论文下载地址:Excellent-Paper-For-Daily-Reading/hyper-parameters at main
类别:超参数
时间:2023/10/30
摘要
面对不同的神经网络结构、超参数和训练协议,通常需要检查生成学习曲线,以快速终止超参数设置不佳的运行,从而大大加快手动超参数优化。通过跨超参数设置的学习曲线的概率模型,可以在自动超参数优化中利用相同的信息。论文研究了贝叶斯神经网络的使用,并通过一个专门的学习曲线层来提高它们的性能。
论文完成的成果
- 研究贝叶斯神经网络如何很好地适应各种架构和超参数设置的学习曲线,以及它们的不确定性估计有多可靠。
- 开发了一个带有学习曲线层的专用神经网络架构,以改进学习曲线预测。
- 比较了生成贝叶斯神经网络的不同方法:概率反向传播和两种不同的基于随机梯度的马尔可夫链蒙特卡罗(MCMC)方法。
- 评估了全新学习曲线和外推部分观察曲线的预测质量,在学习曲线尚未收敛的阶段。
- 扩展了多臂强盗策略(multi-armed bandit strategy),使用我们的模型进行采样,而不是均匀随机采样,从而使其能够比传统的贝叶斯优化更快地接近最优配置。
实验
学习曲线预测的实验
在实验部分,采用了不同的神经网络架构和学习曲线预测方法,并在不同数据集上进行了评估。实验结果表明,新模型的性能表现出良好的均方误差和平均对数似然,特别是使用随机梯度汉密尔顿MCMC方法(SGHMC)时表现更佳。此外,文章还比较了其他用于学习曲线预测的方法,包括随机森林、高斯过程、概率反向传播和简单的“最后一个观察到的值”方法。
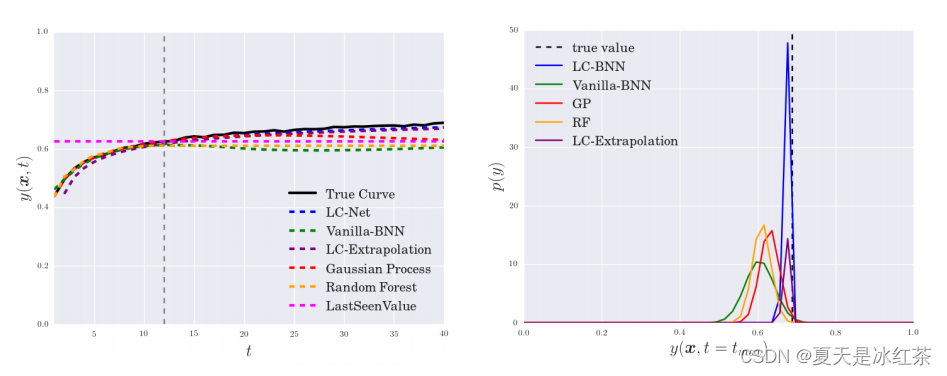
左图显示了不同方法在CNN基准上的平均预测。所有模型都观察到真实学习曲线(黑色)的前12个epoch的验证误差。右图,绘制了40个epoch值的后验分布。
结论
论文研究了一种基于贝叶斯神经网络的学习曲线建模方法,为解决超参数优化和性能改进问题提供了新的思路和工具。贝叶斯神经网络的引入以及新型学习曲线层的设计为未来的研究和实践提供了有趣的方向。
这篇论文为深度学习领域的研究者提供了一个全新的视角,强调了贝叶斯神经网络在学习曲线预测和超参数优化中的重要性。通过结合不同领域的知识,我们有望进一步提高机器学习算法的性能。
学习率范围测试
学习率范围测试,又被称为LR Finder,是机器学习领域的一个重要实践工具。在深度学习模型训练中,学习率的选择通常是一个挑战,因为一个合适的学习率可以加速收敛并提高性能,但不合适的学习率可能导致训练不稳定或收敛缓慢。传统上,学习率的设定是基于经验和试错的,这篇论文介绍了一种更科学、更系统的方法,即学习率范围测试。
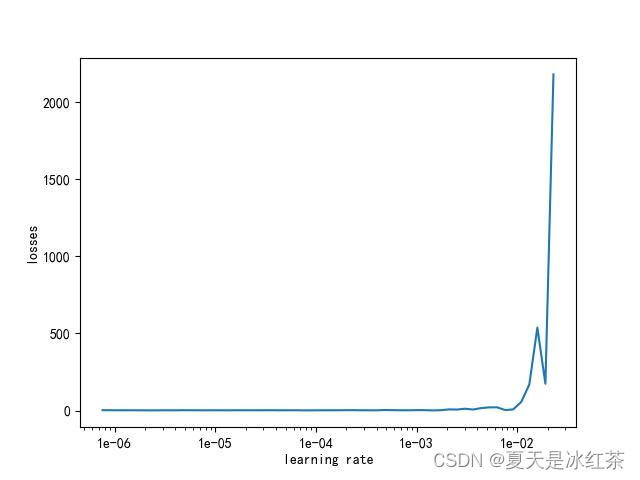
学习率范围测试的主要思想是在训练过程中逐渐增加学习率,然后观察模型的损失如何随学习率的增加而变化。通过分析损失与学习率之间的关系,可以找到一个合适的学习率范围,其中学习率既不会过高导致模型发散,也不会过低导致训练速度过慢。这种方法有助于为模型选择一个更有科学依据的初始学习率。
下面我根据模型、dataloader、损失函数和学习率进行调整:
import torch.nn as nn
import torch
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from utils.util import get_network
from utils.datasets import get_train_loader
from utils.lr_scheduler import _LRScheduler
from pyzjr.dlearn.learnrate import get_optimizer
class FindLR(_LRScheduler):
"""
exponentially increasing learning rate
Args:
optimizer: optimzier(e.g. SGD)
num_iter: totoal_iters
max_lr: maximum learning rate
"""
def __init__(self, optimizer, max_lr=10, num_iter=100, last_epoch=-1):
self.total_iters = num_iter
self.max_lr = max_lr
super().__init__(optimizer, last_epoch)
def get_lr(self):
return [base_lr * (self.max_lr / base_lr) ** (self.last_epoch / (self.total_iters + 1e-32)) for base_lr in self.base_lrs]
# class lr_finder():
# def __init__(self,net, training_loader, loss_function,optimizer_type="sgd",num_iter=100,batch_size=4):
# self.net = net
# self.training_loader = training_loader
# self.loss_function = loss_function
# self.optimizer_type = optimizer_type
# self.num_iter = num_iter
# self.batch_size = batch_size
#
# def update(self, init_lr=1e-7, max_lr=10):
# n = 0
# learning_rate = []
# losses = []
# optimizer = get_optimizer(self.net, self.optimizer_type, init_lr)
# lr_scheduler = FindLR(optimizer, max_lr=max_lr, num_iter=self.num_iter)
# epoches = int(args.num_iter / len(self.training_loader)) + 1
#
# for epoch in range(epoches):
# net.train()
# for batch_index, (images, labels) in enumerate(self.training_loader):
# if n > self.num_iter:
# break
# if torch.cuda.is_available():
# images = images.cuda()
# labels = labels.cuda()
#
# optimizer.zero_grad()
# predicts = net(images)
# loss = loss_function(predicts, labels)
# if torch.isnan(loss).any():
# n += 1e8
# break
# loss.backward()
# optimizer.step()
# lr_scheduler.step()
#
# print('Iterations: {iter_num} [{trained_samples}/{total_samples}]\tLoss: {:0.4f}\tLR: {:0.8f}'.format(
# loss.item(),
# optimizer.param_groups[0]['lr'],
# iter_num=n,
# trained_samples=batch_index * self.batch_size + len(images),
# total_samples=len(self.training_loader),
# ))
#
# learning_rate.append(optimizer.param_groups[0]['lr'])
# losses.append(loss.item())
# n += 1
#
# self.learning_rate = learning_rate[10:-5]
# self.losses = losses[10:-5]
#
# def plotshow(self, show=True):
# import matplotlib
# matplotlib.use("TkAgg")
# fig, ax = plt.subplots(1, 1)
# ax.plot(self.learning_rate, self.losses)
# ax.set_xlabel('learning rate')
# ax.set_ylabel('losses')
# ax.set_xscale('log')
# ax.xaxis.set_major_formatter(plt.FormatStrFormatter('%.0e'))
# if show:
# plt.show()
#
# def save(self, path='result.jpg'):
# self.plotshow(show=False)
# plt.savefig(path)
if __name__ == '__main__':
class parser_args():
def __init__(self):
self.net = "vgg16"
self.batch_size = 64
self.base_lr = 1e-7
self.max_lr = 10
self.num_iter = 100
self.Cuda = True
self.num_class = 4
from pyzjr.dlearn.learnrate import lr_finder
args = parser_args()
txt_path = r"D:\PythonProject\Torchproject\classification\dataset\train.txt"
train_loader = get_train_loader(txt_path, batch_size=4, train=True)
net = get_network(args)
loss_function = nn.CrossEntropyLoss()
lrfinder = lr_finder(net, train_loader, loss_function)
lrfinder.update()
lrfinder.plotshow()



![[双指针] (三) LeetCode LCR 179. 查找总价格为目标值的两个商品 和 15. 三数之和](https://img-blog.csdnimg.cn/img_convert/a68be9eda0c5cd735110277576ef3769.png)