评测标准
1.能力基础评测
为了检验大语言模型(LLM)的有效性和优越性,已有研究采用了大量的任务和基准数据集来进行实证评估和分析。根据任务定义,现有语言生成的任务主要可以分为语言建模、条件文本生成和代码合成任务。需要注意的是,代码合成不是典型的自然语言处理任务,但可以直接地用(经过代码数据训练的)LLM以类似自然语言文本生成的方法解决,因此也纳入讨论范围。
语言建模:语言建模是LLM的基本能力,旨在基于前一个token预测下一个token[15],主要关注基本的语言理解和生成能力;条件文本生成:作为语言生成中的一个重要话题,条件文本生成旨在基于给定的条件生成满足特定任务需求的文本,通常包括机器翻译、文本摘要和问答系统等;代码合成:除了生成高质量的自然语言外,现有的LLM还表现出强大的生成形式语言的能力,尤其是满足特定条件的计算机程序(即代码),这种能力被称为代码合成;闭卷问答任务测试LLM从预训练语料库中习得的事实知识。LLM只能基于给定的上下文回答问题,而不能使用外部资源;与闭卷问答不同,在开卷问答任务中,LLM可以从外部知识库或文档集合中提取有用的证据,然后基于提取的证据回答问题;在知识补全任务中,LLM(在某种程度上)可以被视为一个知识库,补全或预测知识单元(例如知识三元组)的缺失部分;知识推理任务依赖于逻辑关系和事实知识的证据来回答给定的问题。现有的工作主要使用特定的数据集来评估相应类型的知识推理能力;符号推理任务主要关注于在形式化规则设定中操作符号以实现某些特定目标,且这些操作和规则可能在LLM预训练期间从未被看到过;数学推理任务需要综合利用数学知识、逻辑和计算来解决问题或生成证明过程。以下为基础能力评测数据集表。
表 基础能力评测数据集表
| 基本任务 | 子任务 | 数据集 |
|---|---|---|
| 语言生成 | 语言建模 | PennTreebank,WikiText-103,thePile,LAMBADA |
| 语言生成 | 条件文本生成 | WMT’14,16,19,20,21,22,Flores-101,DiaBLa,CNN/DailyMail,XSum,WikiLingua,OpenDialKG,SuperGLUE,MMLU,BIG-benchHard,CLUE |
| 语言生成 | 代码合成 | APPS,HumanEval,MBPP,CodeContest,MTPB,DS-1000,ODEX |
| 知识运用 | 闭卷问答 | NaturalQuestions,ARC,TruthfulQA,WebQuestionsTriviaQA,PIQA,LC-quad2.0,GrailQA,KQApro,CWQ,MKQA,ScienceQA |
| 知识运用 | 开卷问答 | NaturalQuestions,OpenBookQA,ARC,WebQuestions,TriviaQA,MSMARCO,QASC,SQuAD,WikiMovies |
| 知识运用 | 知识补全 | WikiFact,FB15k-237,Freebase,WN18RR,WordNet,LAMA,YAGO3-10YAGO |
| 复杂推理 | 知识推理 | CSQA,StrategyQA,ARC,Bool,PIQA],SIQA,HellaSwag,WinoGrande,OpenBookQA,COPA,ScienceQA,proScript,ProPara,ExplaGraph,ProofWriter,EntailmentBank,ProOntoQA |
| 复杂推理 | 符号推理 | CoinFlip,ReverseList,LastLeTter,BooleanAssignment,Parity,ColoredObject,PenguinsinaTable,RepeatCopy,ObjectCounting |
| 复杂推理 | 数学推理 | MATH,GSM8k,SVAMP,MultiArith,ASDiv,MathQA,AQUA-RAT,MAWPS,DROP,NaturalProofs,PISA,miniF2F,ProofNet |
2.高级能力评估
高级能力评估有以下三种:
- 与人类对齐(人工评估)。
- 与外部环境的互动(生成例如清洁和烹饪任务清单,并根据清单及现实世界执行的成功率来评估能力)。
- 工具操作(例如数学问题求解,对逻辑推理及知识问答进行组合评估)。
与人类对齐(humanalignment)指的是让LLM能够很好地符合人类的价值和需求,这是在现实世界应用中广泛使用LLM的关键能力。为了评估这种能力,现有的研究考虑了多个人类对齐的标准,例如有益性、诚实性和安全性。对于有益性和诚实性,可以利用对抗性问答任务(例如TruthfulQA)来检查LLM在检测文本中可能的虚假性方面的能力。此外,有害性也可以通过若干现有的基准测试来评估,例如CrowS-Pairs和Winogender;除了标准评估任务外,LLM还具有从外部环境接收反馈并根据行为指令执行操作的能力,例如生成自然语言行动计划以操作智能体。LLM中具备这种能力,可以生成详细且高度逼真的行动计划,而较小的模型(例如GPT-2)倾向于生成较短或无意义的计划。为了测试这种能力,研究者提出了一些具身体感知的人工智能基准进行评估。VirtualHome构建了一个3D模拟器,用于家务任务(例如清洁和烹饪),代理人可以执行LLM生成的自然语言行动为了检验工具操作的能力,现有的工作大多采用复杂的推理任务进行评估,例如数学问题求解(例如GSM8k和SVAMP)或知识问答(例如TruthfulQA),其中成功操作工具对于增强LLM缺乏的所需技能非常重要(例如数值计算)。
3.评测基准
用于评估LLM的综合性评测基准如下所示:
- 基于MMLU的通用评测基准,用户大规模评测LLM的多任务知识理解能力。
- 基于Big-bench的通用评测基准,旨在从语言学、儿童发展、数学、常识推理等多方面探究现有LLM的能力。
- 基于HELM的综合性评测基准,目前包括16个核心场景和7类指标。
- 基于TyDiQA的大模型多语言知识利用评测基准。
- 基于MGSM的多语言数学推理评测基准。
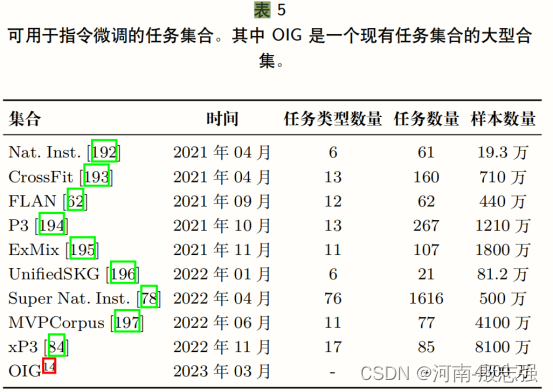
4. 评测标准相关内容列表
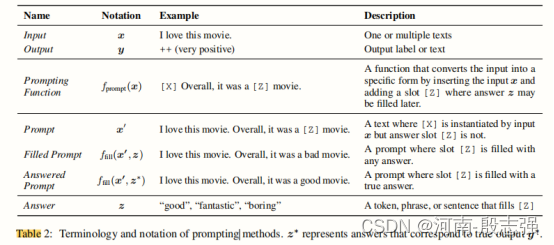
上表为不同任务对应的提示模版信息。
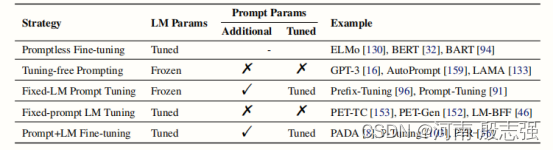
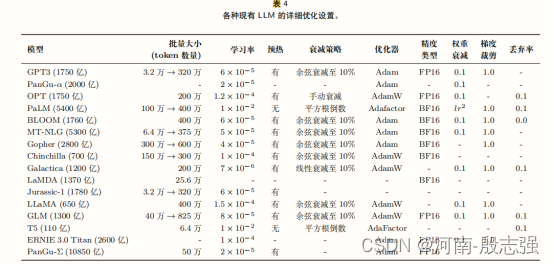
上表为,不同的调优策略的特点。“Additional”表示在LM参数之外是否有其他参数,而“Tunned”表示参数是否被更新。
评测报告
1.模型微调相关评测信息
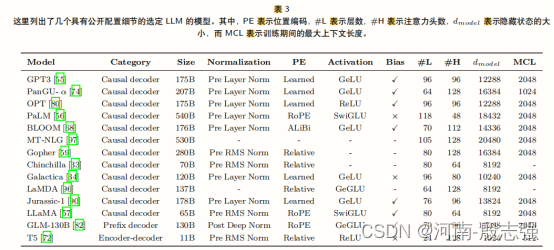
近年来大型语言模型(指规模大于10B的模型)的统计数据,包括Evaluation、Pre-trainDataScale(以token数量或存储大小表示)和Hardware。在本表中,我们仅列举有公开论文介绍技术细节的大语言模型。这里,“ReleaseTime”表示相应论文正式发布的日期。“PubliclyAvailable”表示模型检查点可以公开获取,而“ClosedSource”则相反。“Adaptation”指模型是否经过了后续微调:IT表示指令微调,RLHF表示人类反馈的强化学习。“Evaluation”表示模型是否在原始论文中评估了相应的能力:ICL表示上下文学习,CoT表示思维链。“*”表示最大的公开可用版本。
表 文献场景理解能力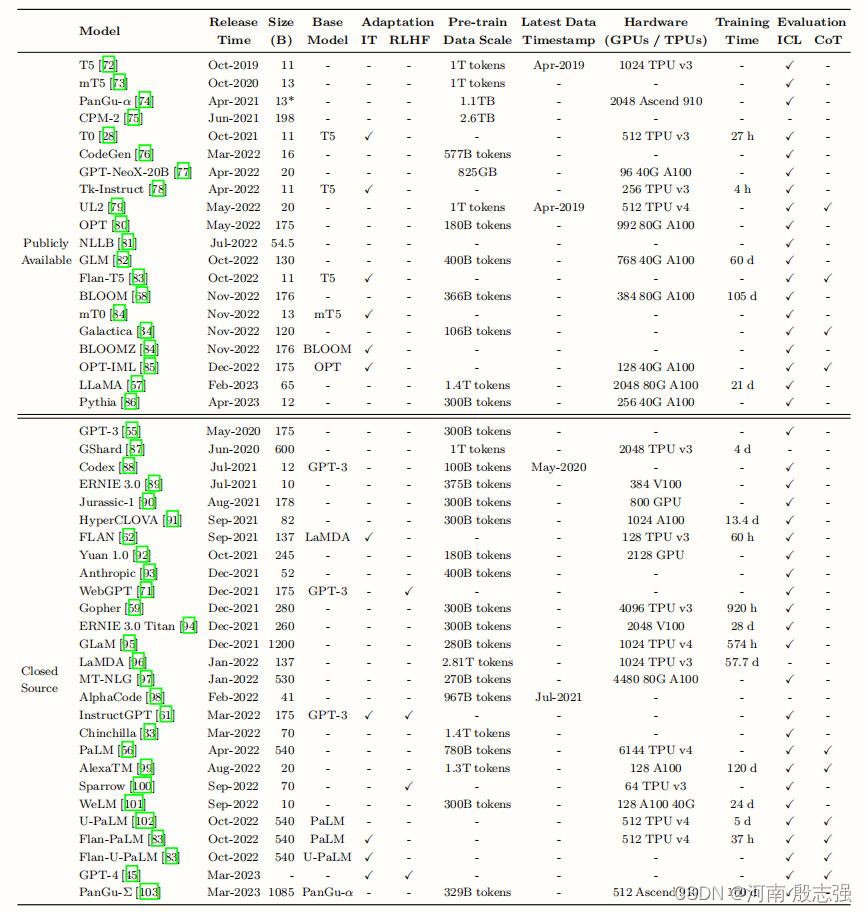
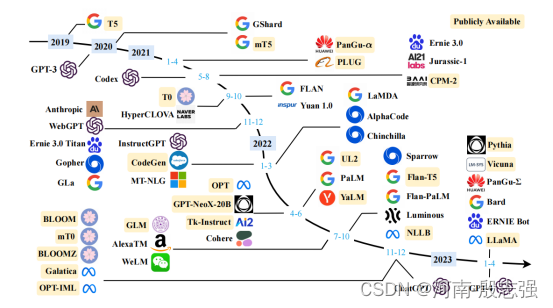
下述是最近几年现有的大型语言模型(大小超过 10B)的时间轴。时间轴主要是根据模型技术论文的发布日期(例如提交到 arXiv 的日期)建立的。由于图表空间的限制,仅展示公开报告了评估结果的 LLM。
2.模型能力评测信息
任务类型:CR:常识推理。QA:问题回答。SUM:总结。机器翻译。语言能力探测。GCG:一般的条件生成。CKM:常识性知识挖掘。FP:事实探测。TC:文本分类。MR:数学推理。SR:符号推理。AR:类比推理。Theory:理论分析。IE:信息提取。D2T:数据到文本。TAG:序列标记。SEMP:语义解析。EVALG:文本生成的评估。VQA:视觉问题回答。VFP:视觉事实探测。MG:多模态接地。CodeGen:代码生成。PLM列列出了在相应的论文中用于下游任务的所有预先训练过的lm。GPT-like是一种自回归语言模型,它对原始的GPT-2架构进行了小的修改。SeTting列出了基于提示的学习的设置,可以是零镜头学习(零)、少镜头学习(很少)、完全监督学习(完整)。在“提示工程”下,形状表示模板的形状(Clo表示卷块式搜索,Pre表示前缀),Man表示是否需要人工努力,Auto表示数据驱动的搜索方法(光盘用于离散搜索,Cont用于表示连续搜索)。在“回答工程”下,形状表示答案的形状(Tok表示标记级别,Sp表示跨度级别,Sen表示句子级或文档级),人和自动与上面相同。“调优”列列出了调优策略(7)。TFP:无调优的提示。固定提示LM调优。固定LM提示调优。LMPT:LM+提示调优。Mull-Pr列列出了多提示的学习方法。PA:提示增强。PE:提示集成。PC:提示组成。PD:及时分解。
表 针对各任务的大模型的理解能评测表
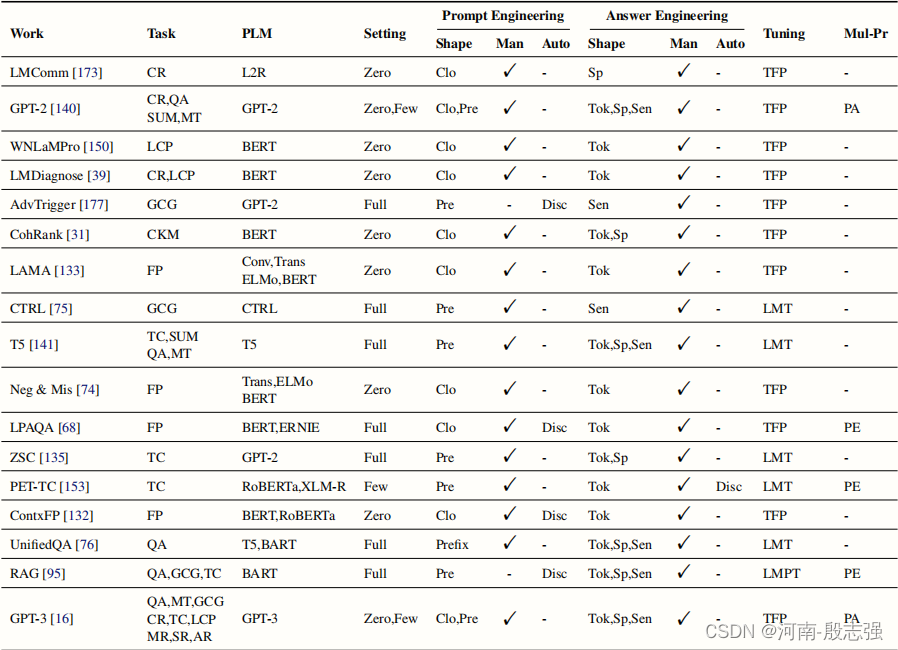
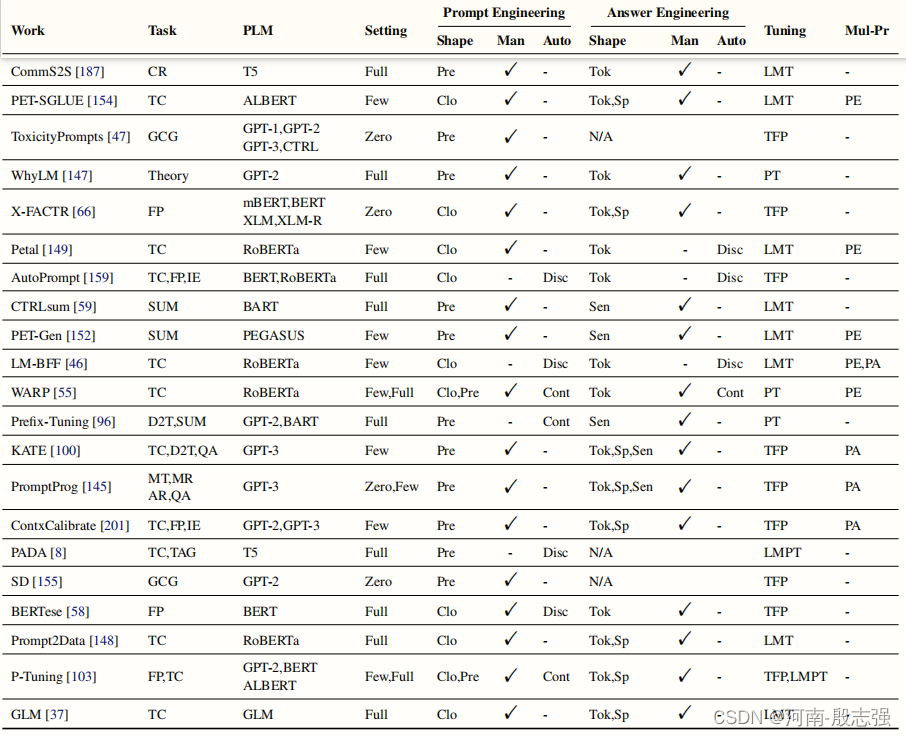
表 文献场景理解能力
| 模型/场景 | 概述生成 | 敏感话题杜绝 | 摘要结构化 | 统一风格回答问题 | 多轮问答 | 专利生成 | 复杂输出任务 |
|---|---|---|---|---|---|---|---|
| Chat-GLM-6B | √ | × | × | × | √ | √ | √ |
| Chat-GLM2-6B-32k | √ | × | √√ | √ | √ | √ | √√ |
| BloomZ-7B | √ | √√ | √ | √ | √ | √ | √ |
| T0PP-11B | √ | × | × | × | × | × | × |
| CLLaMA2-7B | √ | √ | √ | √√ | √ | √√ | × |
| MT0-13B | √ | × | × | × | √ | √ | × |
| PanguAlpha-6B | √ | × | × | × | × | √ | × |
| CLLaMA2-13B | √ | √ | √ | √ | √ | √ | × |
| Baichuan2-13B-Chat | √ | √ | √√ | √√ | √ | √√ | √ |
| ChatGPT4 | √ | √ | √√ | √ | √√ | √√ | √√ |
| ChatGPT3.5 | √ | √ | √ | √ | √ | √ | √ |
| 文心一言 | √√ | √ | √ | √√ | √ | √ | √ |
| 通义千问 | √ | √ | √ | √ | √ | √ | √ |
| 星火 | √ | √ | √ | √ | √ | √ | √ |
| Vicuna-13B | √ | √ | √ | √ | √ | √ | √ |
| 商量 | √ | √ | √ | √ | √ | √ | √ |
×表示不具备理解能力;√表示基本具备;√√表示效果最好
表 开源可调式模型训练推理显存使用结果
| 模型 | 训练显存占用 | 训练时间 | 推理显存占用 | 推理时间 |
|---|---|---|---|---|
| GLM-6B | 4-p100-15G | 3day | 1-p100-15G | 30S |
| GLM2-6B | - | - | 1-p100-16G | 20S |
| BloomZ-7B-8bit | 4-P100-14G | 5day | 1-p100-11G | 13S |
| T0PP-11B | × | × | - | - |
| CLLaMA2-7B | 5-p100-16G | 4day | 2-p100-15G | 60S |
| MT0-13B | × | × | 4-p100-16G | 34S |
| PanguAlpha-6B | - | - | 1-p100-11G | 40S |
| CLLaMA2-13B | - | × | 在线平台 | 49S |
| Baichuan2-13B-Chat | - | - | 4-p100-16G | 36S |
-:表示未记录;x:算力不够测不出
3.具体评测信息
按照自己的要求,约束表达
中英文指示模版:
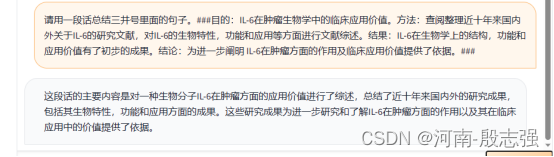
请用一段话总结三井号里面的句子。###目的:IL-6在肿瘤生物学中的临床应用价值。方法:查阅整理近十年来国内外关于IL-6的研究文献,对IL-6的生物特性,功能和应用等方面进行文献综述。结果:IL-6在生物学上的结构,功能和应用价值有了初步的成果。结论:为进一步阐明IL-6在肿瘤方面的作用及临床应用价值提供了依据。###
GLM-6B的测试效果


GLM2-6B测试效果


BloomZ-7B的测试效果


T0pp-11B(T5-plus拓展版)测试效果

C-LLaMA2-chat-7B(chat测试-时间有点长,基本60S)
网址:Llama27BChat-aHuggingFaceSpacebyLinkSoul