一、强化学习引入
人的智能可以遗传获得也可以通过后天学习;学习有两种,模仿前人的经验是一种学习;如果没有前人的经验可以学习,就需要和环境进行交互,得到反馈来学习。
人工智能可以像人一样的模仿,就像监督学习,从给定的训练集中学习出一个函数,当新的数据到来时就可以利用这个函数预测结果。人工智能也可以像人一样自学,就像强化学习。如果环境是已知可以直接进行规划,如果环境是未知,就需要不断地探索与试错。
二、强化学习入门路线介绍
-
课程基础
- 数学基础
- 高等数学
- 线性代数(向量空间的变换思维)
- 概率与数理统计(期望、方差)
- 编程基础
- Python:numpy
- Paddle
- https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/index_cn.html
- 数学基础
-
资料推荐
- 书籍
- 经典书:《Reinforcement Learning: An Introduction(强化学习导论)》(强化等习教父Aichard Sutton 的经典)
- 视频
- 理论课:2015David Silver经典强化学习公开课、 UC Berkeley CS285、斯坦福 CS234
- 动手实践:Sarsa、Q-learning、DQN、Policy Gradient、DDPG(本次公开课实践内容)
- 进阶:经典论文
- DQN.“Playing atari with deep reinforcement learning.” https://anxiv.org/pdf/1312.5602.pdf
- A3C.“Asynchronous methods for deep reinforcement learning.” http://www.jmir.org/proceedings/papers/v48/mniha16.pdf
- DDPG.“Continuous control with deep reinforcement learning.” https://anxiv.org/pdt/1509.02971
- PPO.“Proximal policy optimization algorithms.” http://aniv.org/pdf/1707.06347
- 前沿研究方向:
- Model-base RL. Hierarchical RL. Multi Agent RL. Meta Learning
- 书籍
三、什么是强化学习
- 核心思想:智能体 agent 在环境 environment 中学习,根据环境的状态 state,执行动作action,并根据环境的反馈 reward(奖励)来指导更好的动作。
智能体观察环境,然后对环境做出动作,收到来自环境的反馈。然后通过反馈和改变之后的环境状态做出下一次的动作,循环往复以上情况。
- 强化学习的特点
- 序列决策的过程,不断地和环境交互,观察和输出动作
- 延迟奖励
四、强化学习的应用
强化学习和其他机器学习的关系
初印象.assets/image-20221116082639352.png)
- 监督学习(分类、回归)
- 非监督学习(聚类)
强化学习与监督学习的区别
- 监督学习(认知:是什么)
- 独立同分布
- 强化学习(决策:怎么做)
- 序列决策过程
Agent 学习的两种方案
- 基于价值 value-based
- 确定性策略
- Sarsa
- Q-learning
- DQN
- 确定性策略
- 基于策略 policy-based
- 随机性策略
- Policy gradient
- 随机性策略
RL 概览分类
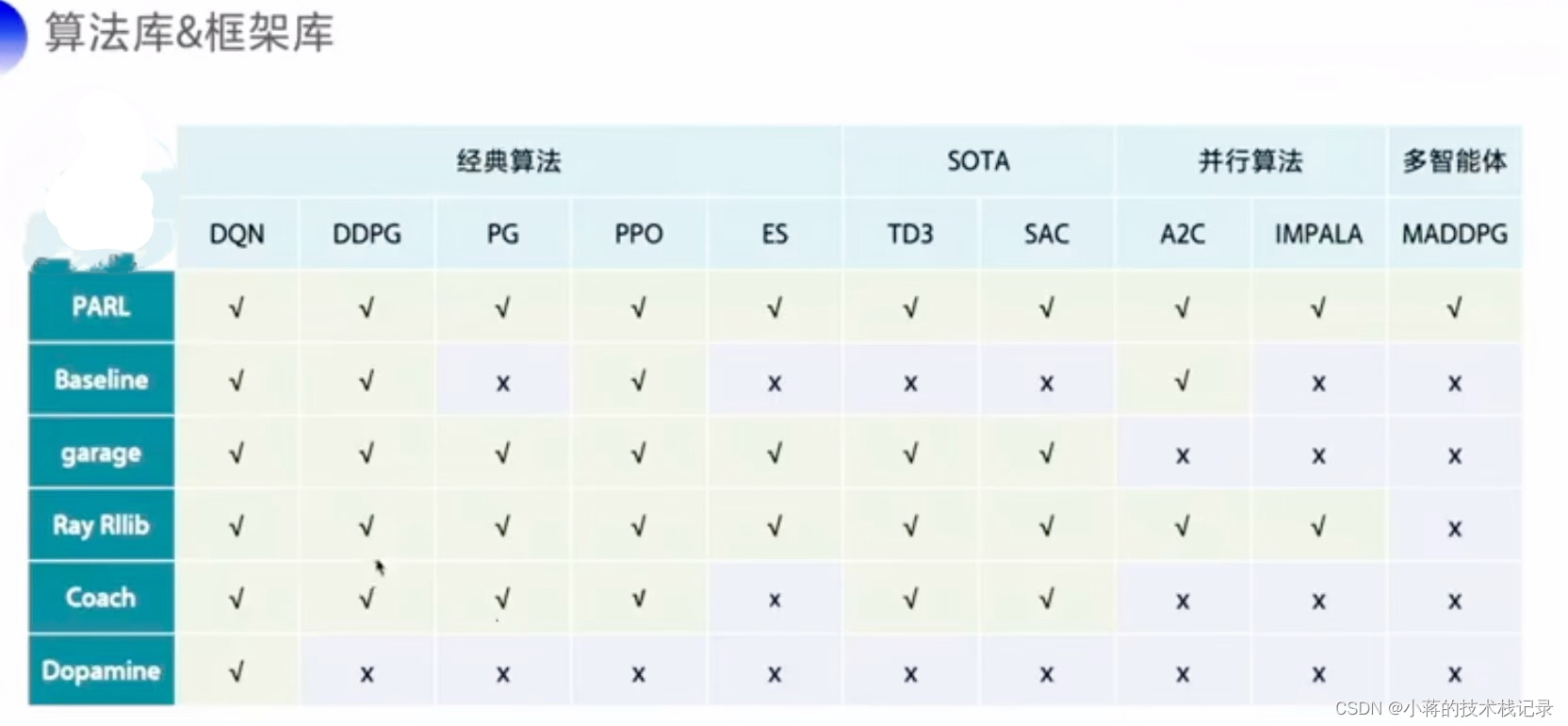
RL常用算法库&框架库
RL 编程实践:GYM
-
Gym:仿真平台、python开源库、RL测试平台
-
官网:https://gym.openai.com/
-
离散控制场景:一般使用atari环境评估
-
连续控制场景:一般使用mujoco环境游戏来评估
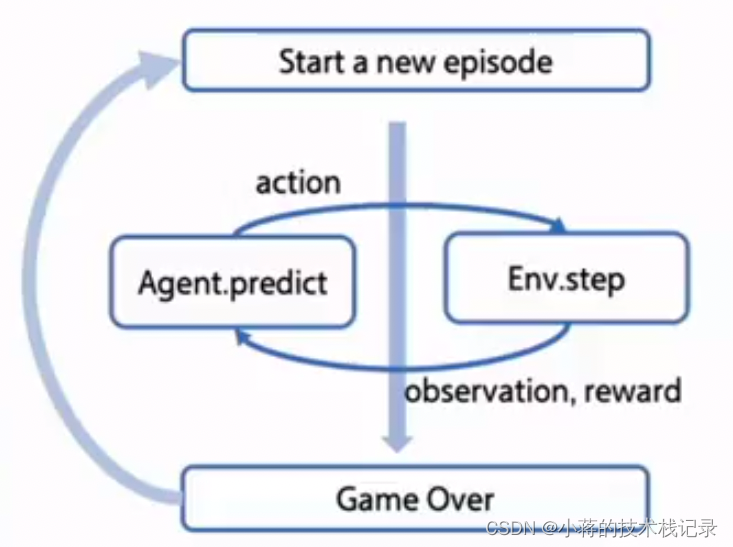
RL agent <-> environment 交互接口
gym 的核心接口是 environment。提供以下几个核心方法
( 1 ) reset():重置环境的状态,回到初始环境,方便开始下一次训练。
( 2 ) step(action):推进一个时间步长,返回四个值:
① observation (object):对环境的一次观察;
② reward (float):奖励:
③done (boolean):代表是否需要重置环境;
④ info (dict):用于调试的诊段信息。
( 3 ) render():重绘环境的一帧图像。
import gym
env = gym.make("CliffWalking-v0")
obs = env.reset()
while True:
action = np.random.randint(0,4) # 0-4 代表上下左右共四个动作,随机选一个
obs,reward,done,info = env.setp(action)
env.render()
if done:
break
代码体验
代码路径
- 下载python 3.6(官网)
- 下载pip(命令行)
- 下载paddlepaddle(利用pip)
- [下载gym](pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gym)
- 将上面代码路径的文件克隆下来
使用
- 命令行进入lesson1
- 命令行使用python命令
>>>import gym
>>>from gridworld import CliffWalkingWapper
>>>env = gym.make("CliffWalking-v0")
>>>env = CliffWalkingWapper(env) #创建悬崖环境
>>>env.reset()
36
>>>env.render()
>>>env.step(0) #向上走
(24, -1, False, {'prob': 1.0}) #第一个值为状态值,第二个值为reward,第三个值为一轮游戏有没有玩完,第四个字段是info,额外信息
>>>env.step(1) #向右走
>>>env.render()
>>>env.step(2) #向下走
>>>env.render() ##直到终点
- 自动寻找路径代码
import gym
import numpy as np
env = gym.make("CliffWalking-v0")
obs = env.reset()
while True:
action = np.random.randint(0,4)
obs,reward,done,info = env.step(action)
env.render()
if done:
break
广告:PARL 对 agent 的框架抽象
- 本次课程的代码主要参考的强化学习算法框架库:PARL
- 官网:https://github.com/PaddlePaddle/PARL
- 特点:
- 代码可读性好、函数功能清晰
- 支持算法数量多种类全,可复现性好
- 模块之间糯合度低,内聚性强
- 【入门】快速学习和对比不同常用算法
- 【科研】科研人员快速复现论文结果,迁移算法到不同环境调研
- 【工业】大规模分布式能力,只需加两行代码:单机一多机训练,快速迭代上线
初印象.assets/image-20221116223156307.png)
初印象.assets/image-20221116223203420.png)
作业
pip install paddlepaddle==1.6.3 # -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install parl==1.3.1
pip install gym
git clone -depth=1 https://github.com/PaddlePaddle/PARL.git
cd PARL/examples/QuickStart
python train.py
Tips1: Pip库安装常见问题:网络超时
解决办法1:使用清华源 -i https://pypi.tuna.tsinghua.edu.cn/simple
解决办法2:https//pypi.org/ 下载whl包或者源码包安装
Tipsz: Pip安装中断:某个依赖包安装失败,重新安装即可
Tips3:独立的Python环境:Conda //能够将不同的python环境隔离开来