目录
正则表达式
简单的介绍
正则表达式的创建
量词
Pattern和Matcher
1. find()
2. 分组
3. start()和end()
4. compile()中的标记
5. split()
6. 替换操作
reset()
正则表达式和Java的I/O
本笔记参考自: 《On Java 中文版》
正则表达式
正则表达式是强大而灵活的文本处理工具,它提供了一种紧凑且动态的语言,来解决字符串的各种问题。通过正则表达式,我们能够以编程的方式构建复杂的文本模式,从而在字符串中进行寻找和处理。
简单的介绍
以数字为例,已知两点信息:
- 在正则表达式中,【\d】表示的是一个数字(0 ~ 9)。
- 而在Java中,【\】是一个转义字符。因此【\\】表示的才是一个反斜杠。
把上述的这两点结合起来可知,若想要在Java中用正则表达式表示一个数字,那么我们应该使用的(正则表达式)字符串应该是【\\d】。同理可得,若想要往一个正则表达式中插入一个反斜杠,那么其对应的字符串应该是【\\\\】。
可以发现,正则表达式在Java中的表现过于笨拙,这是因为Java一开始并没有考虑到正则表达式。
(不过换行符【\n】和制表符【\t】都只需要一个反斜杠)
下面的例子用以显示普通字符串反斜杠和正则表达式反斜杠的区别,这会用到String.matches()函数:

matches()的参数就是一个正则表达式,它会作用于调用matches()的字符串。
【例子:正则表达式的反斜杠】
public class BackSlashes {
public static void main(String[] args) {
String one = "\\"; // 表示一个反斜杠
String two = "\\\\"; // 表示两个反斜杠
String three = "\\\\\\\\"; // 表示三个反斜杠
System.out.println("=== 普通的反斜杠 ===");
System.out.println(one);
System.out.println(two);
System.out.println(three);
System.out.println("===与正则表达式中的【\\】进行比较===");
System.out.println(one.matches("\\\\"));
System.out.println(two.matches("\\\\\\\\"));
System.out.println(three.matches("\\\\\\\\\\\\\\\\"));
}
}程序执行的结果是:

若我们需要匹配一个正则表达式的反斜杠,则需要四个反斜杠。
再看一个例子,这次的正则表达式会比较复杂:
【例子:更复杂的正则表达式】
public class IntegerMatch {
public static void main(String[] args) {
System.out.println("-1234".matches("-?\\d+"));
System.out.println("-5678".matches("-?\\d+"));
System.out.println("+514".matches("-?\\d+"));
System.out.println("+514".matches("(-|\\+)?\\d+"));
}
}程序执行的结果是:

首先解释一下正则表达式【-?\\d+】。可以将其拆分为几个部分:
- 【-】:表示一个减号。
- 【?】:这个字符前面的元素可以出现一次或多次。
- 【\\d】:正如之前所说,表示的是与一个数字进行匹配。
- 【+】:表示前面的元素有一个或多个。
更进一步,【(-|\\+)?\\d+】只是在上面的表达式上多加了一些字符:
- 【()】:将表达式分组。
- 【|】:表示“或”操作。
- 【\\+】:就如上面提到的,+在正则表达式中有特殊的含义,因此若想要匹配一个+,就需要使用反斜杠进行转义。
String类内置了一个很有用的正则表达式工具split(),它会根据参数(一个正则表达式)切割字符串:
【例子:使用split()切割字符串】
import java.util.Arrays;
public class Spliting {
public static String bird =
"Oh, to be a bird so free! " +
"To soar through the sky with ease......" +
"Unfettered by the chains of earth, " +
"Is a dream that fills my soul. ";
public static void split(String regex) {
System.out.println(
Arrays.toString(bird.split(regex)));
}
public static void main(String[] args) {
split(" "); // 参数不一定要有正则字符
split("\\W+"); // 按照不是单词的字符切割
split("n\\W+"); // n之后跟着一个不是单词的字符
}
}程序执行的结果是:

注意:并非只有特殊字符能够组成正则表达式,也可以添加普通字符。
上述程序中出现了【\\W】,这里先介绍它和一个与之类似的正则表达式:
- 【\\W】:表示非单词字符。
- 【\\w】:表示单词字符。
String.split()还有一个重载版本,它限制了拆分发生的次数。
正则表达式也可用于替换操作:
【例子:使用正则表达式进行替换】
public class Replacing {
static String s = Spliting.bird;
public static void main(String[] args) {
System.out.println(
s.replaceFirst("f\\w+", "【filter】"));
System.out.println(
s.replaceAll("free|the|a", "【filter】"));
}
}程序执行的结果是:

若正则表达式需要被多次使用,非字符串表达式会具有更高的效率。
正则表达式的创建
Java中存在着专门处理正则表达式的类Pattern,这个类位于java.util.regex包中。这个类包含了数个用于适用于正则表达式的方法。官方文档中详细地描述了各种特殊字符的用法,并且进行了分类。这里简单介绍一些常用的特殊字符及其使用:
| 符号 | 结果 / 含义 | |
|---|---|---|
| 构造项 | A | 指定字符A |
| \xhh | 匹配一个两位十六进制数(\x00 ~ \xFF)表示的字符 | |
| \uhhhh | 匹配一个四位十六进制数表示的Unicode字符 | |
| \t | 制表符(即Tab) | |
| \n | 换行 | |
| \r | 回车 | |
| \f | 换页 | |
| \e | 转义(即escape) | |
| 字符模式 | . | 可以匹配任何一个字符 |
| [abc] | a、b 和 c 中的任何一个字符(与a|b|c相同) | |
| [^abc] | a、b 和 c 之外的任何字符 | |
| [a-zA-Z] | a ~ z 或 A ~ Z 的任何字符 | |
| [abc[hij]] | a、b、c、h、i、j 中的任何一个字符(求并集) | |
| [a-z&&[hij]] | h、i 和 j 中的任何一个字符(求交集) | |
| \s | 一个空白字符(即空格、制表符、换行符、换页、回车) | |
| \S | 非空白字符(即 [^\s]) | |
| \d | 一个数字(即 [0-9]) | |
| \D | 非数字(即 [^0-9]) | |
| \w | 一个单词字符(即 [a-zA-Z_0-9]) | |
| \W | 一个非单词字符([^\w]) | |
| 逻辑操作符 | XY | X后跟着一个Y |
| X|Y | X或Y | |
| X&Y | X且Y | |
| 边界匹配器 | ^ | 匹配输入的开始。若多行标志(?m)被设置,则表示为行的开始。([^n]见下一栏) 例如: "^A"会匹配"An E"中的A。 |
| $ | 匹配输入的结束。若多行标志(?m)被设置,则表示为行的结束。 | |
| \b | 表示单词的边界(不是\d)。 例如: "\\bm"会匹配"moon"中的"m"。但"\\boo"不会匹配"moon"中的"oo"。 | |
| \B | 匹配一个“非单词边界”,具体情况可以参考该指南 | |
| \G | 前一个匹配的结束 | |
| 通配符和量词 | * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次,被称为贪婪量词 | |
| ? | 匹配前面的子表达式零次或一次,被称为非贪婪量词 | |
| {n} | 若前面的字符出现(且只出现)了n次,则继续匹配。 例如: "a{2}"不会匹配"candy"中的'a',但是会匹配"caandy"中的所有'a'。 | |
| {n,} | 若前面的字符至少出现了n次,则进行匹配。 例如: "a{2},"可以匹配"aa"、"aaa"、"aaaa",但是不会匹配"a"。 | |
| {n,m} | 匹配的字符最少出现n次,最多只能出现m次。 例如: "a{2,3}"匹配"caandy"中的两个'a',匹配"caaaaandy"中的前三个'a'。 | |
| [a] | 一个字符集合,匹配方括号内的任意字符(包括转义序列) 例如:"[abc]"和"[a-c]"一样,匹配"bank"中的'b',也能匹配"city"中的'c'。 | |
| [^a] | 表示反向的字符集合。 例如:"[^a]"匹配除'a'之外的所有字符。 | |
| (n) | 作为一个分组,可在之后的表达式中用 \i 来引用第 i 个分组(官方文档将圆括号放在了逻辑操作符一栏,笔者放在这里是为了方便自己归纳)。 | |
【例子:不同的正则表达式匹配】
public class Rudolph {
public static void main(String[] args) {
for (String pattern : new String[]{
"Rudolph",
"[rR]udolph",
"[rR][aeiou][a-z]ol.*",
"R.*"}) {
System.out.println("Rudolph".matches(pattern));
}
}
}程序执行的结果是:

注意:我们的目标不应该是创建多么复杂的正则表达式,而应该是创建能够完成工作的最简单的正则表达式。
量词
量词描述了一个正则表达式处理输入文本的方式。
- 贪婪型:量词默认是贪婪的。这种形式的表达式会为模式找到尽可能多的匹配项,但这也有可能引发问题。
- 勉强型:也被称为惰性匹配、非贪婪匹配。这种形式使用问号指定,量词会匹配满足模式所需的最少字符数。
- 占有型:占有型量词不会保留正则表达式的中间状态,以防止回溯。这种形式可以防止正则表达式在运行时失控,使执行更加有效。
正则表达式在应用于字符串时,会产生许多状态,方便在匹配失败时回溯。占有型量词会处理这种情况。
接下来通过表格的形式介绍一些量词的用法:
| 贪婪型 | 勉强型 | 占有型 | 匹配 / 解释 |
|---|---|---|---|
| X? | X?? | X?+ | X(一个或没有) |
| X* | X*? | X*+ | X(零个或多个) |
| X+ | X+? | X++ | X(一个或多个) |
| X{n} | X{n}? | X{n}+ | 精确匹配n个X |
| X{n,} | X{n,}? | X{n,}+ | 至少匹配n个X |
| X{n,m} | X{n,m}? | X{n,m}+ | 至少匹配n个X,并且至多匹配m个 |
注意:这些表达式最好都用括号括起来,防止出现误解。例如:
abc+看起来会匹配一个或多个abc序列,但实际上它的意思是“ab后面跟着多个c”。这是很容易忽略的,假如我们匹配的字符串正好是"abcabc",那么它似乎就没有出错。若想要匹配多个abc序列,应该这么做:
(abc)+Pattern和Matcher
尽管我们能够通过String做到有限的操作,但正则表达式的功能并没有被充分发挥。正如之前介绍的,Java专门设计了一个Pattern类,用于表示正则表达式的编译版本:

首先介绍两个接下来会用到的Pattern方法:
- compile():这个方法是静态的。它能够接受一个String,并且将其编译为Pattern对象。
- matcher():传入一个匹配对象,并生成一个Matcher对象。生成的Matcher对象中包含了各种能够对匹配对象进行的操作。
【例子:通过Pattern使用正则表达式】
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TestRegularExpression {
public static void main(String[] args) {
if (args.length < 2) {
System.out.format(
"请这样进行输入:%n" +
"\tjava TestRegularExpression " +
"正则表达式序列%n");
System.exit(0);
}
System.out.println("已输入:\"" + args[0] + "\"");
for (String arg : args) {
System.out.println(
"当前正则表达式:\"" + arg + "\"");
Pattern p = Pattern.compile(arg); // 通过Pattern构建正则表达式对象
Matcher m = p.matcher(args[0]);
while (m.find()) { // 尝试查找下一个能够匹配的项
System.out.println(
"匹配成功,\"" + m.group() + "\"的位置是" +
m.start() + "-" + (m.end() - 1));
}
}
}
}通过命令行键入:
java TestRegularExpression 114514 11 1+ [1+] \(14\){2,}可得执行结果是:

通常,我们会通过Pattern.matcher()方法生成Matcher对象,然后再通过Matcher对象完成各种匹配操作。
再介绍两个常用的Pattern方法:
- matches():是一个静态方法,包含两个参数:正则表达式和匹配对象的序列。这个方法会尝试通过正则表达式进行匹配,返回的结果就表示匹配是否成功。
- split():根据输入序列的匹配结果,拆分字符串。
此处对Pattern和Matcher的介绍较为简单,可以查看文档获得更多信息(Pattern、Matcher)。
下面介绍的是Matcher中的常用方法:
1. find()

该方法会尝试查找与模式匹配相适应的下一个子序列(这就像一个迭代器,向前遍历输入的字符串)。若不输入参数,则find()会从头开始进制查找。除此之外,它还有一个重载方法:

该方法可以重置匹配的索引,从新的起点再次开始匹配。
【例子:find()的使用】
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Finding {
public static void main(String[] args) {
Matcher m = Pattern.compile("\\w+")
.matcher("In the boundless universe");
while (m.find())
System.out.print(m.group() + " ");
System.out.println();
int i = 0;
while (m.find(i)) {
System.out.print(m.group() + " "); // group()会返回当前
i++;
}
}
}程序执行的结果是:

------
2. 分组
Matcher包含了一组关于分组的方法,在介绍它们之前先要了解什么是分组。分组,即用括号括起来的正则表达式,之后可以在代码中通过分组号调用它们:
- 分组0:表示整个表达式;
- 分组1:表示第一个带括号的分组;
- ……
例如,下面的表达式中有三个分组:
A(B(C))D其中,分组0是【ABCD】,分组1是【BC】,分组2是【C】。
Matcher提供了一系列方法,用于获取分组的信息(详见文档):
- groupCount():
返回匹配模式中的分组个数,但不包括分组0。
下面的这个方法有个不传参数的重载,用于直接返回上一次匹配的结果。
- group(int group):
输入参数是分组的索引。返回指定分组在上一次匹配操作期间捕获的输入子序列。若匹配失败,或返回空序列,则返回null。
【例子:对序列进行分组】
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Groups {
public static final String POEM =
"I wandered lonely as a cloud\n" +
"That floats on high o'er vales and hills,\n" +
"When all at once I saw a crowd,\n" +
"A host, of golden daffodils;\n" +
"Fluttering and dancing in the breeze.\n" +
"Nature made them pure and fair;\n" +
"Their beauty struck my heart with gladness,\n" +
"And I stopped there in wonder.";
public static void main(String[] args) {
// (?m)用于配置正则表达式,表示进行多行匹配
// 在这里(?m)用于改变$的行为,使其能够匹配文本行的结束
// \s匹配空白字符,\S匹配非空白字符,$匹配行的结束
Matcher m = Pattern.compile(
"(?m)(\\S+)\\s+((\\S+)\\s+(\\S+))$")
.matcher(POEM);
while (m.find()) {
for (int i = 0; i < m.groupCount(); i++)
System.out.print("[" + m.group(i) + "]");
System.out.println();
}
}
}程序执行的结果是:

由于$的默认行为是与整个序列(即整个POEM)的末尾进行匹配。所以这里需要使用模式标记(?m)改变$的行为,使其能够注意到输入中的换行符。
------
3. start()和end()
与group()类似,这两个方法也有不传参数的版本,用于直接匹配上一次的匹配项。这里介绍带有参数的版本:
- start(int group):
同样拥有一个输入参数用于指定分组的索引。返回指定组在上一次匹配操作期间捕获序列的开始索引。
- end(int group):
参数与start()相同。返回指定组在上一次匹配操作期间捕获序列的最后一个字符之后的偏移量。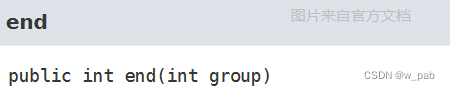
【例子:匹配,并且打印索引】
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StartEnd {
public static String input =
"But here were fifty of them,\n" +
"And they all rang true!\n" +
"And then I knew not what to do,\n" +
"But picked and ate one daffodil,\n" +
"And sank into a dream.";
private static class Display {
private boolean regexPrinted = false;
private String regex;
Display(String regex) {
this.regex = regex;
}
void display(String message) {
if (!regexPrinted) {
System.out.println("当前正则表达式:" + regex);
regexPrinted = true;
}
System.out.println(message);
}
}
static void examine(String s, String regex) {
Display d = new Display(regex);
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(s);
while (m.find())
d.display("find() \"" + m.group() +
"\" start = " + m.start() + " end = " + m.end());
if (m.lookingAt()) // 仅当输入字符串的开始部分模式匹配成功时,返回true
d.display("lookingAt() start = " +
m.start() + " end = " + m.end());
if (m.matches()) // 仅在整个输入序列都与正则表达式匹配时,返回true
d.display("matches() start = " +
m.start() + " end = " + m.end());
}
public static void main(String[] args) {
for (String in : input.split("\n")) {
System.out.println("输入:" + in);
for (String regex : new String[]{
"\\were", "\\w*l", "th\\w+", "And.*?[,!]"})
examine(in, regex);
System.out.println();
}
}
}程序执行的结果是:

这里还展示了find()和lookingAt()和matches()的区别。find()能够在字符串中的任何位置匹配正则表达式。但对于另外两个方法而言:
- lookingAt():只匹配输入字符串的开始部分。
- matches():仅当整个输入字符串和正则表达式匹配时成立。
------
4. compile()中的标记
Pattern中的compile()有一个重载版本,可以接受一个标记,并根据标记来改变匹配行为。

其中,flag能够接受的参数已经在Pattern中进行了规定:
| 标记 | 效果 |
|---|---|
| CASE_INSENSITIVE(?i) | 进行模式匹配时,不考虑大小写(若不启用,则只有US_ASCII字符集的匹配不考虑大小写)。 |
| MULTILINE(?m) | 启用多行模式。使得表达式^和$可以分别匹配一行的开头和结尾。 |
| DOTALL(?s) | 在该模式下,表达式【.】可以匹配任何字符,包括换行符(默认情况下不匹配)。 |
| UNICODE CASE(?u) | 需要配合标记CASE_INSENSITIVE进行使用。此时不区分大小写的匹配将以符合Unicode标准的形式完成。 |
| CANON EQ | 开启后,当且仅当两个字符的完全正则分解匹配时,才认为它们匹配。 例如:启用标记后,表达式【\u003F】将匹配字符串【?】。 |
| UNIX LINES(?d) | 在该模式下,在【.】、【^】和【$】的行为中,只识别换行符【\n】。 |
| LITERAL | 该模式会将输入字符串视为一个文本,不对任何特殊字符进行识别。 |
| COMMENTS(?x) | 在该模式下,空白符和以【#】开头的嵌入注释会被忽略,直到行尾。 |
上述表格中,用红色突出的标记是较常用的。
另外,可以在正则表达式中直接使用上述表格中的大多数标记,仅需将标记一栏中括号内的字符应用于希望生效的位置即可。
这些标记可以组合使用:
【例子:使用“或”操作【|】组合标记】
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ReFlags {
public static void main(String[] args) {
Pattern p = Pattern.compile("^java", // 匹配每一行以java开头的文本,忽略大小写
Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);
Matcher m = p.matcher(
"java has regex\nJava has regex\n" +
"JAVA has pretty good regular expression\n" +
"Regular expressions are in Java");
while (m.find())
System.out.println(m.group());
}
}程序执行的结果是:

------
5. split()
split()方法可以根据正则表达式拆分字符串:

在拆分完毕后,会返回操作完毕的字符串对象数组。
除此之外,split()方法还有一个重载:

这个版本添加的limit参数可用于限制拆分的次数。
【例子:拆分字符串】
import java.util.Arrays;
import java.util.regex.Pattern;
public class SplitDemo {
public static void main(String[] args) {
String input =
"啊啊!!今天天气真好!!红的花!!绿的草";
System.out.println(Arrays.toString(
Pattern.compile("!!").split(input)));
// 限制执行次数的版本:
System.out.println(Arrays.toString(
Pattern.compile("!!").split(input, 2)));
}
}程序执行的结果是:
![]()
------
6. 替换操作
这里介绍三个用于替换文本的方法(这些方法都存在于Matcher中):
- replaceFirst(String replacement):
将参数replacement与字符串第一个匹配的部分进行替换。
- replaceAll(String replacement):
将参数replacement与字符串每个匹配的部分进行替换。
- appendReplacement(StringBuffer sbuf, String replacement):
进行逐步替换,并将得到的结果保存在sbuf中。这个方法的灵活性在于,我们可以调用其他方法来处理或生成replacement,为每一个需要替换的地方输入特定的替换字符串。
(关于上述三个方法的重载,详见Matcher的文档)
除此之外,appendReplacement()也可以和appendTail()一起使用,后者将不用特殊处理的剩余字符串复制到sbuf中。
【例子:各种替换操作】
/*! 这块文本块将被用于本程序的Matcher的匹配。
这行文本块通过特殊的注释符进行修饰……
!*/
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class TheReplacements {
public static void main(String[] args)
throws Exception {
String s = Files.lines(
Paths.get("TheReplacements.java"))
.collect(Collectors.joining("\n"));
// 对上面注释掉的文本块进行匹配
Matcher mInput = Pattern.compile(
"/\\*!(.*)!\\*/", Pattern.DOTALL).matcher(s);
if (mInput.find())
s = mInput.group(1); // 被分组1(.*)捕获的
s = s.replaceAll(" {2,}", " "); // 用一个空格替代多个空格
s = s.replaceAll("(?m)^ +", ""); // 删除每行开头的多个空格
System.out.println(s);
s = s.replaceFirst("文本块", "【WenBenKuai】");
StringBuffer sbuf = new StringBuffer();
Pattern p = Pattern.compile("[aeiou]");
Matcher m = p.matcher(s);
// 一边查找,一边替换
while (m.find())
m.appendReplacement(
sbuf, m.group().toUpperCase());
m.appendTail(sbuf);
System.out.println(sbuf);
}
}程序执行的结果是:

appendReplacement()还允许在第二个参数(即替换的字符串)中使用【\$g】直接引用匹配的某个组,其中g就是组号。不过这种处理较为简单,无法胜任更复杂的字符串操作。
------
reset()
reset()方法允许我们使用新的序列重置匹配器。换言之,我们可以将现有的Matcher应用于新的序列。

【例子:复用Matcher】
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Resetting {
public static void main(String[] args)
throws Exception {
Matcher m = Pattern.compile("[frb][aiu][gx]")
.matcher("fix the rug with bags");
while (m.find())
System.out.print(m.group() + " ");
System.out.println();
m.reset("fix the rig with rags");
while (m.find())
System.out.print(m.group() + " ");
}
}程序执行的结果是:
![]()
reset()还有一个无参的版本,重置匹配器,但不使用新的序列。
正则表达式和Java的I/O
也可以动态地运用正则表达式,在各种文件中搜索匹配项。下面的例子模仿了UNIX的grep命令。
【例子:模仿grep命令】
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class JFrep {
public static void main(String[] args)
throws Exception {
if (args.length < 2) {
System.out.println(
"请按格式输入:\n" +
"\tjava JGrep 文件名 正则表达式");
System.exit(0);
}
Pattern p = Pattern.compile(args[1]);
Matcher m = p.matcher("");
// 遍历输入文件的每一行
Files.readAllLines(Paths.get(args[0])).forEach(
line -> {
m.reset(line);
while (m.find())
System.out.println(
m.group() + ": " + m.start());
}
);
}
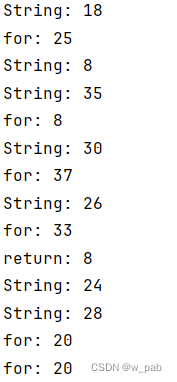
}执行命令:
java JFrep Hex.java "return|for|String"可得到输出为:
在这里,我们使用reset()在每一次匹配完成后重置Matcher对象。尽管也能在forEach()内为每一次匹配单独设置一个Matcher对象,但这种做法会有更大的开销。