load_dataset读取jsonl文件报错
alpaca_en = dict(
type=process_hf_dataset,
dataset=dict(type=load_dataset, data_files=alpaca_file_path),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=alpaca_map_fn,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)
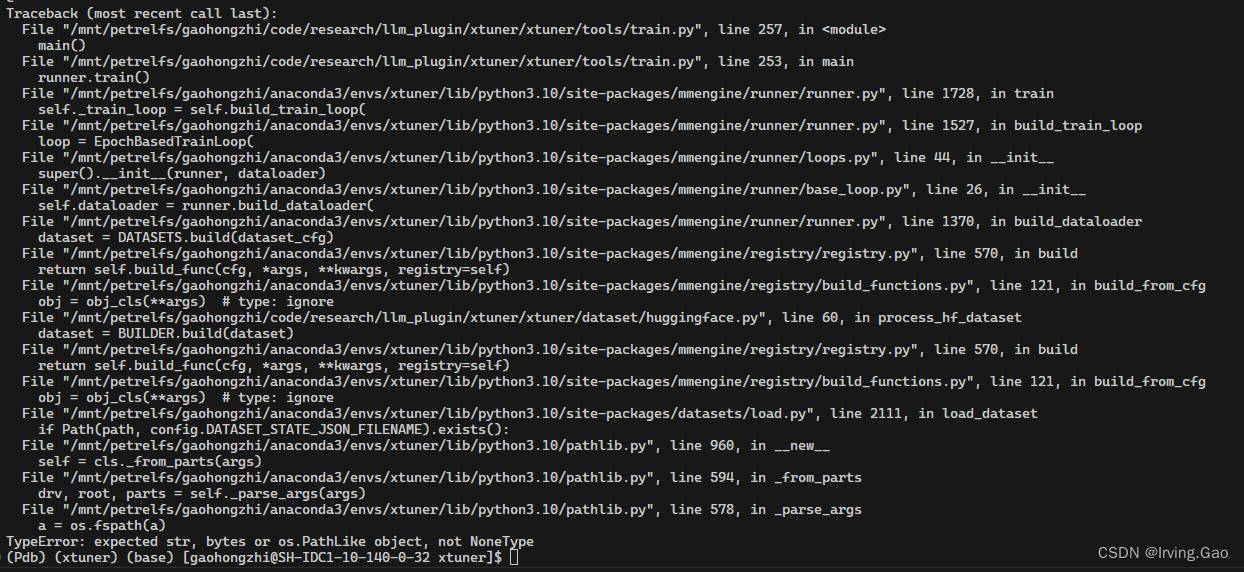
- 原因及解决方法:指定
json文件时,需要传入path='json'必传项:
alpaca_en = dict(
type=process_hf_dataset,
dataset=dict(type=load_dataset, path='json', data_files=alpaca_file_path),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=alpaca_map_fn,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=DefaultSampler, shuffle=True),
collate_fn=dict(type=default_collate_fn))