文章目录
- 网络架构学习1
- 1. 传统CNN卷积神经网络
- 1.1 基本思想
- 1.2 VCG16(经典CNN网络架构之一)
- 2. 两种经典的网络架构
- 2.1 FCN网络
- 2.2 U-Net网络
- 3. FCNVMB(基于U-Net架构)
- 3.1 FCNVMB 主要思想
- 3.2 FCNVMB 提供的其他思想
网络架构学习1
1. 传统CNN卷积神经网络
1.1 基本思想
CNN网络主要得过程:输入层-卷积层(ReLU)-池化层-全连接层-输出层 如下图所示: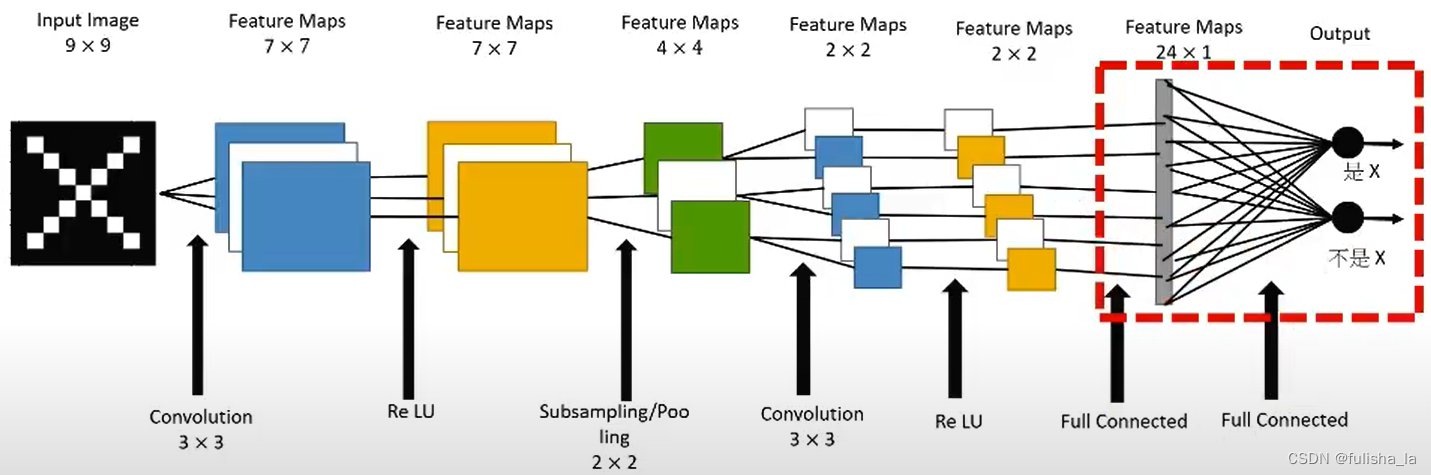
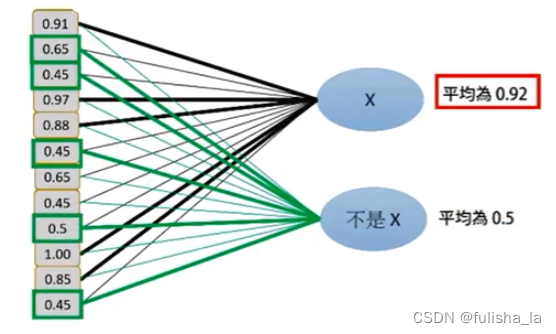
从传统的CNN网络架构中,我们可以看出CNN网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息,这个概率信息是一维的,即只能标识整个图片的类别,不能标识每个像素点的类别。
全连接层:
在 CNN 结构中,经多个卷积层和池化层后,连接着1个或1个以上的全连接层,全连接层中的每个神经元与其前一层的所有神经元进行全连接.全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息。最后全连接层输出进行分类。
1.2 VCG16(经典CNN网络架构之一)
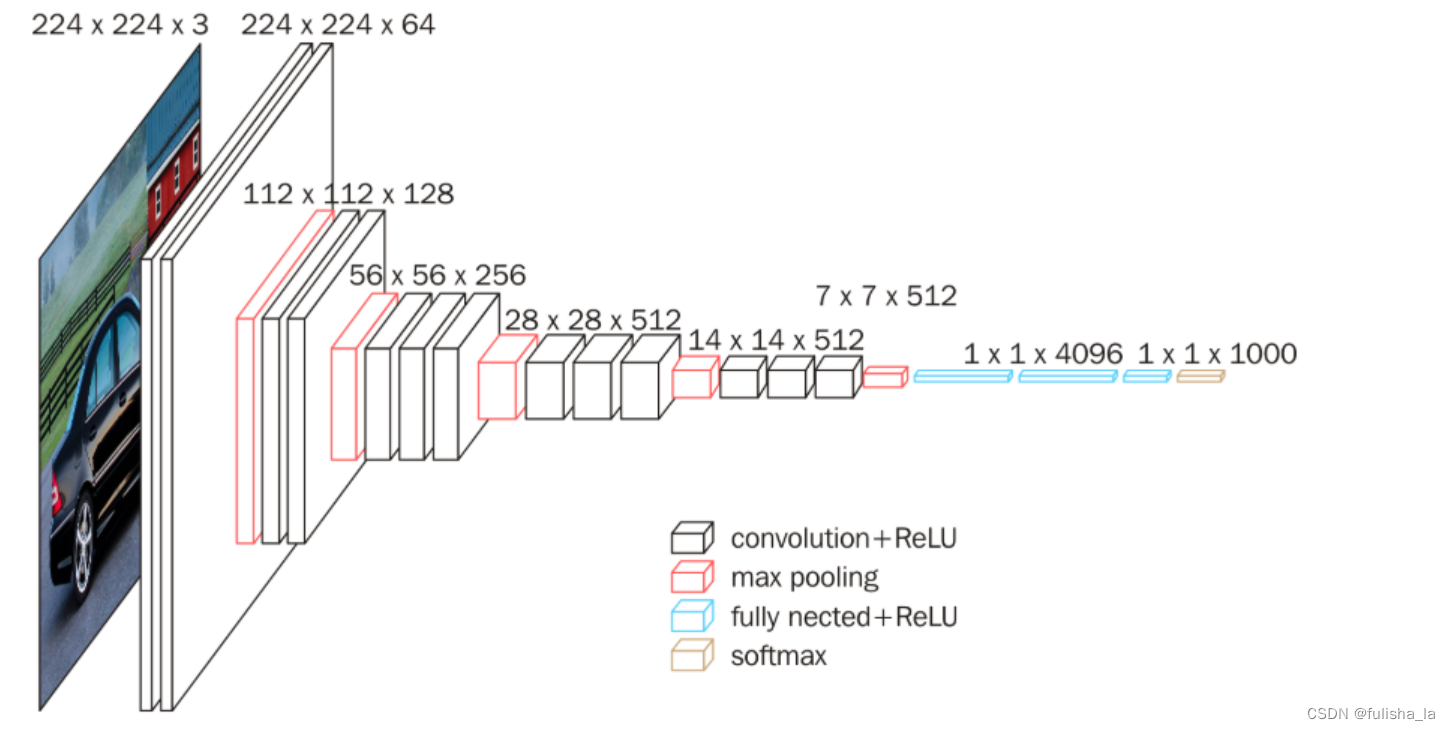 其中一共有13个卷积层;5个池化层和3个全连接层。其中
其中一共有13个卷积层;5个池化层和3个全连接层。其中
- 卷积层:全部都是3*3的卷积核+ReLU激活函数 提取图像局部特征
- 池化层:都是2x2的池化核和步长2,减小特征图的大小
- 全连接层:包含2个全连接层,每个全连接层包含4096个神经元,用于分类输出
- 输出层:一个大小为1000的全连接层,使用softmax激活函数,生成1000个类别的概率分布
从结构图可以看出,VCG有很明显的优缺点;其中
优点:
- VCG16网络是相对比较深的网络架构,随着卷积层的通道数增多,则提取的特征信息也越多,则可以提取更多的深层特征;
- 其次就是卷积核较小且卷积核都是一样的,有助于更好的提取特征信息;
缺点
- 网络参数过多,如果训练数据少就可能会发生过拟合,假设我们训练数据少,就要考虑用数据增强或则正则化策略去解决(数据增强是通过对训练数据进行一系列变换来生成新的数据样本,从而增加数据样本的数量和多样性;正则化是通过修改模型的损失函数,以鼓励模型保持简单的一种技术)
- 其次就是输入图像尺寸不能太小(因为经历了5个池化层,可能多次池化后会导致特征图太小了)
如下是一个代码的主要过程思路:
def __init__(self):
super(vgg16, self).__init__()
self.model = models.Sequential([ # 假设输入图像尺寸为224*224*3
#64个通道;3x3的卷积核,步长为1,padding=same填充,卷积两次,再经ReLU激活,输出的尺寸大小为224x224x64
Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'),
BatchNormalization(),
#最大池化层采用2*2 步长为2 输出的尺寸大小为 112x112x64
MaxPooling2D(),
#128个通道 3x3的卷积核,步长为1,padding=same填充,卷积两次,再经ReLU激活,输出的尺寸大小为112x112x128
Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'),
BatchNormalization(),
# 最大池化层采用2*2 步长为2 输出的尺寸大小为 56x56x128
MaxPooling2D(),
# 256个通道 3x3的卷积核,步长为1,padding=same填充,卷积三次,再经ReLU激活,输出的尺寸大小为56x56x256
Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'),
BatchNormalization(),
# 最大池化层采用2*2 步长为2 输出的尺寸大小为 28x28x256
MaxPooling2D(),
# 512个通道 3x3的卷积核,步长为1,padding=same填充,卷积三次,再经ReLU激活,输出的尺寸大小为28x28x512
Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'),
BatchNormalization(),
# 最大池化层采用2*2 步长为2 输出的尺寸大小为 14x14x512
MaxPooling2D(),
# 512个通道 3x3的卷积核,步长为1,padding=same填充,卷积三次,再经ReLU激活,输出的尺寸大小为14x14x512
Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'),
Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'),
BatchNormalization(),
# 最大池化层采用2*2 步长为2 输出的尺寸大小为 7x7x512
MaxPooling2D(),
#将数据拉平成向量,变成一维51277=25088
Flatten(),
# 经过两层1x1x4096,一层1x1x1000的全连接层(共三层),经ReLU激活
Dense(4096, activation='relu'),
Dense(4096, activation='relu'),
# 通过softmax输出1000个预测结果
Dense(10, activation='softmax')
])
2. 两种经典的网络架构
2.1 FCN网络
FCN论文链接:Fully Convolutional Networks for Semantic Segmentation
对比传统的CNN网络,只进行了图像层面上的分类,而FCN的提出,对输入的图像进行了像素级分类的全卷积网络(这是开创性的),从而解决了语义级别的图像分割问题。(语义分割:图像中的每个像素分配给其所属的语义类别,即为图像中的每个像素标记一个类别标签;旨在理解图像中的物体和场景的整体语义信息,而不仅仅是对不同物体的像素进行分割)
例如下图:


下面主要分享的是FCN在CNN基础上的主要改进:
- FCN提出了端到端,像素到像素卷积神经网络,搭建了一个全卷积神经网络,输入任意尺寸的图像,经过学习后输出相同尺寸的输出。
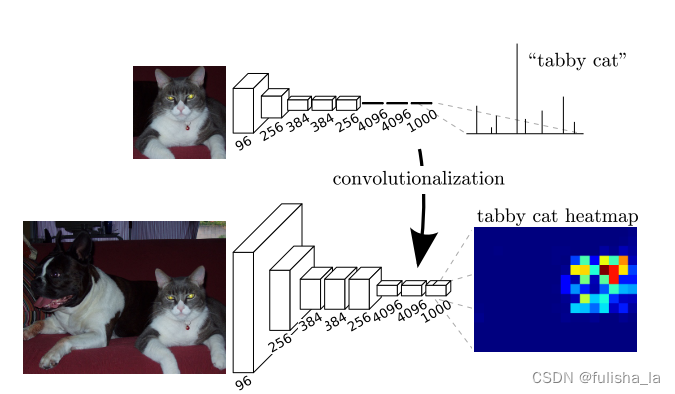
- FCN将全连接层转换为卷积层,则保留了原始空间的特征信息; 添加反卷积层进行向上采样,从而获得更接近真实图像的输出;添加了skip-connection结构(跳跃连接基本思想是在网络的某些层中,将输入直接连接到输出,以允许信息在不同层之间跳跃传递,可以提高了模型性能和训练速度);他的过程结构如下:
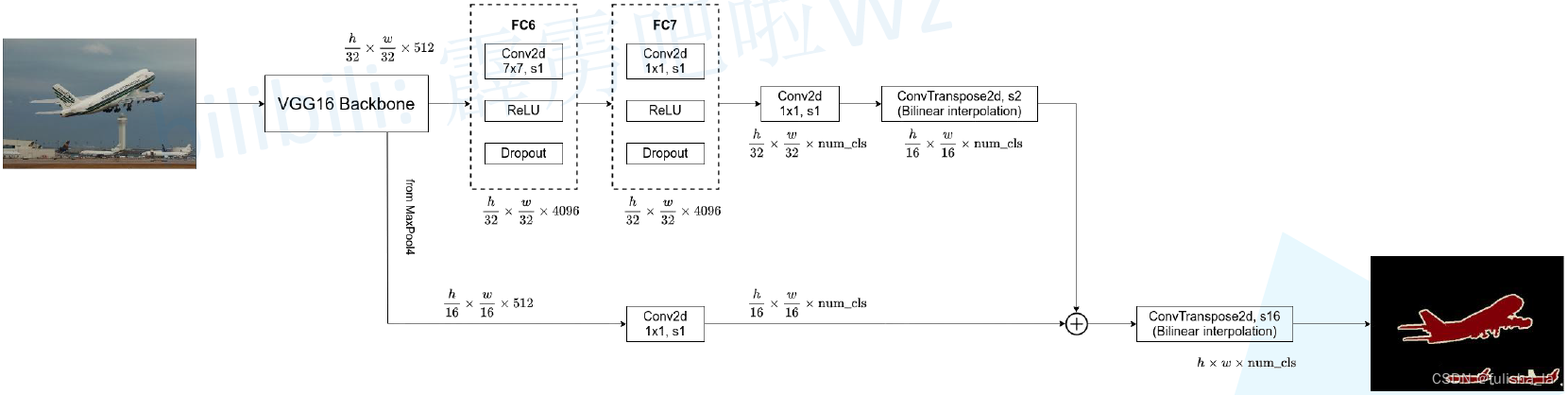
FCN网络在基于几个CNN网络架构下测试,发现基于VCG16网络表现出的性能是最好的,所以在FCN网络架构的pool5之前都是VCG16的架构。如下是具体的一个过程。从上面可以知道VCG16网络每个卷积核都是33且stride=1,padding=1; 池化都是22(直接对半)。
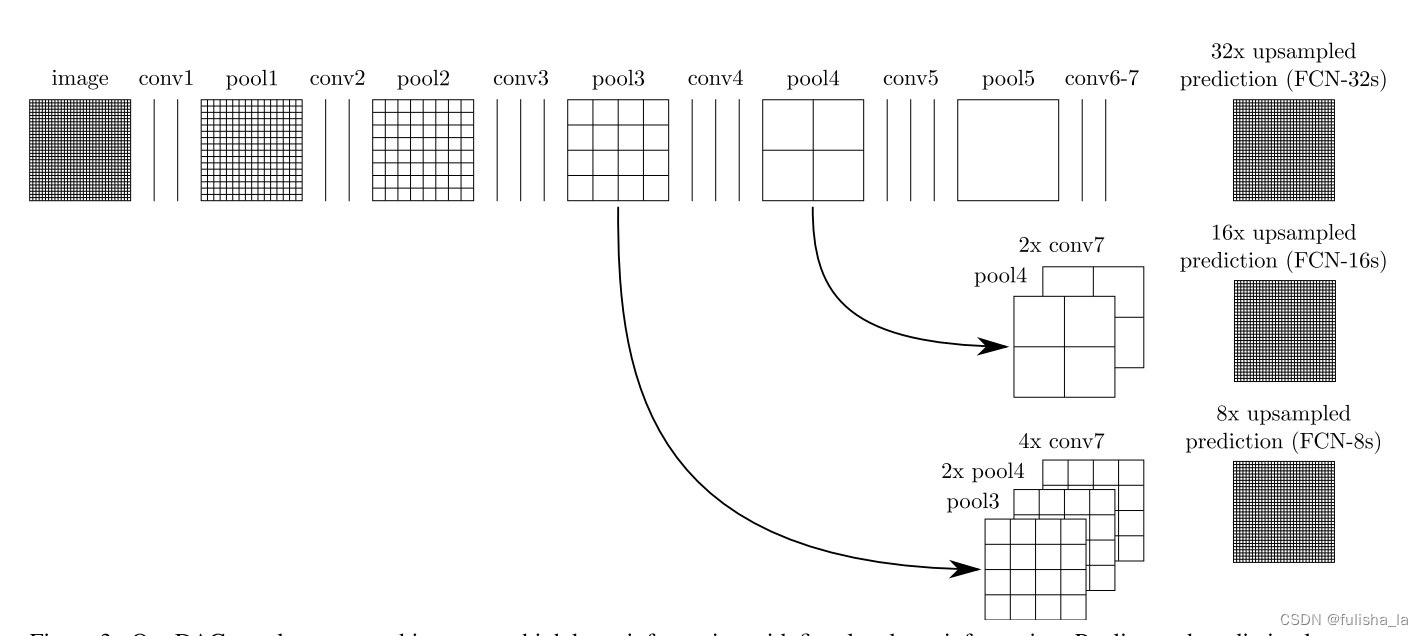
(1)第一阶段:
FCN32S:把全连接层转换为卷积层,且直接进行上采样32倍变为大图(无跳跃连接)

(2)FCN16S:第二阶段:使用跳跃连接将conv7+pool4进行特征融合提升精确性
(3)FCN8S:使用跳跃连接将conv7+pool4+pool3进行特征融合提升精确性
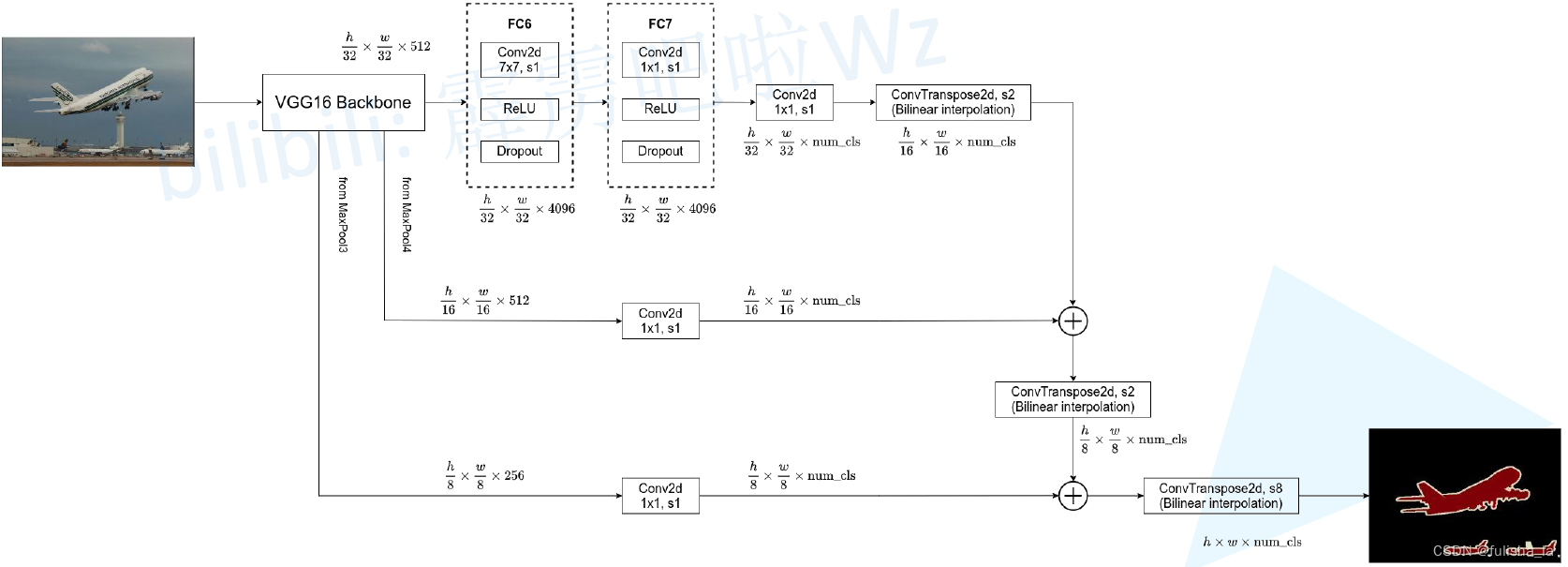
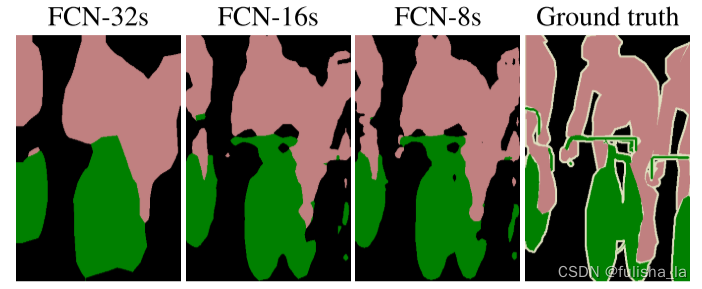
从FCN网络训练结果看出,他得到的结果不够精细,采样结果还是比较模糊和平滑,对一些细节的处理还不是很好。但是在这篇论文中提供的思路是值得我们去学习和扩展的。
2.2 U-Net网络
U-Net论文地址:Convolutional Networks for Biomedical Image Segmentation
U-Net提出的初衷和fcn一样,也是为了解决医学图像分割的问题,他主要得特点是:
- 端到端得网络,对称的网络结构(编码器-解码器结构)
- skip-connection(跳跃连接)
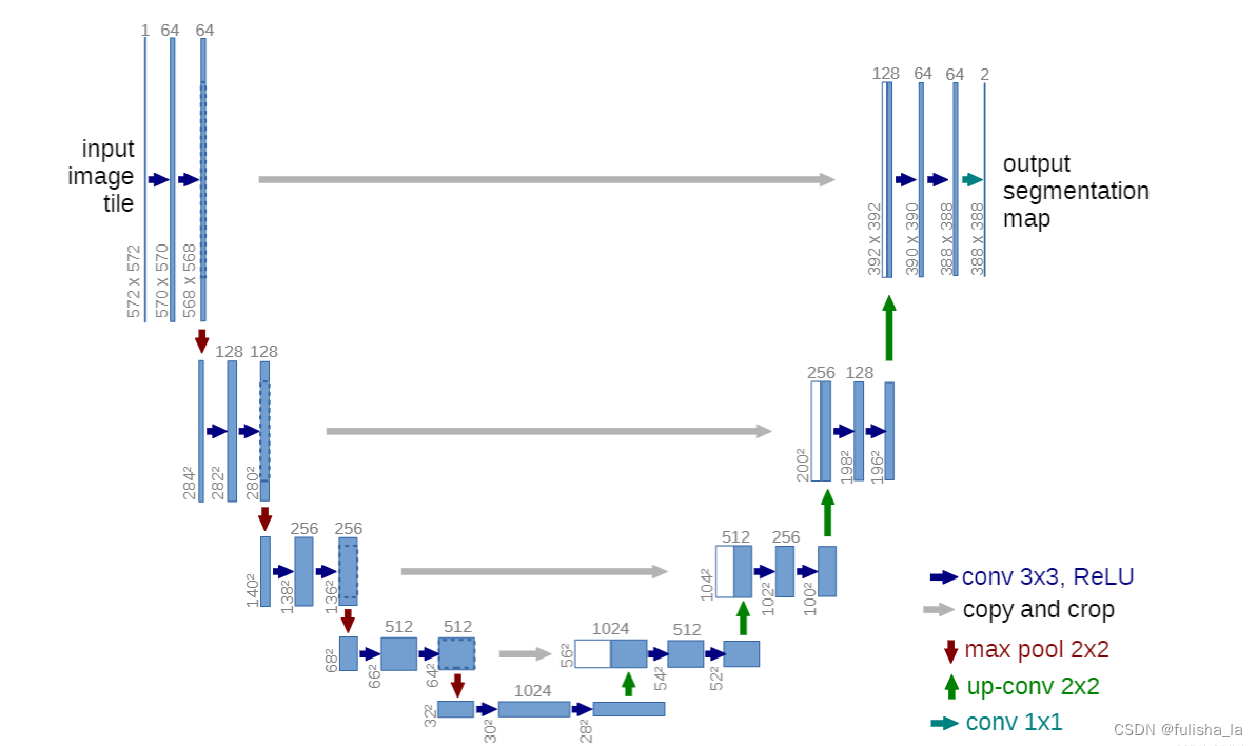 在U-Net网络结构中:
在U-Net网络结构中: -
- 左侧收缩路径(编码器Ecoder)功能是特征提取;主要过程是:卷积和最大池化。进行了4次像下采样,通道filters = [64, 128, 256, 512, 1024];。其中padding=0; strid为1;(没有进行边缘填充,每次卷积都会有损失,则会导致输入图像和输出图像分辨率并不一致。如果有填充,就会有误差存在,随着模型越深那受到padding的影响也越大)。
-
- 右侧扩展路径(解码器Decoder)功能是恢复特征图;主要过程是:卷积,上采样和skip-connection。
-
- skip-connection(挺重要的一个点,对比FCN)
主要功能是进行特征融合,图中灰色箭头表示。将浅层的位置信心和深层的语义信息进行concat操作(浅层特征有较高的分辨率和较少的语义信息;深层特征反之)。具体的思想过程举例:
假设特征图像尺寸: 256 ∗ 256 ∗ 64 256*256*64 256∗256∗64( 长 ∗ 宽 ∗ 通道数 长*宽*通道数 长∗宽∗通道数)和另一个特征图像: 256 ∗ 256 ∗ 32 256*256*32 256∗256∗32进行concat融合,这直接会得到一个 256 ∗ 256 ∗ 96 256*256*96 256∗256∗96的特征图
若特征图像尺寸: 256 ∗ 256 ∗ 64 256*256*64 256∗256∗64( 长 ∗ 宽 ∗ 通道数 长*宽*通道数 长∗宽∗通道数)和另一个特征图像: 240 ∗ 240 ∗ 32 240*240*32 240∗240∗32进行concat融合,他们图像大小不相等有两种方法:
a.对特征图 256 ∗ 256 ∗ 64 256*256*64 256∗256∗64进行裁剪变为 240 ∗ 240 ∗ 64 240*240*64 240∗240∗64,然后再和 240 ∗ 240 ∗ 32 240*240*32 240∗240∗32进行concat得到 240 ∗ 240 ∗ 96 240*240*96 240∗240∗96的特征图
b. 对特征图 256 ∗ 256 ∗ 32 256*256*32 256∗256∗32进行填充变为 256 ∗ 256 ∗ 32 256*256*32 256∗256∗32,然后再和 256 ∗ 256 ∗ 64 256*256*64 256∗256∗64进行concat得到 256 ∗ 256 ∗ 96 256*256*96 256∗256∗96的特征图在这一个结构中采用的是裁剪+拼接(copy+crop)
注::FCN的skip-connection是加操作,即像素点相加;U-Net网络是叠操作(copy+crop)
- skip-connection(挺重要的一个点,对比FCN)
3. FCNVMB(基于U-Net架构)
3.1 FCNVMB 主要思想
如下是FCNVMB网络结构图:
 数据集层级关系:
数据集层级关系: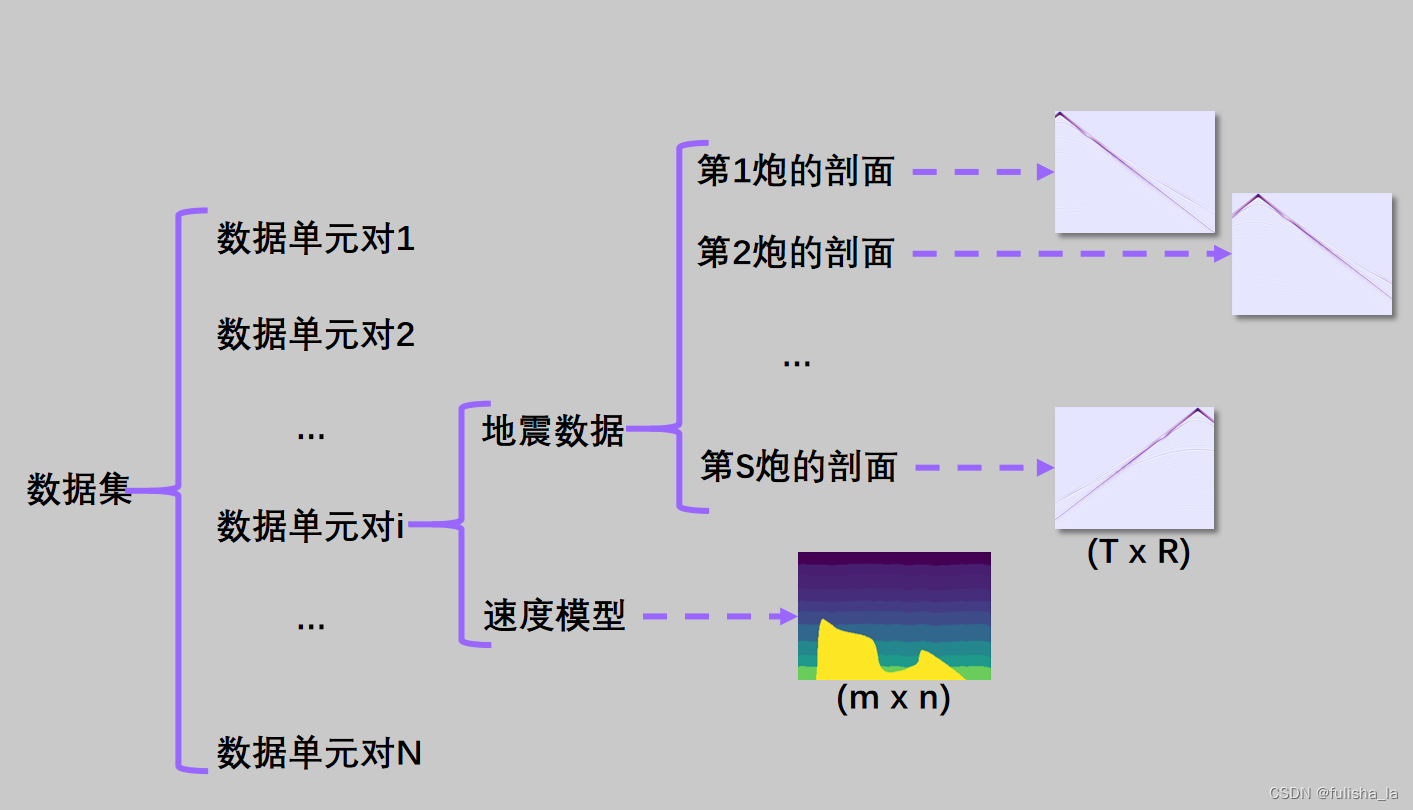
FCNVMB是基于U-Net网络架构,结合上面的U-Net网络结构,FCNVMB也是一个对称的编码器-解码器结构;中间也采用了卷积,池化,反卷积和skip-connection; 但在U-Net下有创新之处如下:
- 原始UNet模型是在图像处理领域提出的,通常用于处理RGB颜色通道表示的图像信息。在FCNVMB中主要处理地震数据,将不同位置生成的"炮集"作为输入的通道,进而输入通道的数量等于每个模型的源数量(每个炮集代表了来自相同模型的不同源位置的地震数据) —即输入数据发生了变化
- 原始UNet的输出和输入在相同的图像领域内,在FCNVMB中 中为了实现地震速度模型的构建,将数据从(x, t)域映射到(x, z)域,并同时构建速度模型;并将输出层的通道修改为 1。—输出数据发生了变化
如下图:
地震数据(x, t)域
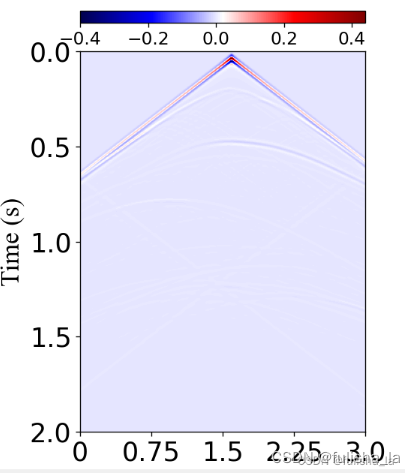
速度模型(x, z)域
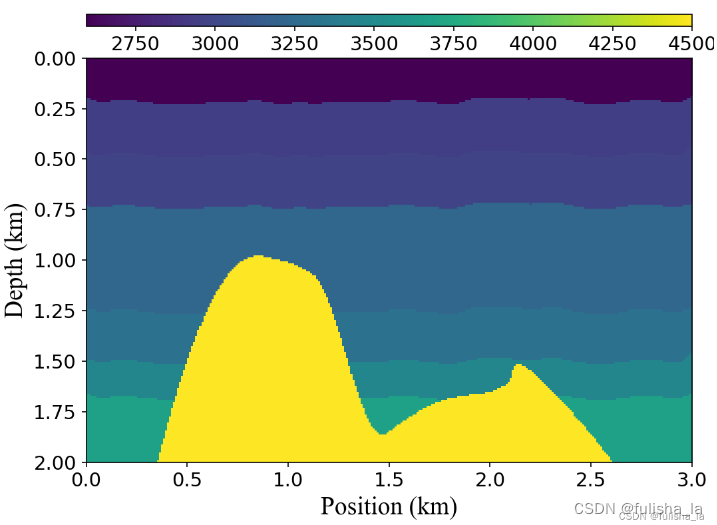
- FCNVMB是基于监督的深度全卷积神经网络,在这个速度模型的构建过程中,论文采用了两种数据集一类是用声波方程作为正演模型来合成的模拟数据集;一类是采用Seg盐模拟数据对;将这些数据对 一部分用于训练;一部分用于测试。所以这篇论文我理解的大致思路就是:训练集数据集利用FCNVMB网络进行训练,学习地震数据和速度模型之间的一种映射关系,不断优化参数,训练好后我们再用测试集数据去进行预测。
监督网络:用大量的有标签的数据训练来训练模型,模型最终学习到输入和输出标签之间的相关性。监督学习主要是学习一种映射关系;
无监督网络:不依赖任何标签值(用无标签的数据训练),通过对数据内在特征的挖掘,找到样本间的关联。比如聚类算法;
- FCNVMB代码主要的理解
class FCNVMB(nn.Module):
def __init__(self, n_classes, in_channels, is_deconv, is_batchnorm):
'''
Network architecture of FCNVMB
:param n_classes: Number of channels of output (any single decoder) 输出通道数
:param in_channels: Number of channels of network input 输入通道树
:param is_deconv: Whether to use deconvolution 是否使用反卷积
:param is_batchnorm: Whether to use BN 是否使用BN
'''
super(FCNVMB, self).__init__()
self.is_deconv = is_deconv
self.in_channels = in_channels
self.is_batchnorm = is_batchnorm
self.n_classes = n_classes
filters = [64, 128, 256, 512, 1024] #表示网络的通道数,这些整数用于定义U-Net模型的不同层级的通道数
self.down1 = unetDown(self.in_channels, filters[0], self.is_batchnorm)
self.down2 = unetDown(filters[0], filters[1], self.is_batchnorm)
self.down3 = unetDown(filters[1], filters[2], self.is_batchnorm)
self.down4 = unetDown(filters[2], filters[3], self.is_batchnorm)
self.center = unetConv2(filters[3], filters[4], self.is_batchnorm)
self.up4 = unetUp(filters[4], filters[3], self.is_deconv)
self.up3 = unetUp(filters[3], filters[2], self.is_deconv)
self.up2 = unetUp(filters[2], filters[1], self.is_deconv)
self.up1 = unetUp(filters[1], filters[0], self.is_deconv)
self.final = nn.Conv2d(filters[0], self.n_classes, 1)
def forward(self, inputs, label_dsp_dim):
'''
:param inputs: Input Image
:param label_dsp_dim: Size of the network output image (velocity model size)
:return:
'''
down1 = self.down1(inputs)
down2 = self.down2(down1)
down3 = self.down3(down2)
down4 = self.down4(down3)
center = self.center(down4)
up4 = self.up4(down4, center)
up3 = self.up3(down3, up4)
up2 = self.up2(down2, up3)
up1 = self.up1(down1, up2)
up1 = up1[:, :, 1:1 + label_dsp_dim[0], 1:1 + label_dsp_dim[1]].contiguous()
return self.final(up1)
(1) 其中unetDown函数包含上采样过程:经过卷积和池化。
class unetDown(nn.Module):
def __init__(self, in_size, out_size, is_batchnorm):
'''
Downsampling Unit
[Affiliated with FCNVMB]
:param in_size: Number of channels of input
:param out_size: Number of channels of output
:param is_batchnorm: Whether to use BN
'''
super(unetDown, self).__init__()
self.conv = unetConv2(in_size, out_size, is_batchnorm)
self.down = nn.MaxPool2d(2, 2, ceil_mode=True)
def forward(self, inputs):
'''
:param inputs: Input Image
:return:
'''
outputs = self.conv(inputs)
outputs = self.down(outputs)
return outputs
(2) 其中UnetCenter部分
主要是增加了通道数,图像分辨率不变
(3) 其中unetUp函数:提供了两种方式的上采样,ConvTranspose2d:创建反卷积层进行上采样(U-Net使用的则是这一种);UpsamplingBilinear2d:传统的双线性插值上采样(FCN使用的是这一种); 另一个是skip-connection:是采用U-Net网络结构中的叠操作(copy+crop),并且是填充大小。
class unetUp(nn.Module):
def __init__(self, in_size, out_size, is_deconv):
'''
Upsampling Unit
[Affiliated with FCNVMB]
:param in_size: Number of channels of input
:param out_size: Number of channels of output
:param is_deconv: Whether to use deconvolution
'''
super(unetUp, self).__init__()
self.conv = unetConv2(in_size, out_size, True)
# Transposed convolution
if is_deconv:
self.up = nn.ConvTranspose2d(in_size, out_size, kernel_size=2, stride=2)
else:
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, inputs1, inputs2):
'''
:param inputs1: Layer of the selected coding area via skip connection
:param inputs2: Current network layer based on network flows
:return:
'''
outputs2 = self.up(inputs2)
offset1 = (outputs2.size()[2] - inputs1.size()[2])
offset2 = (outputs2.size()[3] - inputs1.size()[3])
padding = [offset2 // 2, (offset2 + 1) // 2, offset1 // 2, (offset1 + 1) // 2]
# Skip and concatenate
outputs1 = F.pad(inputs1, padding)
return self.conv(torch.cat([outputs1, outputs2], 1))
3.2 FCNVMB 提供的其他思想
(1)VMB的局限1:训练数据集的选择;FCNVMB网络结构很依赖选择的数据集,直接使用经过训练的网络来测试复杂(例如SEG盐模型)或真实模型会很困难。如实验中对数据进行不加盐的预测(使用 10 个不含盐的训练样本进行训练),用现有的FCNVMB和FWI去预测,其预测结果如下,VMB的性能结构并没有FWI好
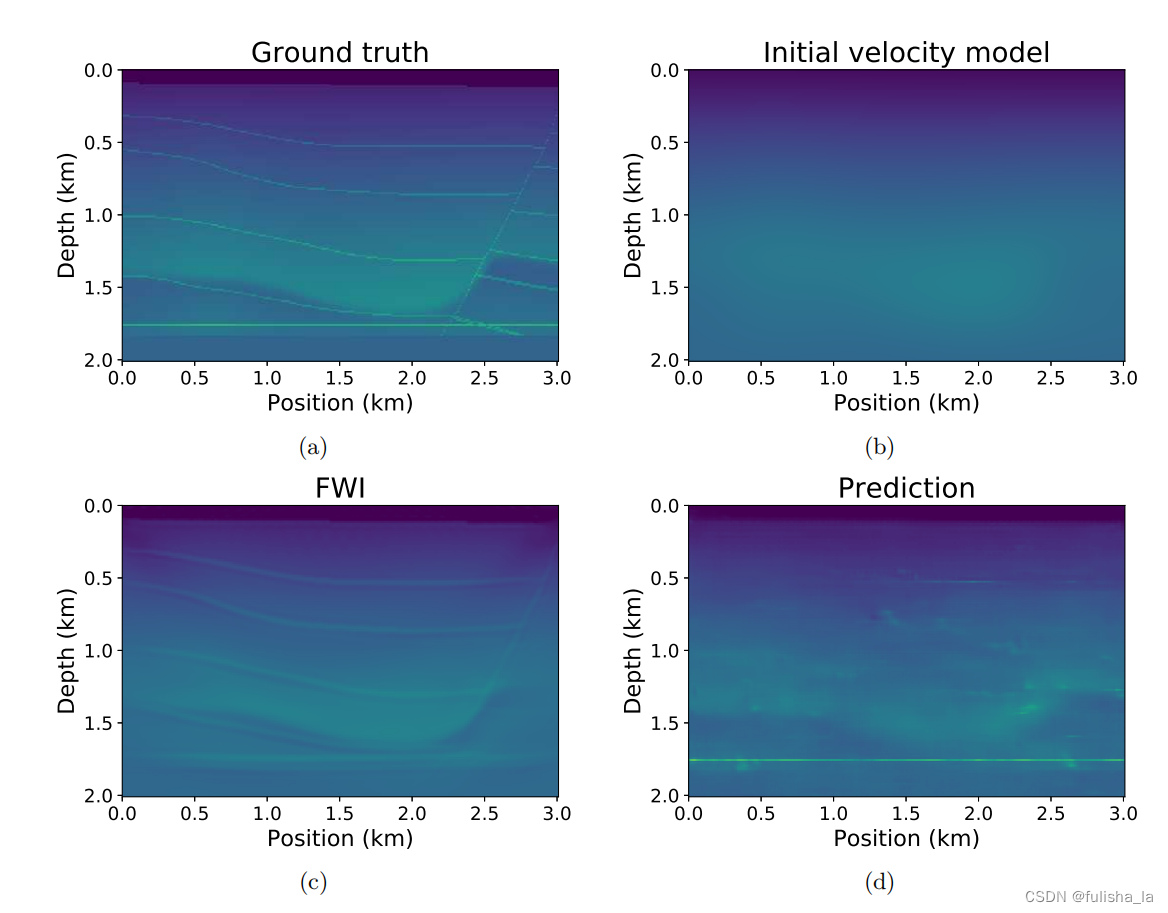
结合这个问题,一方面我们可以增强数据,增加数据的多样性(对现有数据进行变换、旋转、缩放),另一方面是引入迁移学习,迁移学习主要思想:将在一个任务上学到的知识或模型应用于解决另一个相关任务(尤其是新任务的数据集相对较小或缺乏标注时),则可以使用预训练网络作为初始化网络,目的是更有效地显示输入和输出之间的非线性映射,而不仅仅是让机器记住数据集的特征。
(2) 低频信息的重要性。
低频信息的在论文中提到当低频信息被移除时(利用技术滤除低频信息进行实验),速度模型的结构边界变得不太清晰,背景速度层次略显模糊。这表明低频信息对于提高速度模型预测的精度和清晰度非常重要。VMB的局限2:但是如何获取低频信息是一个难点。(为什么低频信息回很重要呢,多少hz才算低频?)
(3)作者在最后提出了另一个思想即利用生成对抗网络(GAN): 生成对抗网络包含一个生成模型和一个判别模型(一种基于有限开放数据集的半监督学习网络)其中
- 生成器:其任务是尽生成模仿训练集中的真实样本;
- 判别器:判别模型一般情况下是一个二分类器,目标是判别输入是真实数据还是生成的样本。
- 博弈过程:训练中,生成器和判别器相互竞争。生成器的目标是生成能够欺骗判别器的伪造数据,而判别器的目标是尽量准确地识别伪造数据。这个博弈过程推动了生成器和判别器不断完善
- 训练过程: 训练过程包括多轮的生成器和判别器之间的竞争。通过这个过程,生成器逐渐学习生成逼真的数据,而判别器逐渐学习变得更善于区分真实和伪造数据。
目前是CNN和GAN进行结合的网络即DCGAN 网络,具体的网络结构还未去了解过。
(4)作者论文提到以后可能得一个研究方向是去揭示传统反演方法与特定网络之间的潜在关系。我觉得挺有趣的,就像本论文的VMB,他其实就是在传统经典的网络架构上进行了改进,将他巧妙的应用到地震反演中并修改了输入输出。
![buuctf_练[CSCCTF 2019 Qual]FlaskLight](https://img-blog.csdnimg.cn/img_convert/db29190ba10110be7c884fcb85b13bc4.png)

![[SQL开发笔记]UPDATE 语句:更新表中的记录](https://img-blog.csdnimg.cn/ba6f4824fbc5486c91701db622da136c.png)