作者:PRISCILLA PARODI
在这篇博文中,你将探索使用 Elasticsearch 检索信息的各种方法,特别关注文本:词汇 (lexical) 和语义搜索 (semantic search)。

使用 Elasticsearch 进行词汇和语义搜索
搜索是根据你的搜索查询或组合查询查找最相关信息的过程,相关搜索结果是与这些查询最匹配的文档。 尽管存在与搜索相关的多种挑战和方法,但最终目标仍然相同,即找到问题的最佳答案。
考虑到这一目标,在这篇博文中,我们将探索使用 Elasticsearch 检索信息的不同方法,特别关注文本搜索:词汇和语义搜索。
先决条件
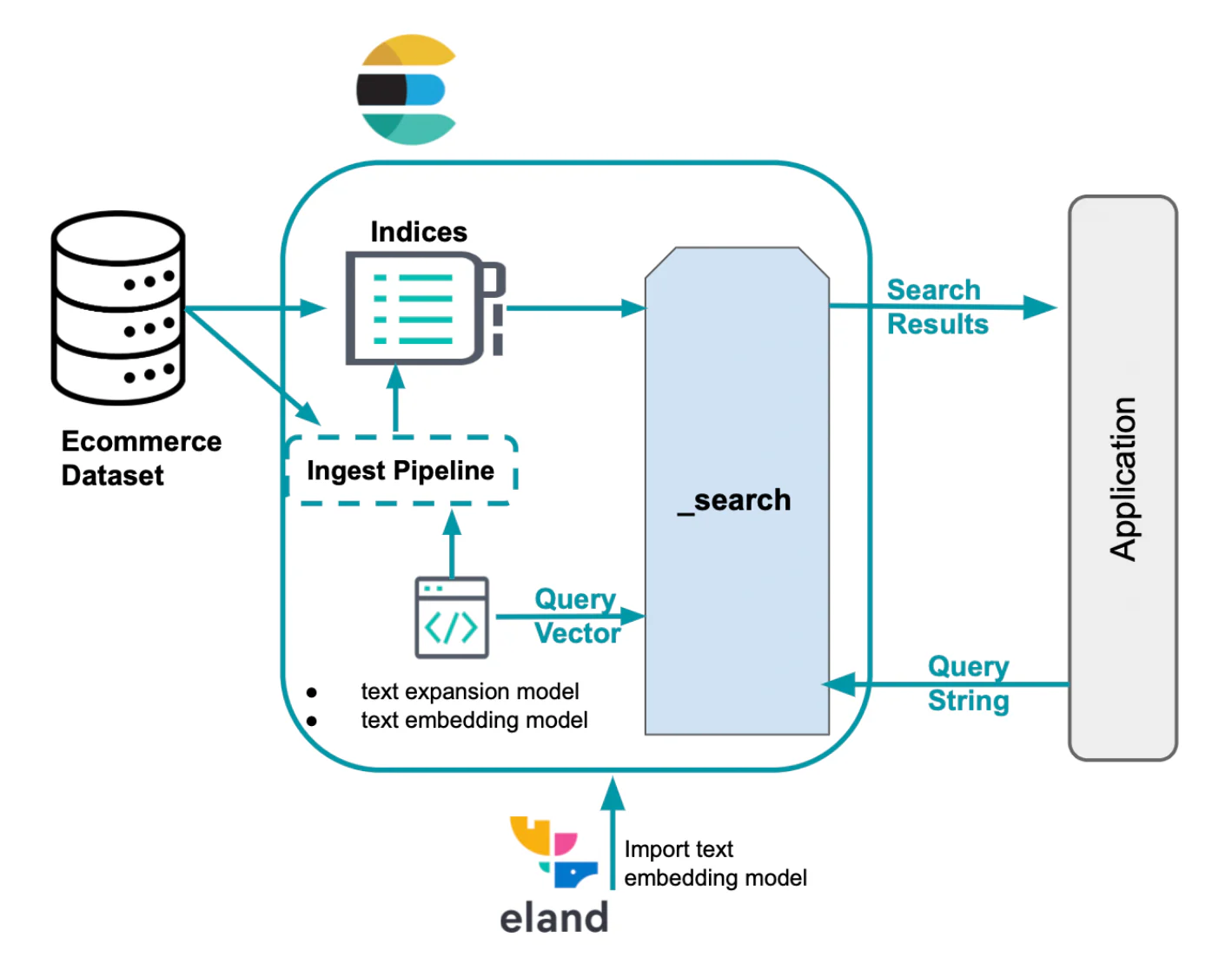
为了实现这一目标,我们将提供 Python 示例,演示在为模拟电子商务产品信息而生成的数据集上的各种搜索场景。
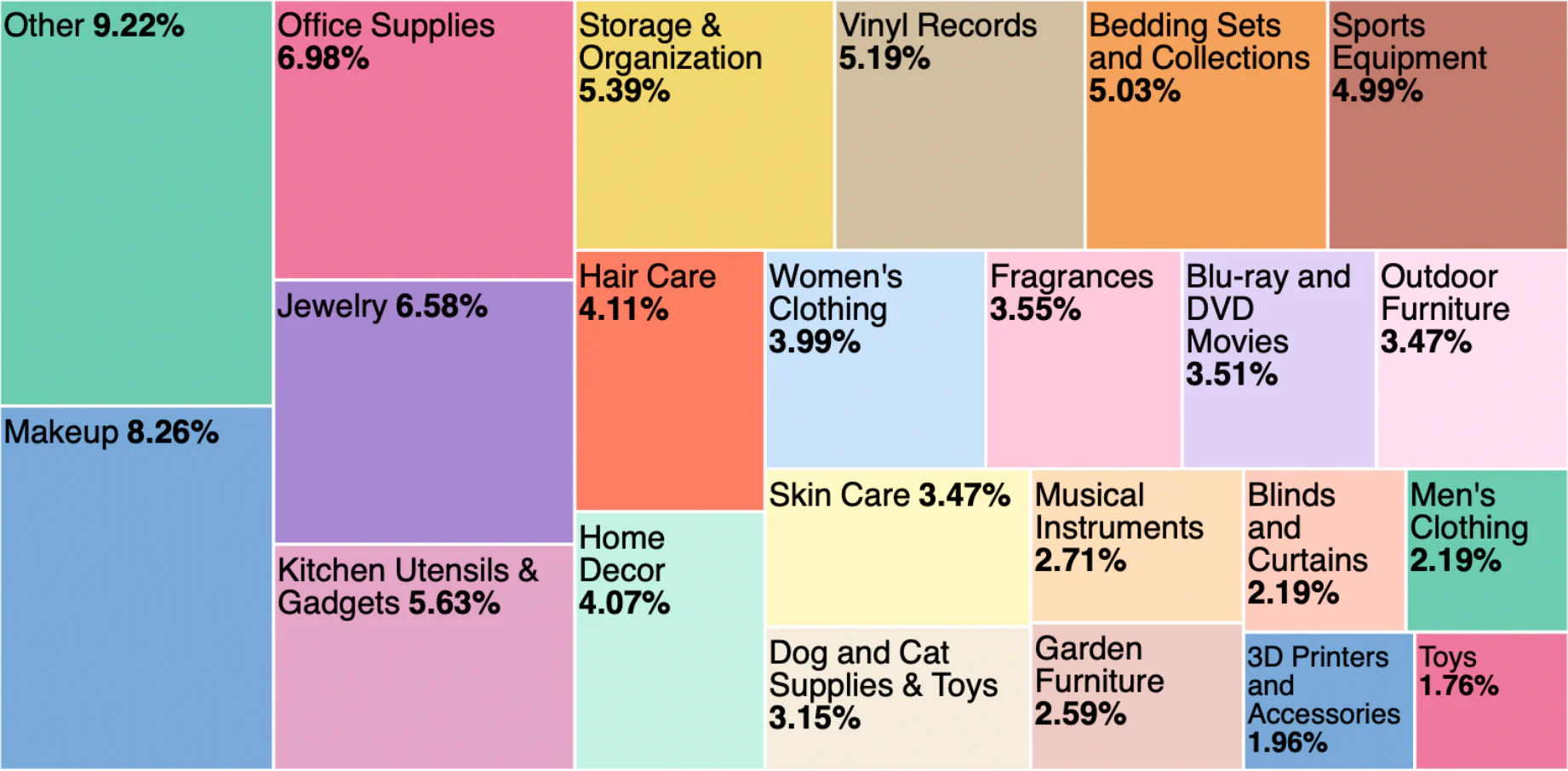
该数据集包含 2,500 多种产品,每种产品都有描述。 这些产品分为 76 个不同的产品类别,每个类别包含不同数量的产品,如下所示:
对于设置,你将需要:
- Python 3.6 或更高版本
- Elastic Python 客户端
- Elastic 8.8 或更高版本部署,具有 8GB 内存机器学习节点
- Elastic Learned Sparse EncodeR 模型已预加载到 Elastic 中并在你的部署中安装并启动
我们将使用 Elastic Cloud,可以免费试用。
除了本博文中提供的搜索查询之外,Python notebook 还将指导你完成以下过程:
- 使用 Python 客户端建立与我们的 Elastic 部署的连接
- 将文本嵌入模型加载到 Elasticsearch 集群中
- 使用用于索引特征向量和密集向量的映射创建索引。
- 使用推理处理器创建摄取管道以进行文本嵌入和文本扩展
词汇搜索 - 稀疏检索
Elasticsearch 基于文本查询对文档相关性进行排名的经典方式是使用 BM25 模型的 Lucene 实现,BM25 模型是一种用于词法搜索的稀疏模型 (sparse model for lexical search)。 此方法遵循传统的文本搜索方法,寻找精确的术语匹配。
为了使这种搜索成为可能,Elasticsearch 通过执行文本分析将文本字段数据转换为可搜索的格式。
文本分析由分析器执行,分析器是一组规则,用于管理提取相关标记进行搜索的过程。 分析器必须恰好有一个分词器。 分词器接收字符流并将其分解为单独的标记(通常是单独的单词),如下例所示:
词汇搜索的字符串标记化
#Performs text analysis on a string and returns the resulting tokens.
# Define the text to be analyzed
text = "Comfortable furniture for a large balcony"
# Define the analyze request
request_body = {
"analyzer": "standard",
"text": text
}
# Perform the analyze request
response = client.indices.analyze(analyzer=request_body["analyzer"], text=request_body["text"])
# Extract and display the analyzed tokens
tokens = [token["token"] for token in response["tokens"]]
print("Analyzed Tokens:", tokens)上述代码输出:
Analyzed Tokens: ['comfortable', 'furniture', 'for', 'a', 'large', 'balcony']在此示例中,我们使用默认分析器,即标准分析器,它适用于大多数用例,因为它提供基于英语语法的分词化。 标记化可以对各个术语进行匹配,但每个分词仍然按字面意思进行匹配。
如果你想个性化你的搜索体验,你可以选择不同的内置分析器。 例如,通过更新代码以使用停止分析器,它将在任何非字母字符处将文本分解为标记,并支持删除停止词。
...
# Define the analyze request
request_body = {
"analyzer": "stop",
"text": text
}
...上面的输出为:
Analyzed Tokens: ['comfortable', 'furniture', 'large', 'balcony']当内置分析器不能满足你的需求时,你可以创建自定义分析器,它使用零个或多个字符过滤器、分词器和零个或多个 token 过滤器的适当组合。
"analyzer": {
"my_analyzer": {
"type": "custom", #For custom analyzers, use a type of custom or omit the type parameter.
"tokenizer": "standard", #Built-in or customized tokenizer
"filter": ["lowercase", "synonym"] #Built-in or customized token filters
}
}在上面结合了分词器和分词过滤器的示例中,文本在被 synonym token filter 处理之前将被 lowercase filter 转为小写。
如果你想了解更多关于 analyzer 方面的知识,请参阅文章 “Elastic:开发者上手指南” 中的 “分词器介绍” 部分。
词汇匹配 - Lexical Matching
BM25 将根据术语的频率及其重要性来衡量文档与给定搜索查询的相关性。
下面的代码执行 match 查询,考虑 “ecommerce-search” 索引中的 “decription” 字段值和搜索查询 “Comfortable furniture for a large balcony"”,搜索最多两个文档。
细化被视为与该查询匹配的文档的标准可以提高精度。 然而,更具体的结果是以降低对变化的容忍度为代价的。
# BM25
response = client.search(size=2,
index="ecommerce-search",
query= {
"match": {
"description" : {
"query": "Comfortable furniture for a large balcony",
"analyzer": "stop"
}
}
}
)
hits = response['hits']['hits']
if not hits:
print("No matches found")
else:
for hit in hits:
score = hit['_score']
product = hit['_source']['product']
category = hit['_source']['category']
description = hit['_source']['description']
print(f"\nScore: {score}\nProduct: {product}\nCategory: {category}\nDescription: {description}\n")输出为:
Score: 15.607948
Product: Barbie Dreamhouse
Category: Toys
Description: is a classic Barbie playset with multiple rooms, furniture, a large balcony, a pool, and accessories. It allows kids to create their dream Barbie world.
Score: 9.137739
Product: Comfortable Rocking Chair
Category: Indoor Furniture
Description: enjoy relaxing moments with this comfortable rocking chair. Its smooth motion and cushioned seat make it an ideal piece of furniture for unwinding.通过分析输出,最相关的结果是 “Toys” 类别中的 “Barbie Dreamhouse” 产品,其描述高度相关,因为它包括术语 “furniture”、“large” 和 “balcony”,这是 唯一在描述中包含 3 个术语与搜索查询相匹配的产品,该产品也是唯一在描述中包含术语“阳台”的产品。
第二个最相关的产品是归类为 “Indoor Furniture” 的 “Comfortable Rocking Chair”,其描述包括术语 “comfortable” 和 “furniture”。 数据集中只有 3 个产品与此搜索查询的至少 2 个术语匹配,该产品就是其中之一。
“Comfortable” 出现在 105 个产品的描述中,“furniture” 出现在 4 个不同类别的 4 个产品的描述中:Toys, Indoor Furniture, Outdoor Furniture 和 “Cat Supplies & Toys”。
正如你所看到的,考虑到该查询,最相关的产品是玩具,第二相关的产品是室内家具。 如果你想要有关分数计算的详细信息,以了解为什么这些文档是匹配的,你可以将 explain __query 参数设置为true。
尽管这两个结果都是最相关的结果,但考虑到该数据集中的文档数量和术语的出现次数,查询 “Comfortable Furniture for a Large Baladal” 背后的意图是搜索实际大阳台的家具,但是不包括其他,玩具和室内家具。
词汇搜索相对简单且快速,但它有局限性,因为在不一定知道用户的意图和查询的情况下,并不总是可能知道所有可能的术语和同义词。 自然语言使用中的一个常见现象是词汇不匹配。 研究表明,平均而言,80% 的情况下,不同的人(同一领域的专家)会对同一事物有不同的命名。
这些限制促使我们寻找其他包含语义知识的评分模型。 基于 Transformer 的模型擅长处理自然语言等顺序输入标记,通过考虑文档和查询的数学表示来捕获搜索的潜在含义。 这允许对文本进行密集的、上下文感知的向量表示,为语义搜索提供动力,这是一种查找相关内容的精细方法。
语义搜索-密集检索
在这种情况下,将数据转换为有意义的向量值后,将利用 k 最近邻 (kNN) 搜索算法来查找数据集中与查询向量最相似的向量表示。 Elasticsearch 支持两种 kNN 搜索方法:精确 brute--fource kNN 和近似 kNN(也称为 ANN)。
Brute-force kNN 可以保证准确的结果,但不能很好地适应大型数据集。 近似 kNN 通过牺牲一些精度来提高性能,从而有效地找到近似最近邻。
借助 Lucene 对 kNN 搜索和密集向量索引的支持,Elasticsearch 充分利用了分层可导航小世界 (HNSW) 算法,该算法在各种 ANN 基准数据集上展示了强大的搜索性能。 可以使用以下示例代码在 Python 中执行近似 kNN 搜索。
使用近似 kNN 进行语义搜索
# KNN - approximate kNN
response = client.search(index='ecommerce-search', size=2,
knn={
"field": "description_vector.predicted_value",
"k": 50, # Number of nearest neighbors to return as top hits.
#The optimal value of k is dependent on the data. It can vary in different scenarios.
"num_candidates": 500, # Number of nearest neighbor candidates to consider per shard.
#Increasing num_candidates tends to improve the accuracy of the final k results.
"query_vector_builder": { # Object indicating how to build a query_vector. kNN search enables you to perform semantic search by using a previously deployed text embedding model, the steps for this process are demonstrated in the Python notebook.
"text_embedding": {
"model_id": "sentence-transformers__all-mpnet-base-v2", # Text embedding model id
"model_text": "Comfortable furniture for a large balcony" # Query
}
}
}
)
for hit in response['hits']['hits']:
score = hit['_score']
product = hit['_source']['product']
category = hit['_source']['category']
description = hit['_source']['description']
print(f"\nScore: {score}\nProduct: {product}\nCategory: {category}\nDescription: {description}\n")考虑到产品数据集中 “description” 字段的嵌入,此代码块使用 Elasticsearch 的 kNN 返回最多两个产品,其描述类似于 “Comfortable furniture for a large balcony” 的向量化查询 (query_vector_build)。
产品嵌入先前是在摄取管道中生成的,其中包含 “all-mpnet-base-v2” 文本嵌入模型的推理处理器,用于推断管道中摄取的数据。
该模型是根据使用 “sentence_transformers.evaluation” 对预训练模型进行评估而选择的,其中在训练期间使用不同的类别来评估模型。 根据 Sentence-Transformers 排名,“all-mpnet-base-v2” 模型展示了最佳的平均性能,并且还在大规模文本嵌入基准 (MTEB) 排行榜上获得了有利的位置。 该模型预先训练了 microsoft/mpnet-base 模型并在 1B 句子对数据集上进行了微调,它将句子映射到 768 维密集向量空间。
或者,还有许多其他模型可供使用,特别是那些针对特定领域数据进行微调的模型。
上面代码的输出为:
Score: 0.79207325
Product: Patio Sofa Set with Ottoman
Category: Outdoor Furniture
Description: is a versatile and comfortable patio sofa set, including a sofa, ottoman, and coffee table, great for outdoor lounging.
Score: 0.7836937
Product: Patio Sofa Set with Canopy
Category: Outdoor Furniture
Description: is a luxurious and comfortable patio sofa set with a canopy, providing shade and style for outdoor lounging.输出可能会根据所选模型、滤波器和近似 kNN 调整而有所不同。
kNN 搜索结果都属于 “Outdoor Furniture” 类别,尽管查询中没有明确提及 “outdoor”一词,这凸显了上下文中语义理解的重要性。
密集向量搜索具有以下几个优点:
- 启用语义搜索
- 处理非常大的数据集的可扩展性
- 灵活处理各种数据类型
然而,密集向量搜索也面临着其自身的挑战:
- 为你的用例选择正确的嵌入模型
- 选择模型后,可能需要微调模型以优化特定领域数据集的性能,这个过程需要领域专家的参与
- 此外,索引高维向量的计算成本可能很高
语义搜索 - 学习稀疏检索 (Learned Sparse Retrieval)
让我们探索另一种方法:学习稀疏检索,这是执行语义搜索的另一种方法。
作为稀疏模型,它利用 Elasticsearch 基于 Lucene 的倒排索引,该索引得益于数十年的优化。 然而,这种方法不仅仅是简单地使用 BM25 等词汇评分函数添加同义词。 相反,它使用更深入的语言规模知识来整合学习的关联,以优化相关性。
通过扩展搜索查询以包含原始查询中不存在的相关术语,Elastic Learned Sparse Encoder 改进了稀疏向量嵌入,如下面的示例所示。
使用 Elastic Learned Sparse Encoder 进行稀疏向量搜索
# Elastic Learned Sparse Encoder
response = client.search(index='ecommerce-search', size=2,
query={
"text_expansion": {
"ml.tokens": {
"model_id":"elser_model",
"model_text":"Comfortable furniture for a large balcony"
}
}
}
)
for hit in response['hits']['hits']:
score = hit['_score']
product = hit['_source']['product']
category = hit['_source']['category']
description = hit['_source']['description']
print(f"\nScore: {score}\nProduct: {product}\nCategory: {category}\nDescription: {description}\n")
输出:
Score: 14.405318
Product: Garden Lounge Set with Side Table
Category: Garden Furniture
Description: is a comfortable and stylish garden lounge set, including a sofa, chairs, and a side table for outdoor relaxation.
Score: 14.281318
Product: Rattan Patio Conversation Set
Category: Outdoor Furniture
Description: is a stylish and comfortable outdoor furniture set, including a sofa, two chairs, and a coffee table, all made of durable rattan material.本例中的结果包括 “Garden Furniture” 类别,该类别提供与 “Outdoor Furniture” 非常相似的产品。
通过分析 “ml.tokens”(包含学习稀疏检索生成的标记的 “rank_features” 字段),很明显,在生成的各种标记中,有些术语虽然不是搜索查询的一部分,但在含义上仍然相关,例如 “relax”(comfortable)、“sofa”(furniture)和 “outdoor”(balcony)。
下图突出显示了查询旁边的一些术语,包括带或不带术语扩展的情况。

正如所观察到的,该模型提供了上下文感知搜索,有助于缓解词汇不匹配问题,同时提供更具可解释性的结果。 当不应用特定领域的再训练时,它甚至可以超越密集向量模型。
混合搜索:结合词汇和语义搜索获得相关结果
就搜索而言,没有通用的解决方案。 这些检索方法都有其优点,但也有其挑战。 根据用例,最佳选项可能会发生变化。 通常,不同检索方法的最佳结果可以是互补的。 因此,为了提高相关性,我们将考虑结合每种方法的优点。
有多种方法可以实现混合搜索 (hybrid search),包括线性组合、为每个分数赋予权重以及倒数排名融合(RRF),其中不需要指定权重。
Elasticsearch:词汇和语义搜索的两全其美
# BM25 + Elastic Learned Sparse Encoder (Linear Combination)
response = client.search(index='ecommerce-search', size=2,
query= {
"bool": {
"should": [
{
"match": {
"description" : {
"query": "A dining table and comfortable chairs for a large balcony",
"boost": 1
}
}
},
{
"text_expansion": {
"ml.tokens": {
"model_id": "elser_model",
"model_text": "A dining table and comfortable chairs for a large balcony",
"boost": 1
}
}
}
]
}
}
)
# The boost value is 1 for the text expansion and match query. This means that the relevance score of the results of these queries are not boosted. You can specify a boost value to give a weight to each score in the sum. The scores will be calculated as: score = boost value * match_score + boost value * text_expansion_score
for hit in response['hits']['hits']:
score = hit['_score']
product = hit['_source']['product']
category = hit['_source']['category']
description = hit['_source']['description']
print(f"\nScore: {score}\nProduct: {product}\nCategory: {category}\nDescription: {description}\n")
在此代码中,我们使用两个值为 “A dining table and comfortable chairs for a large balcony” 的查询执行混合搜索。 我们没有使用 “furniture” 作为搜索词,而是指定我们要查找的内容,并且两个搜索都考虑相同的字段值 “description”。 排名由 BM25 和 ELSER 分数等权重的线性组合确定。
输出:
Score: 31.628141
Product: Garden Dining Set with Swivel Rockers
Category: Garden Furniture
Description: is a functional and comfortable garden dining set, including a table and chairs with swivel rockers for easy movement.
Score: 31.334227
Product: Garden Dining Set with Swivel Chairs
Category: Garden Furniture
Description: is a functional and comfortable garden dining set, including a table and chairs with swivel seats for convenience.在下面的代码中,我们将为查询使用相同的值,但使用倒数排名融合方法结合 BM25(查询参数)和 kNN(knn 参数)的分数来对文档进行组合和排名。
# BM25 + KNN (RRF)
response = client.search(index='ecommerce-search', size=2,
query={
"bool": {
"should": [
{
"match": {
"description": {
"query": "A dining table and comfortable chairs for a large balcony"
}
}
}
]
}
},
knn={
"field": "description_vector.predicted_value",
"k": 50,
"num_candidates": 500,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"model_text": "A dining table and comfortable chairs for a large balcony"
}
}
},
rank={
"rrf": { # Reciprocal rank fusion
"window_size": 50, # This value determines the size of the individual result sets per query.
"rank_constant": 20 # This value determines how much influence documents in individual result sets per query have over the final ranked result set.
}
}
)
for hit in response['hits']['hits']:
rank = hit['_rank']
category = hit['_source']['category']
product = hit['_source']['product']
description = hit['_source']['description']
print(f"\nRank: {rank}\nProduct: {product}\nCategory: {category}\nDescription: {description}\n")RRF 功能处于技术预览阶段。 语法可能会在正式发布之前发生变化。
输出:
Rank: 1
Product: Patio Dining Set with Bench
Category: Outdoor Furniture
Description: is a spacious and functional patio dining set, including a dining table, chairs, and a bench for additional seating.
Rank: 2
Product: Garden Dining Set with Swivel Chairs
Category: Garden Furniture
Description: is a functional and comfortable garden dining set, including a table and chairs with swivel seats for convenience.这里我们还可以使用不同的字段和值; Python notebook 中提供了其中一些示例。
正如你所看到的,使用 Elasticsearch,你可以两全其美:传统的词法搜索和向量搜索,无论是稀疏还是密集,都可以实现你的目标并找到问题的最佳答案。
如果你想继续了解此处提到的方法,这些博客可能会很有用:
- 改进 Elastic Stack 中的信息检索:混合检索
- Elasticsearch 中的向量搜索:设计背后的基本原理
- 如何利用 Elastic 的向量数据库充分利用词汇和 AI 驱动的搜索
- Elastic Learned Sparse Encoder 简介:Elastic 用于语义搜索的 AI 模型
- 改进 Elastic Stack 中的信息检索:引入 Elastic Learned Sparse Encoder,我们的新检索模型
Elasticsearch 提供向量数据库以及构建向量搜索所需的所有工具:
- Elasticsearch向量数据库
- Elastic 的向量搜索用例
结论:
在这篇博文中,我们探索了使用 Elasticsearch 检索信息的各种方法,特别关注文本、词汇和语义搜索。 为了演示这一点,我们提供了 Python 示例,展示了使用包含电子商务产品信息的数据集的不同搜索场景。
我们回顾了 BM25 的经典词汇搜索,并讨论了它的优点和挑战,例如词汇不匹配。 我们强调了结合语义知识来克服这个问题的重要性。 此外,我们讨论了密集向量搜索,它支持语义搜索,并讨论了与这种检索方法相关的挑战,包括索引高维向量时的计算成本。
另一方面,我们提到稀疏向量的压缩效果非常好。 因此,我们讨论了 Elastic 的学习稀疏编码器,它将搜索查询扩展为包含原始查询中不存在的相关术语。
在搜索方面,没有一种万能的解决方案。 每种检索方法都有其优点和挑战。 因此,我们还讨论了混合搜索的概念。
正如你所看到的,使用 Elasticsearch,你可以两全其美:传统的词法搜索和向量搜索!
准备好开始了吗? 检查可用的 Python notebook 并开始免费试用 Elastic Cloud。