文章目录
- 1. 写在前面
- 2. 页面配置规划
- 3. 制定模板格式
- 4. 模板引擎实现
- 5. 模板爬虫优势
1. 写在前面
作为一名爬虫开发者来说,涉及数据采集和爬虫开发时,往往都面临着各种挑战。包括技术复杂性、维护成本以及数据源结构的不断变化
早期我们对爬虫开发方式需要深入了解底层框架和编写大量的自定义代码,这对于没有技术背景的人来说可能是一个门槛过高的任务
但现在!我们可以使用模板爬虫的方式去简化爬虫开发的过程,降低技术门槛,提高可维护性的同时使数据采集变得更加高效和容易!
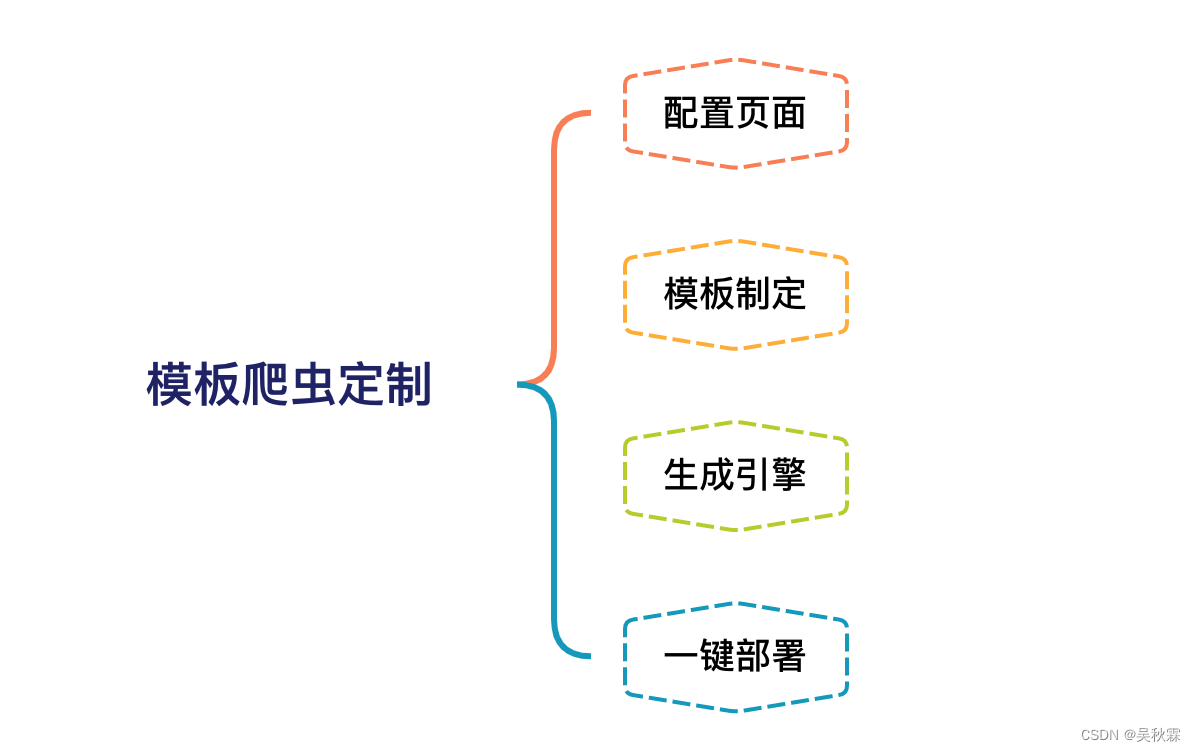
设计方案:
1、页面配置:通过页面可视化配置方式,提交翻页、数据抽取等规则
2、模板配置文件: 创建通用且固定的配置文件,用来填充XPATH
3、爬虫生成器(引擎): 模板爬虫使用这个生成器来读取配置文件,并生合规可用的爬虫工程代码
在这篇文章中,将深入探讨模板爬虫的设计和实现,以及如何利用其优势来轻松采集各种类型的网络数据
2. 页面配置规划
这里我将模板采集作为爬虫系统内部的一个独立模块去讲解,就像是爬虫可视化服务一样(之后会讲可视化)。需要打造的就是一个可配置化的爬虫生成服务
适用范围:新闻、资讯、论坛类等爬虫代码结构无需改变,只需要填充更新XPATH内容即可采集的网站
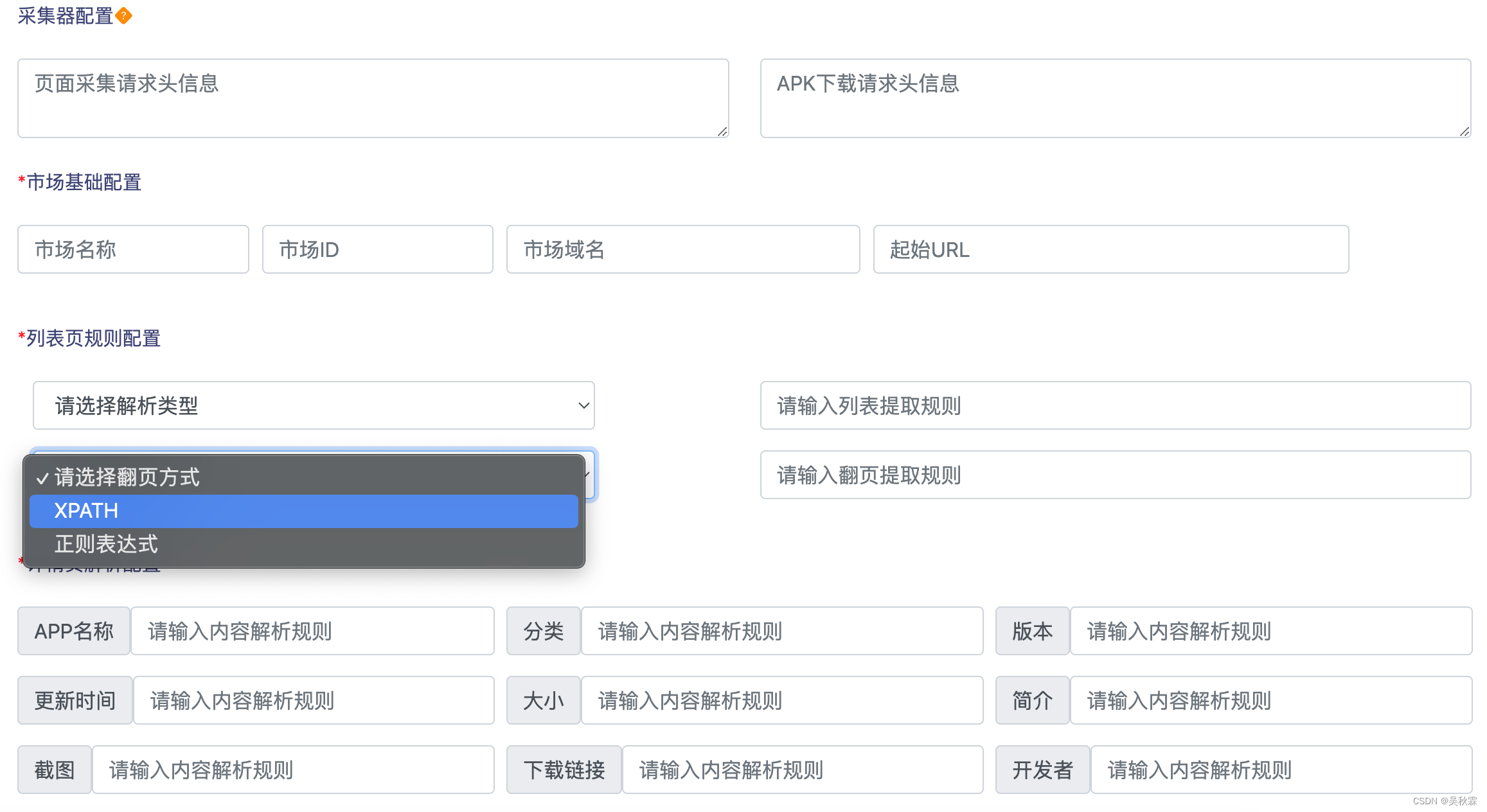
以下图我之前开发的页面为例,开发人员只需要配置一下网站的XPATH即可生成Scrapy可运行爬虫。下面的配置页面我主要是为了适用一些三方的APP应用市场,包括上面说到的几大类网站,它们都有很多共性,网站的结构也大致都分为列表页、详情页
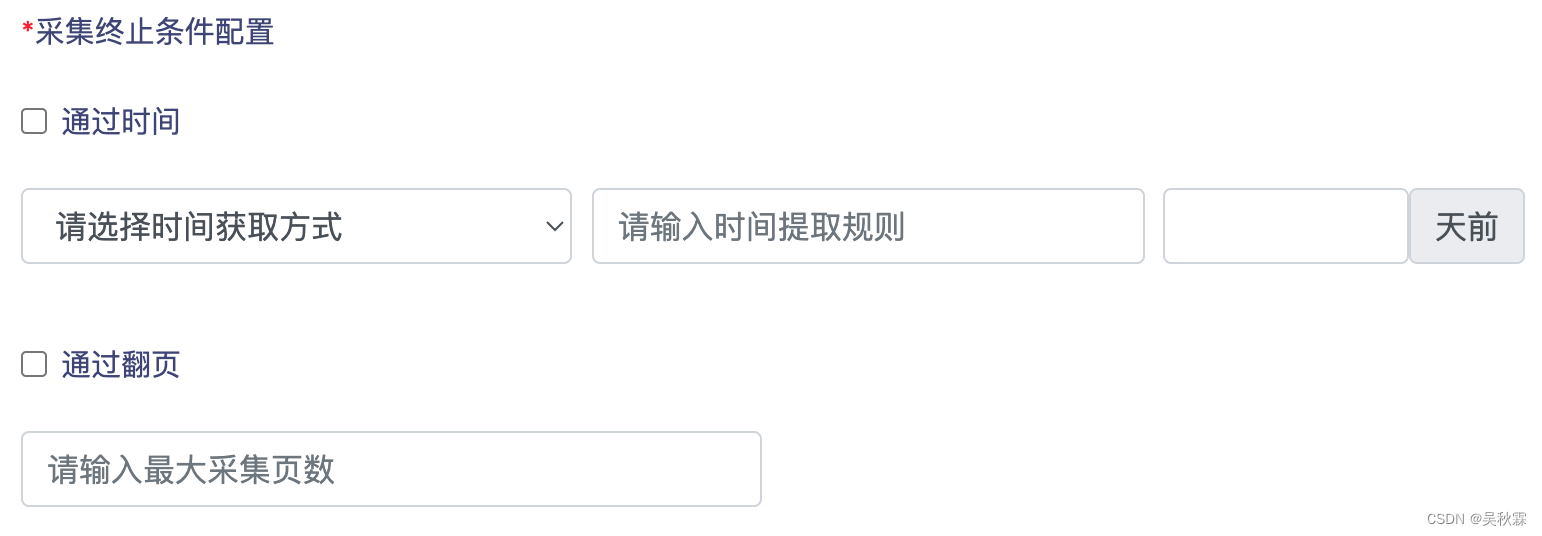
除了常规的页面基础配置以外,我们在应对一些含增量更新采集的网站(社交媒体、新闻等含发布时间的网站)则可以在前端的页面上增设终止采集的条件,按照时间或翻页量来实现效果
如下是某APP安卓应用市场网站页面,大部分都如此排版,比较规整。像这种相似度极高的网站,当需采集需要达到一定量级的时候,可以投入更多的时间去开发通用智能爬虫,对列表页进行智能识别采集,对详情页数据进行智能抽取!

继续往下还有一个配置项,我这里的话是为了应对APK文件下载。因为很多网站的APK下载大部分都是Ajax加载的接口,算是一个拓展配置项来处理通过接口下载APK文件
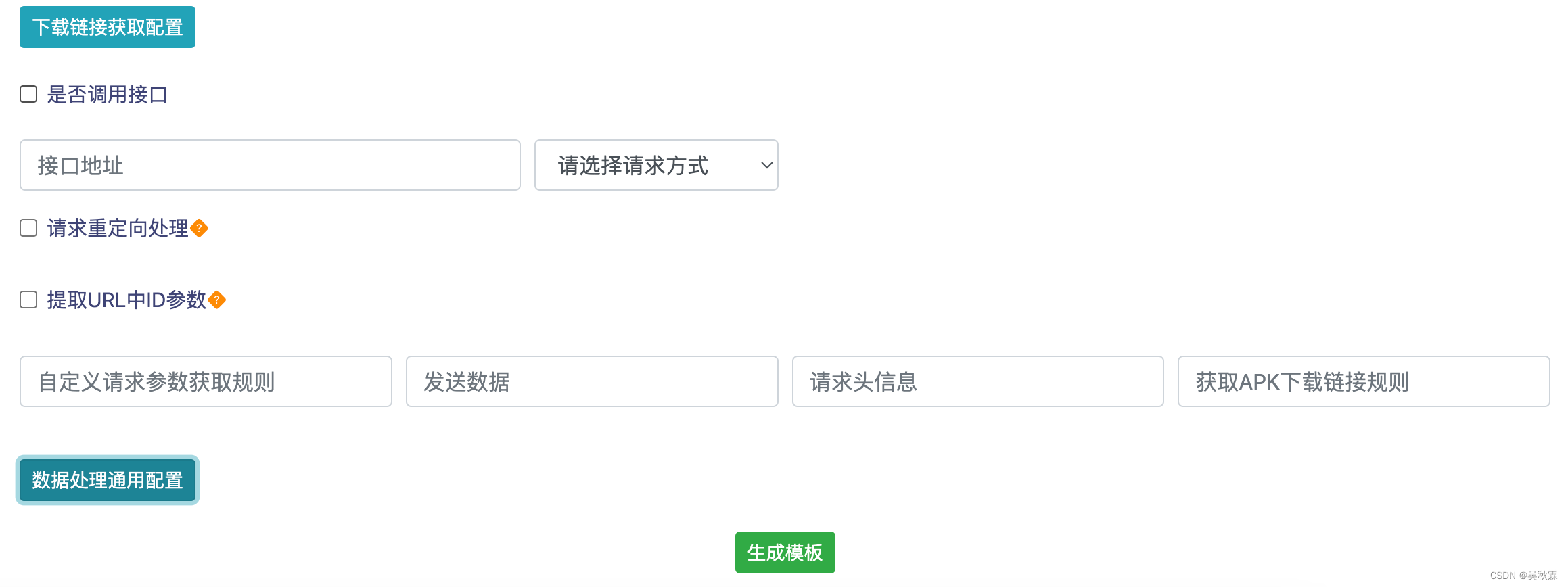
可以看到上图在请求APK下载接口时还有一些其他的配置项选择,因为一般都是POST请求,且下载接口的参数请求头都会出现变化
3. 制定模板格式
这里模板文件我使用的.py.tpl格式。因为在一些项目中, .py.tpl文件可能被用作代码模板文件!
这些模板文件包含占位符、标记或特殊语法,用于生成Scrapy爬虫代码。如{variable_name}或{% if condition %},然后使用特定的模板引擎或自定义脚本,将这些占位符替换为实际的Python代码
模板文件的典型用例包括代码生成,自动化脚本,和一些需要生成大量重复代码的应用程序。使用模板可以减少手动编写重复代码的工作,提高开发效率
通过上面我们的页面输入数据提取规则,爬虫程序可以读取这些模板并根据规则执行相应的数据提取操作。这使得爬虫的规则和配置可以被灵活地管理和修改,而无需修改源代码
Scrapy爬虫的.py.tpl文件内容如下所示:
class MarketSpider(scrapy.Spider):
HTTPERROR_ALLOWED_CODES = [502]
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
def __init__(self, *args, **kwards):
self.taskid = kwards.get("taskid")
super(MarketSpider, self).__init__(*args, **kwards)
name = '${project.get("name")}'
market = '${project.get("market")}'
market_name = '${project.get("market_name")}'
market_id = ${project.get('market_id')}
start_urls = ${project.get('start_urls').split(',')}
def parse(self, response, **kwargs):
page_list = response.xpath(
'${project.get("rules").get("list_page").get("rule")}').getall()
for _url in page_list:
yield scrapy.Request(url=response.urljoin(_url), headers=self.headers,
callback=self.parse_detail
)
next_page = response.xpath('${project.get("rules").get("paging").get("rule")}').get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page),
callback=self.parse
)
4. 模板引擎实现
有了上面固定的.py.tpl模板文件,这个时候我们需要的则是编写一个生成器(引擎)来负责自动生成Scrapy爬虫文件:
# -*- coding: utf-8 -*-
import os
import re
import zipfile
import shutil
from mako.template import Template
def add_zipfile(source_dir, output_filename):
f = zipfile.ZipFile(output_filename, 'w', zipfile.ZIP_DEFLATED)
for dirpath, dirnames, filenames in os.walk(source_dir):
for filename in filenames:
f.write(os.path.join(dirpath, filename))
f.close()
class BaseTemplate(object):
def __init__(self, template_name, output_name):
self.template = Template(filename=template_name)
self.output_filename = os.path.join('template_files', output_name)
def render(self, **kwargs):
with open(self.output_filename, "w+") as f:
f.write('# -*- coding: utf-8 -*-')
f.write(self.template.render(**kwargs))
class CrawlTemplate(BaseTemplate):
def render(self, *args, **kwargs):
super(CrawlTemplate, self).render(*args, **kwargs)
def _generate_crawl_template(project):
rex = re.compile('\.(.*)\.')
spider_name = rex.findall(project['market'])[0]
project.update(name=spider_name)
t = CrawlTemplate(
template_name="spider/template.py.tpl",
output_name=spider_name +
"_{}.py".format(
project['spider_type']))
t.render(**{"project": project})
def generate_crawl(template):
_generate_crawl_template(template)
这个引擎在什么时候调用?一般十在前端页面配置XPATH规则完点击提交生成以后调用
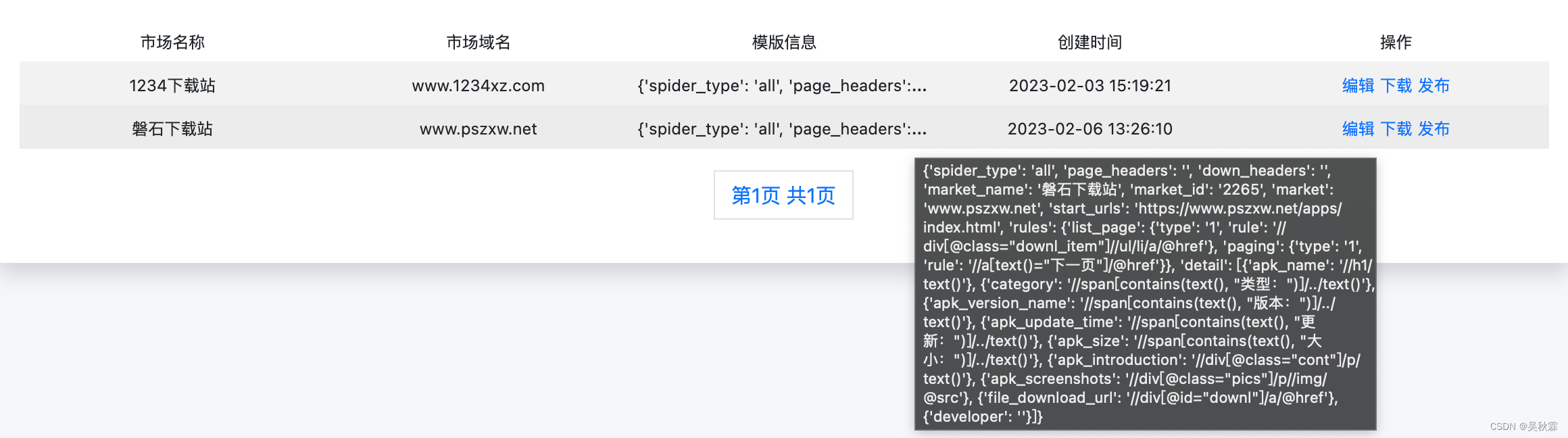
我这里的话是在配置完XPATH规则信息后,点击生成模板会存储模板信息。然后通过下载或者直接发布的方式去运行爬虫,当然还有一个编辑功能,这个功能应对页面改版导致的XPATH提取规则失效,可直接在线编辑更新,如下所示:
5. 模板爬虫优势
模板爬虫的主要优势在于简化了爬虫的开发过程,降低了技术门槛,提高了爬虫的可维护性和灵活性,具体有以下几点优势:
- 降低技术门槛:使用模板爬虫的开发者无需深入了解底层爬虫框架(如Scrapy)的工作原理和编程细节。他们只需配置页面中的XPath信息,而无需编写复杂的代码。这使得更多的人能够参与爬虫开发,包括非技术人员
- 提高开发效率: 通过简单的配置,模板爬虫可以自动生成可运行的Scrapy爬虫代码。这加速了开发过程,特别是对于需要快速构建爬虫的项目而言,可以大幅减少开发周期
- 可维护性: 使用模板爬虫可以更容易地维护和更新爬虫。当目标网站的结构变化时,只需更新配置文件中的XPath信息,而不需要修改底层代码。这减少了因网站变更而导致的爬虫维护工作
- 适用性广泛:模板爬虫通常具有通用性,可以用于多个网站,只需通过配置适应不同的数据源。这提高了爬虫的适用性,使其可用于多种数据采集任务
- 降低错误风险:由于不需要手动编写复杂的爬虫代码,减少了出现错误的机会,提高了数据提取的准确性
- 自动化任务生成:模板爬虫通常能够生成自动化任务,定期运行爬虫以获取最新的数据,这对于需要定期更新数据的应用非常有用
我们需要注意的是,尽管模板爬虫有这些优势,但并不是所有爬虫任务都适合使用模板爬虫。对于一些复杂的、高度定制(包括有加密的)爬虫任务,我们仍然需要手动编写爬虫代码
在选择是否使用模板爬虫时,需要根据具体的项目需求和复杂性进行权衡和决策!
好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章