinate Encoding
这里是讲热力图编码的方法
简单来说就是生成的时候不要用取整的方法得到热力图中心,而是直接生成